Solr的搭建
Solr6.6.0下载地址
http://www.apache.org/dyn/closer.lua/lucene/solr/
安装JRE
需要Java Runtime Environment(JRE) 1.7或更高版本,先验证。
# java -version

没有java的想偷懒的话可以yum安装
//查看是否安装java
#rpm -qa | grep java //没有的话就yum安装
# yum -y install java
安装Solr 6.6.0
1.去http://www.apache.org/dyn/closer.lua/lucene/solr/ 下载Solr安装文件solr-6.6.0.tgz
2.将solr-6.6.0.tgz文件放到/tmp目录下,执行如下脚本:
# cd /tmp
# tar -zxvf solr-6.6.0.tgz // 解压压缩包
3.创建应用程序和数据目录
# mkdir -p /data/solr /usr/local/solr
4.创建运行solr的用户并赋权
# groupadd solr
# useradd -g solr solr
# chown -R solr.solr /data/solr /usr/local/solr
5.安装solr服务 (/tmp 文件下)
# solr-6.6.0/bin/install_solr_service.sh solr-6.6.0.tgz -d /data/solr -i /usr/local/solr
6.检查服务状态
# service solr status
第6步会出现

创建集合
在这个部分,我们创建一个简单的Solr集合。
Solr可以有多个集合,但在这个示例,我们只使用一个。使用如下命令,创建一个新的集合。我们以solr用户运行以避免任何权限错误。
# su - solr -c "/usr/local/solr/solr/bin/solr create -c gettingstarted -n data_driven_schema_configs"
在这个命令中,gettingstarted是集合的名字,-n指定配置集合。Solr默认提供了3个配置集合。这里我们使用的是schemaless,意思是可以提供任意名字的任意列,类型将会被猜测。
添加和查询文档
在这个部分,我们将浏览Solr Web界面,添加一些文档到集合中。
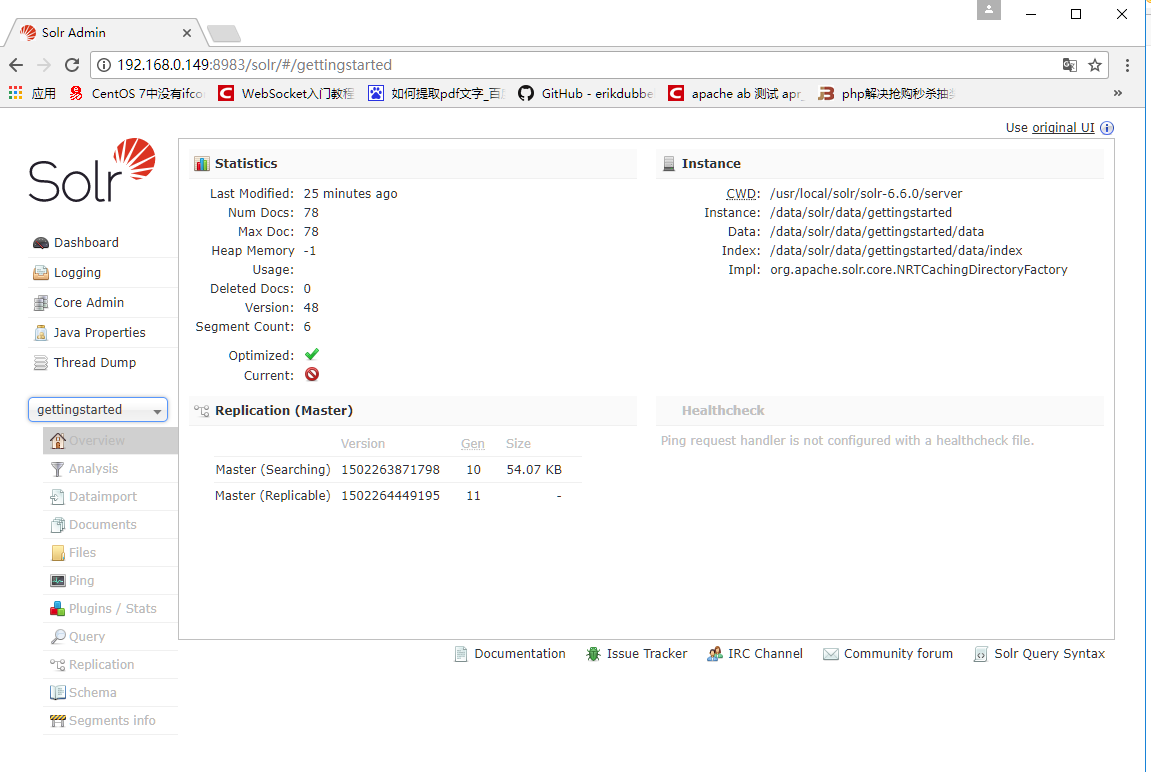
问你使用Web浏览器访问http://your_server_ip:8983/solr,Solr Web界面将会显示为:

这个Web界面包含大量的有用信息,可以被用于调试在使用中产生的任何问题。
集合被划分为核,这就是为什么在Web界面中有大量的对核的参照。
现在,gettingstarted只包含一个核,名为gettingstarted。在左手边,可以看到“Core Selector”下拉菜单,我们可以选择gettingstarted看到更多信息。
在选择gettingstarted核之后,选择“Documents”。文档存储可被Solr搜索的真实数据。因为我们使用了一个无模式的配置,我们可以使用任何列。我使用如下的JSON示例添加了一个单一文档,通过拷贝以下到“Documents(s)”列:
{
"number": 1,
"president": "George Washington",
"birth_year": 1732,
"death_year": 1799,
"took_office": "1789-04-30",
"left_office": "1797-03-04",
"party": "No Party"
}
点击“Submit document”添加文档到索引。过一会,你会看到如下信息:
添加文档后的输出:
Status: success
Response:
{
"responseHeader": {
"status": 0,
"QTime": 290
}
}
你可以使用一个类似的或完全不同的结构添加更多文档,但你也可以只使用一个文档继续。
现在,选择左边的“Query”去查询我们刚刚添加的文档。保持屏幕中的默认值,在点击“Execute Query”之后,你最多看到10个文档,依赖于你添加了多少:
查询输出
{
"responseHeader": {
"status": 0,
"QTime": 39,
"params": {
"q": "*:*",
"indent": "true",
"wt": "json",
"_": "1442371884598"
}
},
"response": {
"numFound": 1,
"start": 0,
"docs": [
{
"number": [
1
],
"president": [
"George Washington"
],
"birth_year": [
1732
],
"death_year": [
1799
],
"took_office": [
"1789-04-30T00:00:00Z"
],
"left_office": [
"1797-03-04T00:00:00Z"
],
"party": [
"No Party"
],
"id": "b9b294c1-4b68-4d96-adc2-f6fb77f60932",
"_version_": 1512437472611532800
}
]
}
}
Solr的搭建的更多相关文章
- 第04项目:淘淘商城(SpringMVC+Spring+Mybatis)【第八天】(solr服务器搭建、搜索功能实现)
https://pan.baidu.com/s/1bptYGAb#list/path=%2F&parentPath=%2Fsharelink389619878-229862621083040 ...
- Solr环境搭建过程中遇到的问题
Solr下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/6.3.0 Solr搭建步骤转自:http://blog.csdn.net/wbcg ...
- [solr] - 环境搭建2
前面使用Tomcat搭建solr,参考文章: http://www.cnblogs.com/HD/p/3977799.html 原来solr可以不使用tomcat/jboss等服务器,它自身已经集成了 ...
- Solr Cloud搭建
1:搭建tomcat 配置connector: server.xm文件中: <Connector port="8080"maxThreads="200" ...
- solr环境搭建
介绍摘自百度百科:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引:也可以通过 ...
- [精华]Hadoop,HBase分布式集群和solr环境搭建
1. 机器准备(这里做測试用,目的准备5台CentOS的linux系统) 1.1 准备了2台机器,安装win7系统(64位) 两台windows物理主机: 192.168.131.44 adminis ...
- Solr搜索引擎搭建详细过程
1 什么是solr Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr可以独立运行在Jetty.Tomcat等这些Servlet容器中 ...
- solr服务器搭建
百度百科定义:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引:也可以通过Ht ...
- solr服务器搭建与Tomact整合及使用
一:solr服务器的搭建 1:搭建全新的为solr专用的solr服务器: 在自己电脑上搭建两台Tomact服务器,一台仍为应用服务器,一台作为solr服务器,应用服务器按照正常Tomact服务器搭建即 ...
- jdk、tomcat、solr环境搭建
环境概述 1)操作系统:windows7旗舰版(64位) 2)jdk:jdk-8u131-windows-x64: 3)tomcat:apache-tomcat-9.0.0.M21 4)solr:so ...
随机推荐
- tornado运行提示OSError: [WinError 10048] 通常每个套接字地址(协议/网络地址/端口)只允许使用一次。
找到占用端口的进程,kill掉 netstat -ano | find $(port) kill: tskill $(PID)
- Feign 的简单使用(2)
依赖: <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>sp ...
- 飞鸽传书linux进程退出不彻底
问题描述: 飞鸽传书linux版本(QIpmsg)是有问题的. 在ubuntu14.04上运行的时候,没有任务栏图标,点击关闭也不能退出进程,端口仍然占用,无法再次运行. 这个问题截至1.2.1412 ...
- Eclipse集成SonarLint
https://docs.sonarqube.org/display/PLUG/Writing+Custom+Java+Rules+101
- jsfl 选择图层 选择帧 转化成mc
//打开fla var _openDOC = fl.openDocument("file:///E|TE/爱.fla"); //获取图层4的总帧 var _Length=fl.ge ...
- MySQL数据库备份工具mysqldump的使用(转)
说明:MySQL中InnoDB和MyISAM类型数据库,这个工具最新版本好像都已经支持了,以前可能存在于MyISAM的只能只用冷备份方式的说法. 备份指定库: mysqldump -h127.0.0. ...
- javascript:控制一个元素高度始终等于浏览器高度
window.onresize = function(){ this.opHtight()} //给浏览器添加窗口大小改变事件window.onresize = function(){ this.op ...
- ubuntu 该软件包现在的状态极为不妥 error
rm -rf /var/lib/dpkg/info/yourerrorsofware* dpkg --remove --force-remove-reinstreq yourerrorsoftware ...
- Eclipce 配置javaEE
Eclipse 安装JavaEE插件 Oxygen版Eclipse 导入项目会自动安装你项目需要的一些插件,但是有时候会安装失败,需要手动安装: 这里以Dynamic Web Project项目为 ...
- 将IP地址字符串转为32位二进制
def str2bin(s): temp = s.split('.') result = '' for i in range(len(temp)): temp[i] = str(bin(int(tem ...