构建第一个模型:KNN算法(Iris_dataset)
利用鸢尾花数据集完成一个简单的机器学习应用~万丈高楼平地起,虽然很基础,但是还是跟着书敲了一遍代码。
一、模型构建流程
1、获取数据
- 本次实验的Iris数据集来自skicit-learn的datasets模块
from sklearn.datasets import load_iris
iris_dataset = load_iris()
查看一下数据:
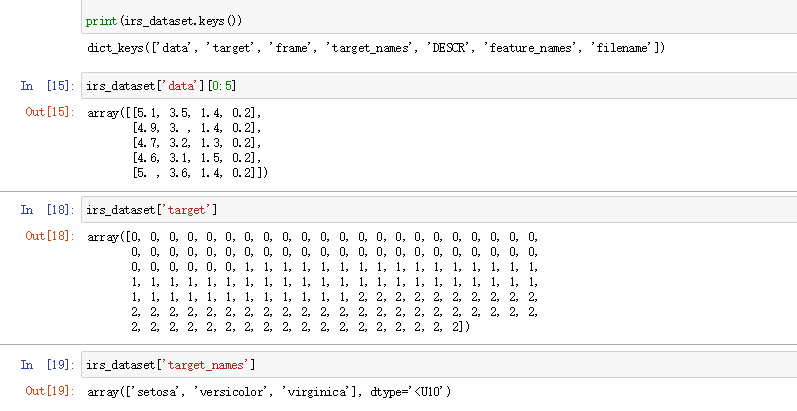
可以发现iris_dataset类似一个字典,里面包含键和值,其中键值对包括数据的简介(DESC)、标签值(target)、数据样本(data),标签名(target name)等
2、数据预处理
- 本次使用的数据无需预处理,已经处理好了,目标值也被表示为0,1,2的数字标签,data和target都是ndarray数组。
3、特征工程
- 本次数据还比较简单,特征也少,无需特征选择,
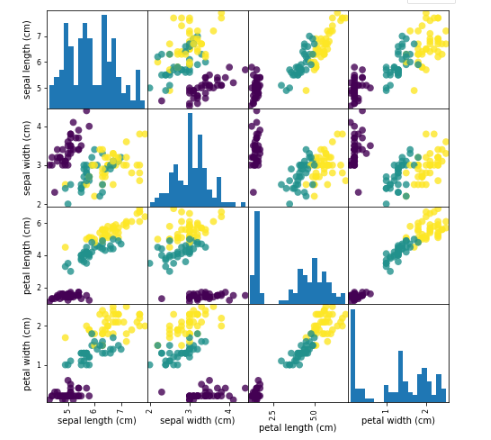
- 这里利用pandas的scatter.metrix将数据进行可视化一下,进行观察各个特征之间的关系,
在此之前先划分一下训练集和测试集
- 这里利用pandas的scatter.metrix将数据进行可视化一下,进行观察各个特征之间的关系,
#划分训练集,测试集
X_train,X_test,y_trian,y_test = train_test_split(irs_dataset['data'],irs_dataset['target'],random_state = 0)
#利用pd,画散点图,观察数据是否有异常值
irs_dataframe = pd.DataFrame(X_train,columns=irs_dataset.feature_names)
grr = pd.plotting.scatter_matrix(irs_dataframe,c=y_trian,figsize=(8,8),marker='o',
hist_kwds={'bins':20},s=60,alpha=.8)
4、(机器学习)构建模型
考虑到这个数据特点,这里使用KNN算法
KNN:在判断一个数据X的标签时,会计算距离它与其他所有样本x1,x2,x3,...,的距离,选择距离它最近的k个样本的标签值,作为该数据X的标签值。
#建立模型:KNN算法
knn = KNeighborsClassifier(n_neighbors=2) #把k值设为2
knn.fit(X_train, y_trian) #基于训练集构建模型,两个参数都是Numpy 数组
5、模型评估
怎么知道该模型在预测新数据时的有效性呢?有很多评估指标,比如说精确率、召回率...
这里使用精确率:正确预测列别的数据,占所有数据的比例
#评估模型
y_pred = knn.predict(X_test)
print(y_pred)
print("precision={:.2f}".format(np.mean(y_pred==y_test)))
print(knn.score(X_test, y_test))
二、遇到的问题
- 按照书上所写使用pandas的scatter.metrix画散点图做相关性分析时遇到’module ‘pandas’ has no attribute ‘scatter_matrix’'这个问题

解决方法:
现在的pandas的scatter_matrix用法已经发生变化了,在使用时需要加上plotting,即:pandas.plotting.scatter_matrix
三、参考文献
《python机器学习基础教程》--【德】Adreas C.Muller
构建第一个模型:KNN算法(Iris_dataset)的更多相关文章
- 机器学习之近邻算法模型(KNN)
1..导引 如何进行电影分类 众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 ...
- [Python] 应用kNN算法预测豆瓣电影用户的性别
应用kNN算法预测豆瓣电影用户的性别 摘要 本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验.利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类 ...
- KNN算法的补充
文本自动分类技术是文字管理的基础.通过快速.准确的文本自动分类,可以节省大量的人力财力:提高工作效率:让用户快速获得所需资源,改善用户体验.本文着重对KNN文本分类算法进行介绍并提出改进方法. 一.相 ...
- 【机器学习算法基础+实战系列】KNN算法
k 近邻法(K-nearest neighbor)是一种基本的分类方法 基本思路: 给定一个训练数据集,对于新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例多数属于某个类别,就把输 ...
- sklearn学习 第一篇:knn分类
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(label),也就是该数据所属的分类. 一,kNN算法的逻辑 kNN算法的核 ...
- KNN算法和实现
KNN要用到欧氏距离 KNN下面的缺点很容易使分类出错(比如下面黑色的点) 下面是KNN算法的三个例子demo, 第一个例子是根据算法原理实现 import matplotlib.pyplot as ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 深入浅出KNN算法
概述 K最近邻(kNN,k-NearestNeighbor)分类算法 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征 ...
- 机器学习笔记--KNN算法2-实战部分
本文申明:本系列的所有实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. 一案例导入:玛利亚小姐最近寂寞了, ...
随机推荐
- SQL之总结(四)---null问题的处理
概述:如果表中的某个列是可选的,那么我们可以在不向该列添加值的情况下插入新记录或更新已有的记录.这意味着该字段将以 NULL 值保存. NULL 值的处理方式与其他值不同. NULL 用作未知的或不适 ...
- 百度图像识别SDK实验
软件构造实验作业 实验名称:百度图像识别SDK实验 班级:信1905-1 学号:20194171 姓名:常金悦 一. 实验要求 每个步骤必须截图并说明 二.实验步 ...
- Bitmap图片的处理
一.View转换为Bitmap 在Android中所有的控件都是View的直接子类或者间接子类,通过它们可以组成丰富的UI界面.在窗口显示的时候Android会把这些控件都加载到内存中,形成一个以 ...
- Java将字符串的首字母转换大小写
//首字母转小写public static String toLowerCaseFirstOne(String s){ if(Character.isLowerCase(s.charAt(0))) ...
- 布局框架frameset
<!DOCTYPE html>//demo.html <html> <head> <meta charset="UTF-8"> &l ...
- 手动封装一个node命令集工具
了解NPM安装模块时与项目配置文件中的bin配置发生了什么 了解nodejs在控制台中的运行环境及上下文 基于自定义命令集工具集成Yeoman 一.NPM模块安装内幕与nodejs控制台运行环境 1. ...
- Typora+PicGO+Gitee实现图床功能
Typora+PicGO+Gitee实现图床功能 版本 typora(0.9.86) PicGo(2.3.0) 主要参考链接 出现问题就先看看这个 问题一 打开PicGo后安装github插件会一直安 ...
- OA办公软件篇(二)—权限管理
权限管理的背景 权限管理的作用 迭代历程 关键名词释义 权限管理模型 具体实现 写在最后 权限管理的背景 在OA办公软件篇(一)-组织架构一文中,我们说到组织架构是软件系统的权限体系的重要搭建依据 ...
- 『现学现忘』Git基础 — 8、Git创建本地版本库
目录 1.Git版本库介绍 2.创建本地版本库 场景一:创建一个空的本地版本库. 场景二:项目中已存在文件时,创建该项目的本地版本库. 场景三:在GitHub网站上创建仓库,克隆到本地. 1.Git版 ...
- 基于 POI 封装 ExcelUtil 精简的 Excel 导入导出
注 本文是使用 org.apache.poi 进行一次简单的封装,适用于大部分 excel 导入导出功能.过程中可能会用到反射,如若有对于性能有极致强迫症的同学,看看就好. 序 由于 poi 本身只是 ...