使用Python的selenium库制作脚本,支持后台运行
本文介绍如何使用Python的selenium库制作脚本。
概念:
Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,可以模拟人工手动进行操作浏览器。
使用准备:
第一步:安装selenium
pip install Selenium 首先点击Terminal,等价于cmd命令行,输入命令,会自动下载selenium库。
首先点击Terminal,等价于cmd命令行,输入命令,会自动下载selenium库。
补充:对于Python第三方库,会有安装慢,容易失败,可以使用国内的清华源安装一些库,最后一个是库名,使用的是国内的清华源(可以百度)
清华大学开源软件镜像站,致力于为国内和校内用户提供高质量的开源软件镜像、Linux 镜像源服务,帮助用户更方便地获取开源软件。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 库名第二步:安装浏览器驱动
先查看自己Chrome的版本信息
版本是96.0.4664.45。
所以下载对应的版本即可,如果没有对应的版本,就向上找,找比自己版本小的驱动版本。
小伙伴可以自己看看自己应该下载哪个版本。
64的可以下载32位的压缩包。
Chrome驱动:下载驱动
下载完将压缩包解压,将exe文件放到自己的Python解释器下即可,
如果找不到自己的Python解释器位置,可以运行一个Python程序,运行结果的显示框第一行就是Python解释器的位置。
找到下面路径,将驱动文件粘贴进去即可。
准备工作做完了
第三步:编写代码
导入库:
#因为驱动文件是Chrome,所以导入Chrome
from selenium.webdriver import Chrome
#导入time库,是因为有时候网络可能不好,网页加载延迟,
#导致命令执行到了而找不到页面元素从而报错,等小伙伴上手操作会有体验
import time
#用于处理一些网页获得的字符串
import re
#导入By,用于获取元素
from selenium.webdriver.common.by import By创建浏览器:
#创建浏览器对象
web = Chrome()
#程序睡眠1s
time.sleep(1)
#打开这个网址
web.get('http://www.baidu.com')
#输出页面的title
print(web.title)获取元素: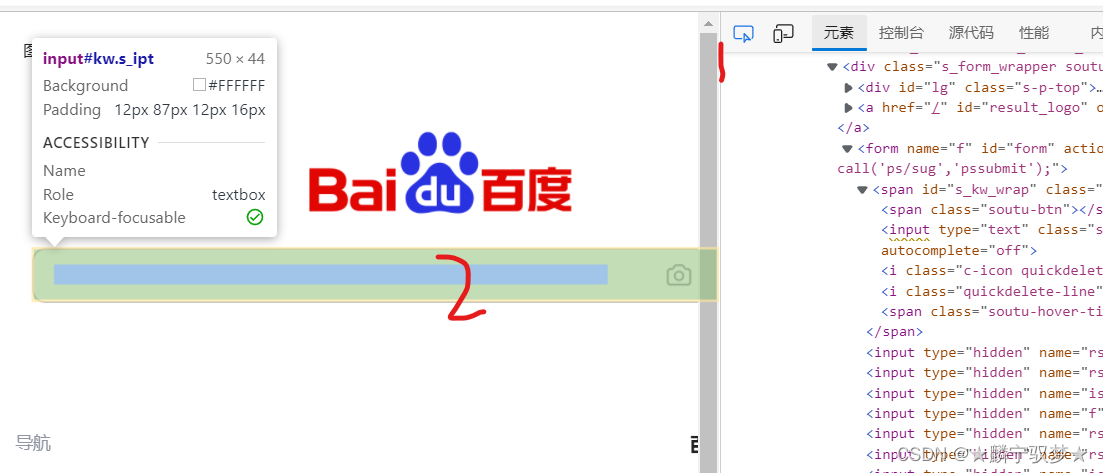
右键点击:
复制,复制完整的XPath:
这个地方少一张图,这一步是复制XPATH,或许还有个full XPATH,不要弄混了,是XPATH
然后将粘贴到程序即可:
在这里我只解释下面用到的方法。
| 方法 | 作用 |
|---|---|
| send_keys() | 向一个元素中写入字符串 |
| click() | 点击某个元素 |
| text | 获取标签的文本 |
| title | 获取页面的标题 |
#通过By.XPATH获取元素,
print(web.title)
text = web.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[3]/a[1]').text
print(text)
web.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys("Python")
time.sleep(2)
web.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div[2]/div/form/span[2]/input').click()如果有以下错误,找不到元素,在确定没有写错的情况下,可以添加。
原因是程序运行较快,网页没有加载出来,导致程序找不到这个元素。
让程序睡眠一会即可。
tim.sleep(2)错误截图:
有些网站具有反爬机制。
如果想要后台运行,可以将创建浏览器与包改为下面
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from selenium.webdriver.common.by import By
chrome_options = Options()
chrome_options.add_argument('--headless')
web = webdriver.Chrome(options=chrome_options)
大家可以练一练,提示:可以做刷题脚本。
使用Python的selenium库制作脚本,支持后台运行的更多相关文章
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
- 安装python的selenium库和驱动
对于使用selenium来进行python爬虫操作可以简化好多操作,它实际上的运行就是通过打开一个浏览器来一步一步的按照你的代码来执行 如果安装过python编译器后应该pip工具也是有的,验证pyt ...
- Python爬虫-- selenium库
selenium库 selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(S ...
- python利用selenium库识别点触验证码
利用selenium库和超级鹰识别点触验证码(学习于静谧大大的书,想自己整理一下思路) 一.超级鹰注册:超级鹰入口 1.首先注册一个超级鹰账号,然后在超级鹰免费测试地方可以关注公众号,领取1000积分 ...
- 浅谈python中selenium库调动webdriver驱动浏览器的实现原理
最近学web自动化时用到selenium库,感觉很神奇,遂琢磨了一下,写了点心得. 当我们输入以下三行代码并执行时,会发现新打开了一个浏览器窗口并访问了百度首页,然而这是怎么做到的呢? from se ...
- 解决python 导入selenium 库后自动化运行成功但是报错问题
本章节开始进入自动化的基础教学了,首先我们要对我们的工具有一定的熟练使用程度,做自动化常用的工具一个是搭建 RobotFramework自动化框架,另外一个便是我们最常用的python 工作原理是比较 ...
- Python:利用 selenium 库抓取动态网页示例
前言 在抓取常规的静态网页时,我们直接请求对应的 url 就可以获取到完整的 HTML 页面,但是对于动态页面,网页显示的内容往往是通过 ajax 动态去生成的,所以如果是用 urllib.reque ...
- 使用python的selenium库刷超星网课
网课很多看不完呀 所以动手做了一个基础的自动答题和下一节的程序 用到了python 3 selenium Chrome 如何自动化Chrome?https://www.cnblogs.com/eter ...
- Python 中 selenium 库
目录 selenium 基础语法 一. 环境配置 1. 安装环境 2. 配置参数 3. 常用参数搭配 4. 分浏览器启动 二. 基本语法 1. 元素定位 2. 控制浏览器操作 3. 操作元素的方法 3 ...
随机推荐
- Java泛型知识总结
泛型 前言 在没有泛型之前,程序员必须使用Object编写适用于多种类型的代码.很繁琐,也不安全. 泛型的引入使Java有了一个很强的类型系统,允许设计者详细地描述变量和方法的类型要如何变化. 在普通 ...
- pycharm相关介绍
一.settings设置 1.搜font 设置字体 2.Keymap------快捷键 二.常用快捷键 1.Ctrl + Enter:在下方新建行但不移动光标: 2.Shift + Enter:在 ...
- Linux系列之linux访问windows文件
Linux永久挂载windows共享文件 Linux系统必须安装samba-client Linux服务器必须能访问到Windows的共享文件服务的(445端口) 1.Windows共享文件 2.测试 ...
- vue海康视频播放组件
海康视频插件web文档 渲染组件后,调用initPlugin函数,传入一个code数组 <template> <div :title="name" :id=&qu ...
- 合宙AIR105(二): 时钟设置和延迟函数
目录 合宙AIR105(一): Keil MDK开发环境, DAP-Link 烧录和调试 合宙AIR105(二): 时钟设置和延迟函数 Air105 的时钟 高频振荡源 芯片支持使用内部振荡源, 或使 ...
- 【Redis】Redis Cluster-集群故障转移
集群故障转移 节点下线 在集群定时任务clusterCron中,会遍历集群中的节点,对每个节点进行检查,判断节点是否下线.与节点下线相关的状态有两个,分别为CLUSTER_NODE_PFAIL和CLU ...
- SAP setting and releasing locks
REPORT demo_transaction_enqueue MESSAGE-ID sabapdocu. TABLES sflight. DATA text(8) TYPE c. DATA ok_c ...
- salt stack安装与使用
SaltStack除了传统的C/S架构外,其实还有Masterless架构,如果采用Masterless架构,我不需要单独安装一台SaltStack Master机器,只需要在每台机器上安装Minio ...
- python小题目练习(四)
题目:JAVA和Python实现冒泡排序 实现代码: # Java实现对数组中的数字进行冒泡排序scoreList = [98, 87, 89, 90, 69, 50]temp = 0for i in ...
- 一文详解|Go 分布式链路追踪实现原理
在分布式.微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查.性能优化带来新的挑战.分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施.本文将 ...