【Java】 大话数据结构(15) 排序算法(2) (快速排序及其优化)
本文根据《大话数据结构》一书,实现了Java版的快速排序。
更多:数据结构与算法合集
基本概念
基本思想:在每轮排序中,选取一个基准元素,其他元素中比基准元素小的排到数列的一边,大的排到数列的另一边;之后对两边的数列继续进行这种排序,最终达到整体有序。
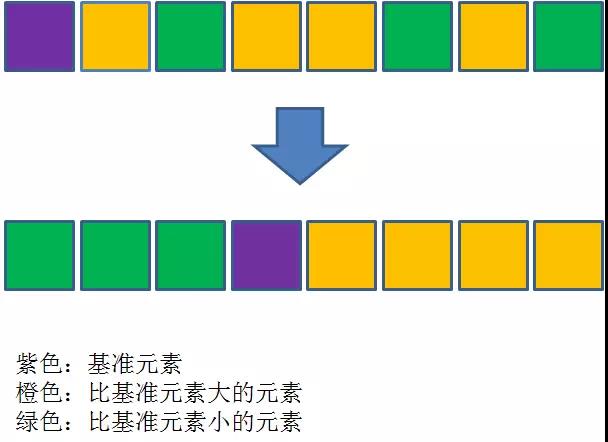
图片来自公众号:程序员小灰
实现代码
根据上述基本思想,可以先写出快速排序最核心的代码:对于数组a中从下标为low至下标为high的元素,选取一个基准元素(记为pivotKey),根据与基准比较的大小,将这些元素排到基准元素的两端。
注意点:1.两端向中间扫描时,一定要先从高段往低端扫描(low<high && a[high]<pivotKey),这样才能实现pivotKey一直会交换到中间。!!
2.比较大小时不要忘记low<high还要一直成立,即(low<high && a[high]<pivotKey)。!! 例如,数组全为同一个数字时,不加这个判断有可能导致越界
/**
* 对数组a中下标从low到high的元素,选取基准元素pivotKey,
* 根据与基准比较的大小,将各个元素排到基准元素的两端。
* 返回值为最后基准元素的位置
*/
public int partition(int[] a, int low, int high) {
int pivotKey = a[low]; //用第一个元素作为基准元素
while (low < high) { //两侧交替向中间扫描
while (low < high && a[high] >= pivotKey)
high--;
swap(a, low, high); //比基准小的元素放到低端
while (low < high && a[low] <= pivotKey)
low++;
swap(a, low, high); //比基准大的元素放到高端
}
return low; //返回基准元素所在位置
}
将元素分为两部分后,必须对两个子部分继续进行上面的排序,所以要用到递归。代码如下:
/**
* 递归调用
*/
public void qSort(int[] a, int low, int high) {
int pivot;
if (low >= high)
return;
pivot = partition(a, low, high); //将数列一分为二
qSort(a, low, pivot - 1); //对低子表排序
qSort(a, pivot + 1, high); //对高子表排序
}
完整Java代码
(含测试代码)
import java.util.Arrays; /**
*
* @Description 快速排序
*
* @author yongh
* @date 2018年9月14日 下午2:39:00
*/
public class QuickSort {
public void quickSort(int[] a) {
if (a == null)
return;
qSort(a, 0, a.length - 1);
} /**
* 递归调用
*/
public void qSort(int[] a, int low, int high) {
int pivot;
if (low >= high)
return;
pivot = partition(a, low, high); //将数列一分为二
qSort(a, low, pivot - 1); //对低子表排序
qSort(a, pivot + 1, high); //对高子表排序
} /**
* 对数组a中下标从low到high的元素,选取基准元素pivotKey,
* 根据与基准比较的大小,将各个元素排到基准元素的两端。
* 返回值为最后基准元素的位置
*/
public int partition(int[] a, int low, int high) {
int pivotKey = a[low]; //用第一个元素作为基准元素
while (low < high) { //两侧交替向中间扫描
while (low < high && a[high] >= pivotKey)
high--;
swap(a, low, high); //比基准小的元素放到低端
while (low < high && a[low] <= pivotKey)
low++;
swap(a, low, high); //比基准大的元素放到高端
}
return low; //返回基准元素所在位置
} public void swap(int[] a, int i, int j) {
int temp;
temp = a[j];
a[j] = a[i];
a[i] = temp;
} // =========测试代码=======
public void test1() {
int[] a = null;
quickSort(a);
System.out.println(Arrays.toString(a));
} public void test2() {
int[] a = {};
quickSort(a);
System.out.println(Arrays.toString(a));
} public void test3() {
int[] a = { 1 };
quickSort(a);
System.out.println(Arrays.toString(a));
} public void test4() {
int[] a = { 3, 3, 3, 3, 3 };
quickSort(a);
System.out.println(Arrays.toString(a));
} public void test5() {
int[] a = { -3, 6, 3, 1, 3, 7, 5, 6, 2 };
quickSort(a);
System.out.println(Arrays.toString(a));
} public static void main(String[] args) {
QuickSort demo = new QuickSort();
demo.test1();
demo.test2();
demo.test3();
demo.test4();
demo.test5();
}
}
null
[]
[]
[, , , , ]
[-, , , , , , , , ]
QuickSort
快速排序优化
1.优化选取枢纽
基准应尽量处于序列中间位置,可以采取“三数取中”的方法,在partition()方法开头加以下代码,使得a[low]为三数的中间值:
// 三数取中,将中间元素放在第一个位置
if (a[low] > a[high])
swap(a, low, high);
if (a[(low + high) / 2] > a[high])
swap(a, (low + high) / 2, high);
if (a[low] < a[(low + high) / 2])
swap(a, (low + high) / 2, low);
2.优化不必要的交换
两侧向中间扫描时,可以将交换数据变为替换:
while (low < high) { // 两侧交替向中间扫描
while (low < high && a[high] >= pivotKey)
high--;
a[low] = a[high];
// swap(a, low, high); //比基准小的元素放到低端
while (low < high && a[low] <= pivotKey)
low++;
a[high] = a[low];
// swap(a, low, high); //比基准大的元素放到高端
}
a[low]=pivotKey; //在中间位置放回基准值
3.优化小数组时的排序方案
当数组非常小时,采用直接插入排序(简单排序中性能最好的方法)
4.优化递归操作
qSort()方法中,有两次递归操作,递归对性能有较大影响。因此,使用while循环,在第一次递归后,变量low就没有用处了,可将pivot+1赋值给low,下次循环中,partition(a, low, high)的效果等同于qSort(a, pivot + 1, high),从而可以减小堆栈的深度,提高性能。
// pivot = partition(a, low, high); // 将数列一分为二
// qSort(a, low, pivot - 1); // 对低子表排序
// qSort(a, pivot + 1, high); // 对高子表排序 //优化递归操作
while (low < high) {
pivot = partition(a, low, high); // 将数列一分为二
qSort(a, low, pivot - 1); // 对低子表排序
low = pivot + 1;
}
复杂度分析
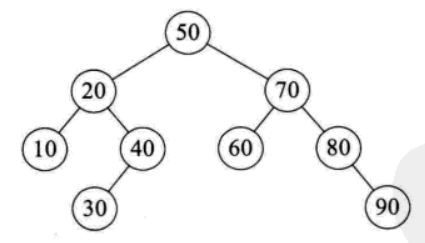
快速排序时间性能取决于递归深度,而空间复杂度是由递归造成的栈空间的使用。递归的深度可以用递归树来描述,如{50,10,90,30,70,40,80,60,20}的递归树如下:
最优情况:
最优情况下,每次选取的基准元素都是元素中间值,partition()方法划分均匀,此时根据二叉树的性质4可以知道,排序n个元素,其递归树的深度为[log2n]+1,所以仅需要递归log2n次。
将排序n个元素的时间记为T(n),则有以下推断:
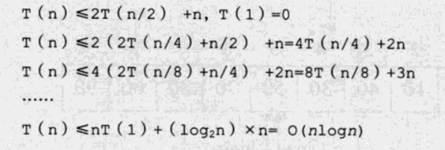
所以最优情况下的时间复杂度为:O(nlogn);同样根据递归树的深度,最优空间复杂度为O(logn)。
最坏情况:
递归树为一棵斜树,需要n-1次调用,所以最坏空间复杂度为O(logn)。在第i次调用中需要n-1次的关键字比较,所以比较次数为:Σ(n-i)=(n-1)+……+2+1=n(n-1)/2,所以最坏时间复杂度为O(n^2)。
平均情况:

平均时间复杂度:O(nlogn),平均空间复杂度O(logn)。
更多:数据结构与算法合集
【Java】 大话数据结构(15) 排序算法(2) (快速排序及其优化)的更多相关文章
- 【Java】 大话数据结构(14) 排序算法(1) (冒泡排序及其优化)
本文根据<大话数据结构>一书,实现了Java版的冒泡排序. 更多:数据结构与算法合集 基本概念 基本思想:将相邻的元素两两比较,根据大小关系交换位置,直到完成排序. 对n个数组成的无序数列 ...
- 【Java】 大话数据结构(16) 排序算法(3) (堆排序)
本文根据<大话数据结构>一书,实现了Java版的堆排序. 更多:数据结构与算法合集 基本概念 堆排序种的堆指的是数据结构中的堆,而不是内存模型中的堆. 堆:可以看成一棵完全二叉树,每个结点 ...
- 【Java】 大话数据结构(17) 排序算法(4) (归并排序)
本文根据<大话数据结构>一书,实现了Java版的归并排序. 更多:数据结构与算法合集 基本概念 归并排序:将n个记录的序列看出n个有序的子序列,每个子序列长度为1,然后不断两两排序归并,直 ...
- 【Java】 大话数据结构(18) 排序算法(5) (直接插入排序)
本文根据<大话数据结构>一书,实现了Java版的直接插入排序. 更多:数据结构与算法合集 基本概念 直接插入排序思路:类似扑克牌的排序过程,从左到右依次遍历,如果遇到一个数小于前一个数,则 ...
- Java常见排序算法之快速排序
在学习算法的过程中,我们难免会接触很多和排序相关的算法.总而言之,对于任何编程人员来说,基本的排序算法是必须要掌握的. 从今天开始,我们将要进行基本的排序算法的讲解.Are you ready?Let ...
- Java排序算法之快速排序
Java排序算法之快速排序 快速排序(Quicksort)是对冒泡排序的一种改进. 快速排序由C. A. R. Hoare在1962年提出.它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分 ...
- javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法)
javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法) 一.快速排序算法 /* * 这个函数首先检查数组的长度是否为0.如果是,那么这个数组就不需要任何排序,函数直接返回. * ...
- 【Java】 大话数据结构(11) 查找算法(2)(二叉排序树/二叉搜索树)
本文根据<大话数据结构>一书,实现了Java版的二叉排序树/二叉搜索树. 二叉排序树介绍 在上篇博客中,顺序表的插入和删除效率还可以,但查找效率很低:而有序线性表中,可以使用折半.插值.斐 ...
- Java中的数据结构及排序算法
(明天补充) 主要是3种接口:List Set Map List:ArrayList,LinkedList:顺序表ArrayList,链表LinkedList,堆栈和队列可以使用LinkedList模 ...
随机推荐
- Oracle中对number类型数据to_char()出现各位少0,或者值为###的处理
问题描述: 在Oracle中使用to_char()函数时当number值为小数时,常常个位0不显示 比如:select to_char(0.02) from dual,结果为.02 改进为 selec ...
- 前端学习 -- Css -- 文档流
文档流 文档流处在网页的最底层,它表示的是一个页面中的位置, 我们所创建的元素默认都处在文档流中 元素在文档流中的特点 块元素 块元素在文档流中会独占一行,块元素会自上向下排列. 块元素在文档流中默认 ...
- sql的执行流程
mysql中的SQL语句执行是有一定顺序的,如下:1. from2. on3. join4. where5. group by6. with7. having8. select9. distinct1 ...
- dp的进阶 (一)
熟练掌握dp的定义方法. ①四维dp的转移,生命值转移时候需要注意的 ②集合的定义,判断二进制内部是否有环 ③很难想到的背包问题 ④博弈类型的dp ⑤排列组合类型dp ⑥01背包的变种(01背包+完全 ...
- js调试系列: 控制台命令行API
js调试系列目录: - 上次初步介绍了什么是控制台,以及简单的 console.log 输出信息.最后还有两个小问题,我们就当回顾,来看下怎么操作吧. 先打开百度,然后按 F12 打开后,如果不是 C ...
- [原]JUnit 自定义扩展思路
1. 理解Annotation,http://www.cnblogs.com/mandroid/archive/2011/07/18/2109829.html 2. JUNIT整体执行过程分析,htt ...
- 【转载】RESTful API 设计指南
作者: 阮一峰 日期: 2014年5月22日 网络应用程序,分为前端和后端两个部分.当前的发展趋势,就是前端设备层出不穷(手机.平板.桌面电脑.其他专用设备......). 因此,必须有一种统一的机制 ...
- 【转】UICollectionView使用介绍
CHENYILONG Blog UICollectionView 使用介绍 技术博客http://www.cnblogs.com/ChenYilong/ 新浪微博http://weibo.com/lu ...
- !DOCTYPE 声明
!DOCTYPE 声明的作用: <!DOCTYPE html> 当使用 position 属性进行对齐时,请始终包含 !DOCTYPE 声明!如果省略,则会在 IE 浏览器中产生奇怪的结果 ...
- 面积并+扫描线 覆盖的面积 HDU - 1255
题目链接:https://cn.vjudge.net/problem/HDU-1255 题目大意:中文题目 具体思路:和上一篇的博客思路差不多,上一个题求的是面积,然后我们这个地方求的是啊覆盖两次及两 ...