Adaboost原理推导
Adaptive Boosting是一种迭代算法。每轮迭代中会在训练集上产生一个新的学习器,然后使用该学习器对所有样本进行预测,以评估每个样本的重要性(Informative)。换句话来讲就是,算法会为每个样本赋予一个权重,每次用训练好的学习器标注/预测各个样本,如果某个样本点被预测的越正确,则将其权重降低;否则提高样本的权重。权重越高的样本在下一个迭代训练中所占的比重就越大,也就是说越难区分的样本在训练过程中会变得越重要;
先记住这个图:


整个迭代过程直到错误率足够小或者达到一定的迭代次数为止。
分类
首先看一下原来的论文上的伪代码:

Adaboost算法将基分类器的线性组合作为强分类器,同时给分类误差率较小的基本分类器以大的权重值,给分类误差率较大的基分类器以小的权重值;构建的线性组合为:
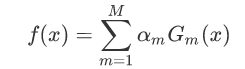
最终分类器是在线性组合的基础上进行Sign函数转换:
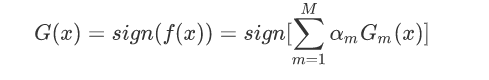
因为G(x)是经过sign化的所以得出的值是-1或1,这时候损失函数自然就是那些被分类错误的样本平均个数了:
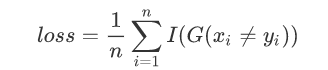
对于这样一个损失函数难以进行求导,所以这里使用下面这个函数代替:
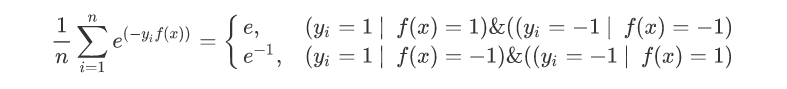
In [1]: import numpy as np
In [2]: np.exp(1)Out[2]: 2.718281828459045
In [3]: 1/np.exp(1)Out[3]: 0.36787944117144233
所以损失函数可以改变为:
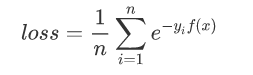
根据刚开始的图示我们可以得出:
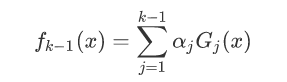
由于这里每个模型都是上一个模型得来的:
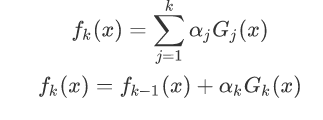
将fk(x)带入到损失函数中:
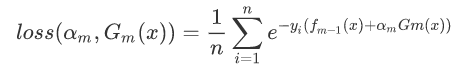
剩下的就是走机器学习的老套路求导求值,这时候就先构造参数:
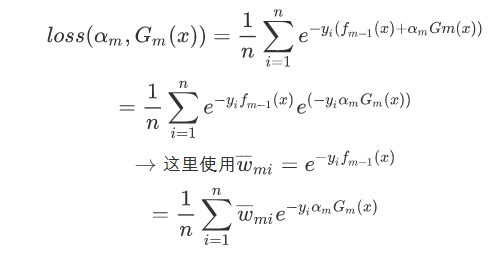
使下列公式达到最小值的αm和Gm就是AdaBoost算法的最终求解值。
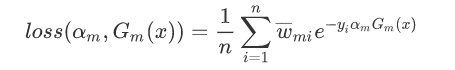
G这个分类器在训练的过程中,是为了让误差率最小,所以可以认为G越小其实就是误差率越小。
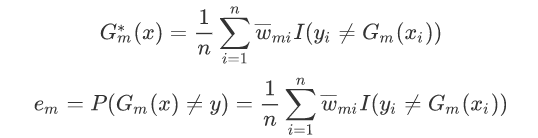
对于αm而言,通过求导然后令导数为零,可以得到公式(log对象可以以e为底也可以以2为底):
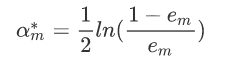
举个栗子
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
x是特征,y是标签,令权值分布
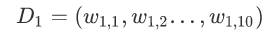
在这里:
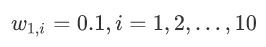
在权值分布为D1的训练数据中,当阀值为2.5的时候,误差率最低,所以这时候的基本分类器为:
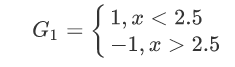
G1(x)在训练数据集上的误差率:

计算模型G1的系数:

更新数据集的权值分布:
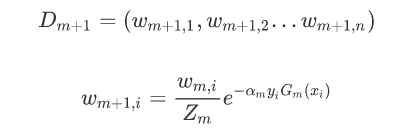
注意这里的Zm是为了归一化:

更新后的结果:
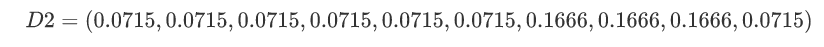
D2中分类正确的样本权值减小,错误分类的样本权值提高。
然后利用D2在训练样本中寻找误差率最低的基本分类器,在继续进行迭代。
......(这里再循环两次)
得到:

所以将新的函数f(x),放入sign()分类器中,从而输出结果:
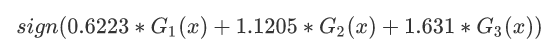
分类器sign(f3(x))在训练数据集上有0个误分类点;结束循环。

而在实际应用中我们还会添加一个缩减系数:
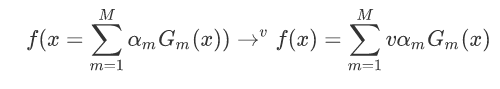
优点:
可以处理连续值和离散值;模型的鲁棒性比较强;解释强,结构简单。
缺点:
对异常样本敏感,异常样本可能会在迭代过程中获得较高的权重值,最终影响模型效果
实现代码:
import pandas as pd
import numpy as np
import math
df = pd.DataFrame([[0,1],[1,1],[2,1],[3,-1],[4,-1],
[5,-1],[6,1],[7,1],[8,1],[9,-1]])
w =np.ones(df.shape[0])/df.shape[0] #初始化权值分布
from sklearn.tree import DecisionTreeClassifier
X = df.iloc[:,[0]]
Y = df.iloc[:,[-1]]
model = DecisionTreeClassifier(max_depth=1).fit(X,Y,sample_weight=w) ##训练第1个模型
model1 = model
# print(w)
# print(w * model.predict(X))
# print(Y.values.T[0])
# print(model.predict(X) != Y.values.T[0])
e = sum(w*(model.predict(X) != Y.values.T[0])) #误差率
# print(e) #0.30000000000000004
a = 1/2*math.log((1-e)/e) #学习器系数
# print(a)
a1 = a
z = sum(w*np.exp(-1*a*Y.values.T[0]*model.predict(X))) #规范因子
w = w/z*np.exp(-1*a*Y.values.T[0]*model.predict(X))#更新权值分布
model = DecisionTreeClassifier(max_depth=1).fit(X,Y,sample_weight=w)##训练第2个模型
model2 = model
e = sum(w*(model.predict(X) != Y.values.T[0]))
a = 1/2*math.log((1-e)/e)
a2 = a
z = sum(w*np.exp(-1*a*Y.values.T[0]*model.predict(X)))
w = w/z*np.exp(-1*a*Y.values.T[0]*model.predict(X))
model = DecisionTreeClassifier(max_depth=1).fit(X,Y,sample_weight=w)##训练第3个模型
model3 = model
e = sum(w*(model.predict(X) != Y.values.T[0]))
a = 1/2*math.log((1-e)/e)
a3 = a
y_ = np.sign(a1*model1.predict(X)+a2*model2.predict(X)+a3*model3.predict(X))##模型组合
print(y_)
最后实在不懂boosting是怎么回事的,就看一下下面的图:
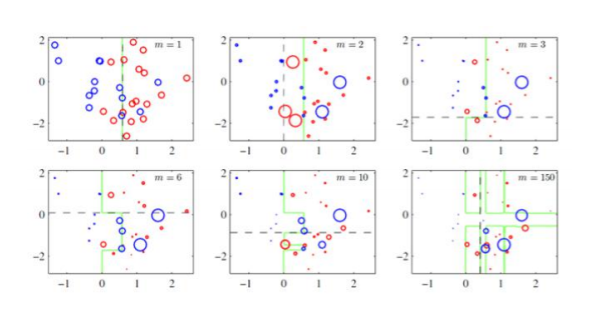
Adaboost原理推导的更多相关文章
- 集成学习之Boosting —— AdaBoost原理
集成学习大致可分为两大类:Bagging和Boosting.Bagging一般使用强学习器,其个体学习器之间不存在强依赖关系,容易并行.Boosting则使用弱分类器,其个体学习器之间存在强依赖关系, ...
- AdaBoost原理详解
写一点自己理解的AdaBoost,然后再贴上面试过程中被问到的相关问题.按照以下目录展开. 当然,也可以去我的博客上看 Boosting提升算法 AdaBoost 原理理解 实例 算法流程 公式推导 ...
- Adaboost原理及目标检测中的应用
Adaboost原理及目标检测中的应用 whowhoha@outlook.com Adaboost原理 Adaboost(AdaptiveBoosting)是一种迭代算法,通过对训练集不断训练弱分类器 ...
- 机器学习之AdaBoost原理与代码实现
AdaBoost原理与代码实现 本文系作者原创,转载请注明出处: https://www.cnblogs.com/further-further-further/p/9642899.html 基本思路 ...
- 机器学习-分类器-Adaboost原理
Adaboost原理 Adaboost(AdaptiveBoosting)是一种迭代算法,通过对训练集不断训练弱分类器,然后把这些弱分类器集合起来,构成强分类器.adaboost算法训练的过程中,初始 ...
- 降维算法----PCA原理推导
1.从几何的角度去理解PCA降维 以平面坐标系为例,点的坐标是怎么来的? 图1 ...
- PCA主成分分析算法的数学原理推导
PCA(Principal Component Analysis)主成分分析法的数学原理推导1.主成分分析法PCA的特点与作用如下:(1)是一种非监督学习的机器学习算法(2)主要用于数据的降维(3)通 ...
- Adaboost原理及相关推导
提升思想 一个概念如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么,这个概率是强可学习的.一个概念如果存在一个多项式的学习算法能够学习它,并且学习的正确率仅比随机猜测略好,那么,这个概念是 ...
- AdaBoost原理,算法实现
前言: 当做重要决定时,大家可能综合考虑多个专家而不是一个人的意见.机器学习处理问题也是如此,这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式,前几天看了一个称作adaboost方法的介绍 ...
随机推荐
- Codility--- Triangle
Task description A zero-indexed array A consisting of N integers is given. A triplet (P, Q, R) is tr ...
- mvc中Scripts.Render的用法
第一次接触新的东西,都会很陌生,但是时间久了就熟悉了变简单了. 视图文件中使用Scripts.Render()输出脚本包,Styles.Render()输出样式包 上面两张图是我所做项目里的,放上面会 ...
- webapi使用autofac
注意:您的项目中如果使用的是webapi2,此处必须为webapi2而不是webapi,否则在运行时将出现“重写成员“Autofac.Integration.WebApi.AutofacWebApiD ...
- LaTeX 中插入GIF图片
参见博文:liam.page 和 voidcn 前提条件 安装 ImageMagick 软件 (因为要把 gif 图片转换成 png 序列),使用它的命令行工具 convert.exe 命令行下把 g ...
- 微信jssdk支付坑
1.使用easywechat开发的时候,由于没有注意,配置文件中默认的请求地址是 https://api.weixin.qq.com/结果调试了半天,一直报错“40066” 这也是怪自己粗心,结果去分 ...
- 2019.ccpc女生赛-wfinal总结
2019ccpc女生赛离它结束有四天了,在这个期间我想了很多,想了想还是决定写这个总结.作为这个队伍唯一的一名大一队员,我很庆幸,能跟着两个学姐一起打比赛,计爱玲师姐,即将工作,张莹俐学姐.这估计都是 ...
- Failed to start Docker Application Container Engine.
[root@dockertest ~]# systemctl status docker.service● docker.service - Docker Application Container ...
- shell遍历文件
取文件每行的数据,需要按列取 可以 sed 加管道 使用 awk 取列 platform="list.txt" line=`grep -vc '^$' $platform` ; ...
- MAC iterm2 常用快捷键大全
标签 新建标签:command + t 关闭标签:command + w 切换标签:command + 数字 / command + 左右方向键 切换全屏:command + enter 查找:com ...
- BFS(三):双向广度优先搜索
所谓双向广度搜索指的是搜索沿两个方向同时进行:(1)正向搜索:从初始结点向目标结点方向搜索:(2)逆向搜索:从目标结点向初始结点方向搜索:当两个方向的搜索生成同一子结点时终止此搜索过程. 广度双向搜索 ...