kafka producer 源码总结
kafka producer可以总体上分为两个部分:
- producer调用send方法,将消息存放到内存中
- sender线程轮询的从内存中将消息通过NIO发送到网络中
1 调用send方法
其实在调用new KafkaProducer初始化一个producer实例的时候,已经初始化了一个sender线程在后台轮询,不过为了方便理解,我们先分析send方法,即producer如何将消息放到内存队列中的。
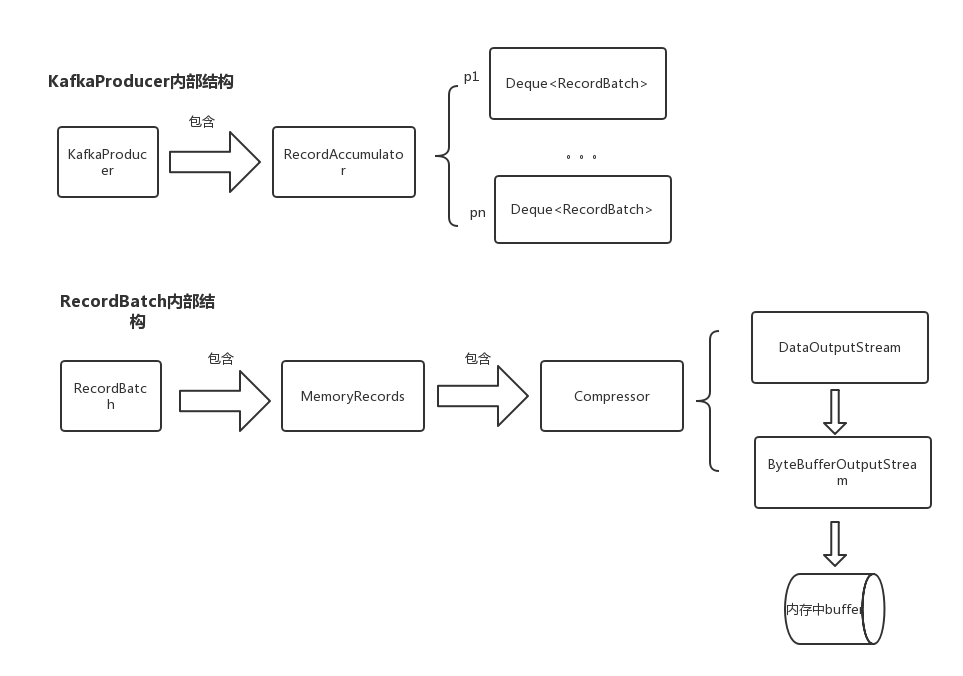
1.1 producer存储结构
producer的整体存储结构如下图
1.2 整体流程
kafka在发送消息的时候,首先会连接一台broker来获取metadata信息,从metadata中可以知道要发送的topic一共有几个partiton、partiton的leader所在broker等信息。获取到metadata信息后,会通过获取到metadata信息并通过消息的key来计算消息被分配到哪个partiton(注意:消息被分配到哪个partiton是在客户端被计算好的)。然后会将消息按照partiton分组,放到对应的RecordBatch中,如果RecordBatch大于batch.size的大小,则新建一个RecordBatch放在list末尾。
doSend流程
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
// 阻塞并唤醒sender线程,等待sender线程获取到metadata
long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs);
long remainingWaitMs = Math.max(0, this.maxBlockTimeMs - waitedOnMetadataMs);
byte[] serializedKey;
// 序列化key和value
serializedKey = keySerializer.serialize(record.topic(), record.key());
byte[] serializedValue;
serializedValue = valueSerializer.serialize(record.topic(), record.value());
// 计算消息应该放在哪个partition分区,如1.3详细介绍
int partition = partition(record, serializedKey, serializedValue, metadata.fetch());
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize);
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
// 根据计算到的分区,将消息追加到对应分区所在的Deque<RecordBatch>中,如1.4详细介绍
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
// 如果是新创建batch或者batch满了,那么就唤醒sender线程。
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
//...
}
1.3 选择分区
在doSend方法中,调用partition 来计算消息的分区。如果没有特别指定的话,会使用默认的分区方法:
- 如果消息含有key,则计算方式是 key的绝对值 % (partiton个数 - 1)
- 如果不包含key的话,则采用round-robin方式发送。
1.4 消息放到内存中
accumulator#append(..)中会首先尝试将消息放到分区所对应的Deque<RecordBatch> 的最后一个batch中,如果添加失败(比如RecordBatch已经满了),则会使用BufferPool从内存中申请一块大小为batch.size的内存出来(如果消息体大于batch.size,则申请消息体大小的内存),将消息放到新的batch中,并将新的batch添加到Deque<RecordBatch>中。
append
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
appendsInProgress.incrementAndGet();
try {
Deque<RecordBatch> dq = getOrCreateDeque(tp);
// 注意,这里操作是加锁的。加锁的原因是
// 1.producer是可以多线程访问的
// 2.sender线程也会操作Deque<RecordBatch>
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordBatch last = dq.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future != null)
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
// 申请内存,大小为消息体和batch.size的最大值,另外buffer中其实只缓存batch.size大小的内存,只有batch.size大小的内存申请才会从buffer中获取,大于batch.size会重新开辟空间,
// 所以合理规划batch.size和消息体大小可以有效提供客户端内存使用效率
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
// 从池子中申请
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
// 注意,这里又用到锁,不将两个锁合并成一个锁原因是减少锁的粒度
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordBatch last = dq.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future != null) {
free.deallocate(buffer);
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
2 sender线程
sender线程在new出一个Kafka Producer实例后就已经开始运行了.
消息放到内存中是按照partiton来进行分组的,但是sender线程发送的时候是按照broker的node节点来发送,这点需要注意。
sender线程的整体逻辑如下:
void run(long now) {
Cluster cluster = metadata.fetch();
// ready用来获取已经ready的节点,注意是节点,所谓ready节点是指partiton满足以下条件之一后,partition的leader所在的节点为ready
// 1. Deque<RecordBatch> size大于1,说明已经有一个Batch满了,可以发送
// 2. 内存池已经耗尽,这时候需要发送写消息,来释放内存
// 3. linger.ms 时间到了,表示可以发送了
// 4. 调用了close方法,需要将内存中消息发送出去
// 如果partiton满足以上条件之一,那么parttion所在的leader节点就算准备好了
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
if (result.unknownLeadersExist)
this.metadata.requestUpdate();
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
// 由于RecordBatch是按照partiton来组织的,而sender线程是按照节点来发送的,所以drain的作用就是将RecordBatch转换为按照节点来组织的方式。drain只会获取每个分区的第一个BatchRecord,而不是将一个分区的所有BatchRecord都发送,主要是避免饥饿
Map<Integer, List<RecordBatch>> batches = this.accumulator.drain(cluster,
result.readyNodes,
this.maxRequestSize,
now);
if (guaranteeMessageOrder) {
for (List<RecordBatch> batchList : batches.values()) {
for (RecordBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
List<RecordBatch> expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, now);
for (RecordBatch expiredBatch : expiredBatches)
this.sensors.recordErrors(expiredBatch.topicPartition.topic(), expiredBatch.recordCount);
sensors.updateProduceRequestMetrics(batches);
// 一个节点只会产生一个request
List<ClientRequest> requests = createProduceRequests(batches, now);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (result.readyNodes.size() > 0) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
log.trace("Created {} produce requests: {}", requests.size(), requests);
pollTimeout = 0;
}
for (ClientRequest request : requests)
client.send(request, now);
// 真正的发送
this.client.poll(pollTimeout, now);
}
3 一些细节总结
- batch.size和linger.ms满足其中之一,sender线程便会被激活进行发送消息
- sender每次只拿出一个partiton的一个RecordBatch进行发送,即便该partiton已经有多个RecordBatch满了,这样做主要为了避免其他parttion饥饿, 详见RecordAccumulator#drain(..)
- RecordAccumulator#drain(..)后,被drain的RecordBatch会被close,不可写;同时从相应的Deque<RecordBatch>中移除。
kafka producer 源码总结的更多相关文章
- kafka producer源码
producer接口: /** * Licensed to the Apache Software Foundation (ASF) under one or more * contributor l ...
- Kafka Producer源码解析一:整体架构
一.Producer整体架构 Kafka Producer端的架构整体也是一个生产者-消费者模式 Producer线程调用send时,只是将数据序列化后放入对应TopicPartition的Deque ...
- Kafka Producer源码简述
接着上文kafka的简述,这一章我们一探kafka生产者是如何发送消息到消息服务器的. 代码的入口还是从 kafkaTemplate.send开始 最终我们就会到 org.springframewor ...
- kafka C客户端librdkafka producer源码分析
from:http://www.cnblogs.com/xhcqwl/p/3905412.html kafka C客户端librdkafka producer源码分析 简介 kafka网站上提供了C语 ...
- Kakfa揭秘 Day7 Producer源码解密
Kakfa揭秘 Day7 Producer源码解密 今天我们来研究下Producer.Producer的主要作用就是向Kafka的brokers发送数据.从思考角度,为了简化思考过程,可以简化为一个单 ...
- Kafka Eagle 源码解读
1.概述 在<Kafka 消息监控 - Kafka Eagle>一文中,简单的介绍了 Kafka Eagle这款监控工具的作用,截图预览,以及使用详情.今天笔者通过其源码来解读实现细节.目 ...
- kafka 0.8.1 新producer 源码简单分析
1 背景 最近由于项目需要,需要使用kafka的producer.但是对于c++,kafka官方并没有很好的支持. 在kafka官网上可以找到0.8.x的客户端.可以使用的客户端有C版本客户端,此客户 ...
- 高吞吐量的分布式发布订阅消息系统Kafka之Producer源码分析
引言 Kafka是一款很棒的消息系统,今天我们就来深入了解一下它的实现细节,首先关注Producer这一方. 要使用kafka首先要实例化一个KafkaProducer,需要有brokerIP.序列化 ...
- 读Kafka Consumer源码
最近一直在关注阿里的一个开源项目:OpenMessaging OpenMessaging, which includes the establishment of industry guideline ...
随机推荐
- [题解]Mail.Ru Cup 2018 Round 1 - A. Elevator or Stairs?
[题目] A. Elevator or Stairs? [描述] Masha要从第x层楼去第y层楼找Egor,可以选择爬楼梯或者坐直升电梯.已知爬楼梯每层需要时间t1:坐直升电梯每层需要时间t2,直升 ...
- 打印报表工具,web报表工具对比
1.jasperreport报表 有批量报表打印功能,但一般需要通过专门的编程实现批量报表打印:一些较简单的分片式打印能通过主子表实现:不能自动适应纸张大小:不支持分栏打印:不支持一纸多页打印:不支 ...
- 想用WPS 2019模板设计报表?Smartbi V9没问题
导读:Smartbi V9 报表设计器可以支持WPS 2019个人版了,而且报表功能也有明显增强. 企业报表软件(Smartbi Spreadsheet)是思迈特软件于2014年针对企业客户.系统 ...
- WPF中使用OpenFileDialog打开文件
添加Microsoft.Win32程序集 private void OnOpenFile(object sender, EventArgs e) { OpenFileDialog openFileDi ...
- PyTorch深度学习实践——处理多维特征的输入
处理多维特征的输入 课程来源:PyTorch深度学习实践--河北工业大学 <PyTorch深度学习实践>完结合集_哔哩哔哩_bilibili 这一讲介绍输入为多维数据时的分类. 一个数据集 ...
- Could not load file or assembly 'System.Windows.Forms, Version=6.0.2.0, Culture=neutral, PublicKeyToken=b77a5c561934e089
项目升级后提示错误 System.IO.FileNotFoundException: Could not load file or assembly 'System.Windows.Forms, Ve ...
- 【Azure API 管理】使用APIM进行XML内容读取时遇见的诡异错误 Expression evaluation failed. Object reference not set to an instance of an object.
问题描述 使用APIM,在 Inbound 中对请求的Body内容进行解析.客户端请求所传递的Request Body为XML格式,需要从Request Body中解析出多个(Element)节点值, ...
- tp5.0 composer下载phpexcel 实现导出excel 表格
tp5.0 composer下载phpexcel 实现导出excel 表格 1.在下载好的tp5.0 框架里面使用 composer 下载phpexcel 的插件 composer require p ...
- JDBC 使用详解
1.JDBC 编程步骤: 加载驱动程序; Class.forName(driverClass) 加载Mysql驱动:Class.forName("com.mysql.jdbc.Driver& ...
- Redis pub/sub
list 类型, lpush + rpop 或 lpush + brpop 用作消息队列时,消息只能消费一次,且不支持多个消费者(消息只能消费一次),并且在客户端崩溃时容易丢失消息.而 pub/sub ...