nodejs抓取别人家的页面的始末
内容:分析并获取页面调取数据的API(接口),并跨域获取数据保存在文档中(nodejs做代理-CORS)
事由以及动机
2015年9月份全国研究生数学建模竞赛的F题,旅游线路规划问题。其中需要自己去查很多数据。例如所给201个5A级景区的位置,以及景区距离所在省会距离等等~开始队友小伙伴准备从百度手动去一个一个查询,但是效率极低,在这么短的时间内,需要收集这么多数据是多么的耗时,并且也不能把大把时间花费在查资料上,虽然说查资料是必须的,题目也鼓励我们从网上查询相关数据,因此在团队中的我就想到了让计算机帮我们去做这件事。
第一步,确定想要抓取的信息,获取数据服务api
以查询个两地的行车时间为例,我们以百度地图为例,见下图
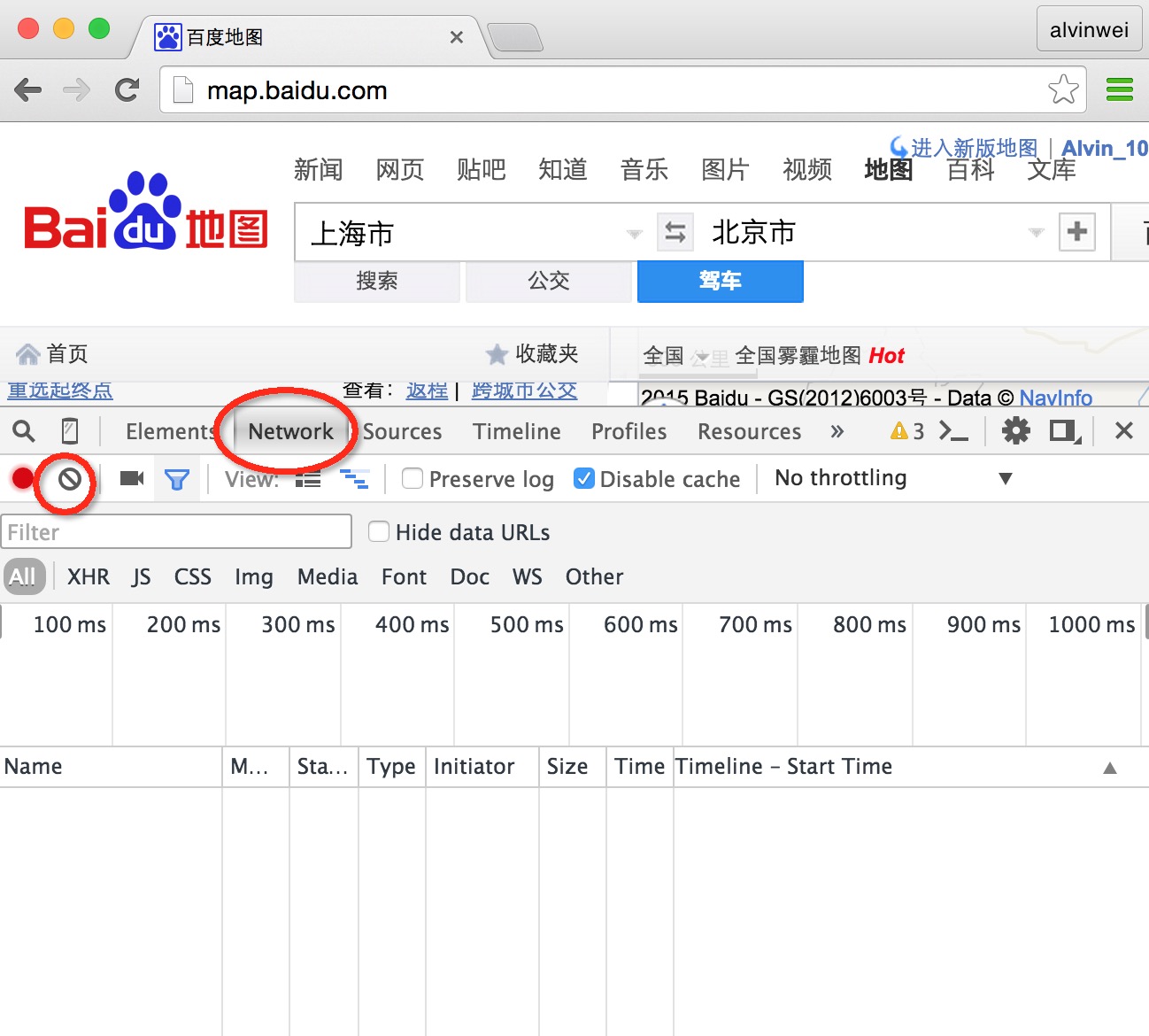
先打开需要去请求数据的网页,打开开发人员工具(我用的是chrome),选择Network选项卡,输入需要查询的内容(tips:先清除掉之前的网络获取纪录,以方便接下来的借接口分析)。
点击“查询”,并监控网络数据流,会发现网页发起了很多的http请求,并返回了结果。
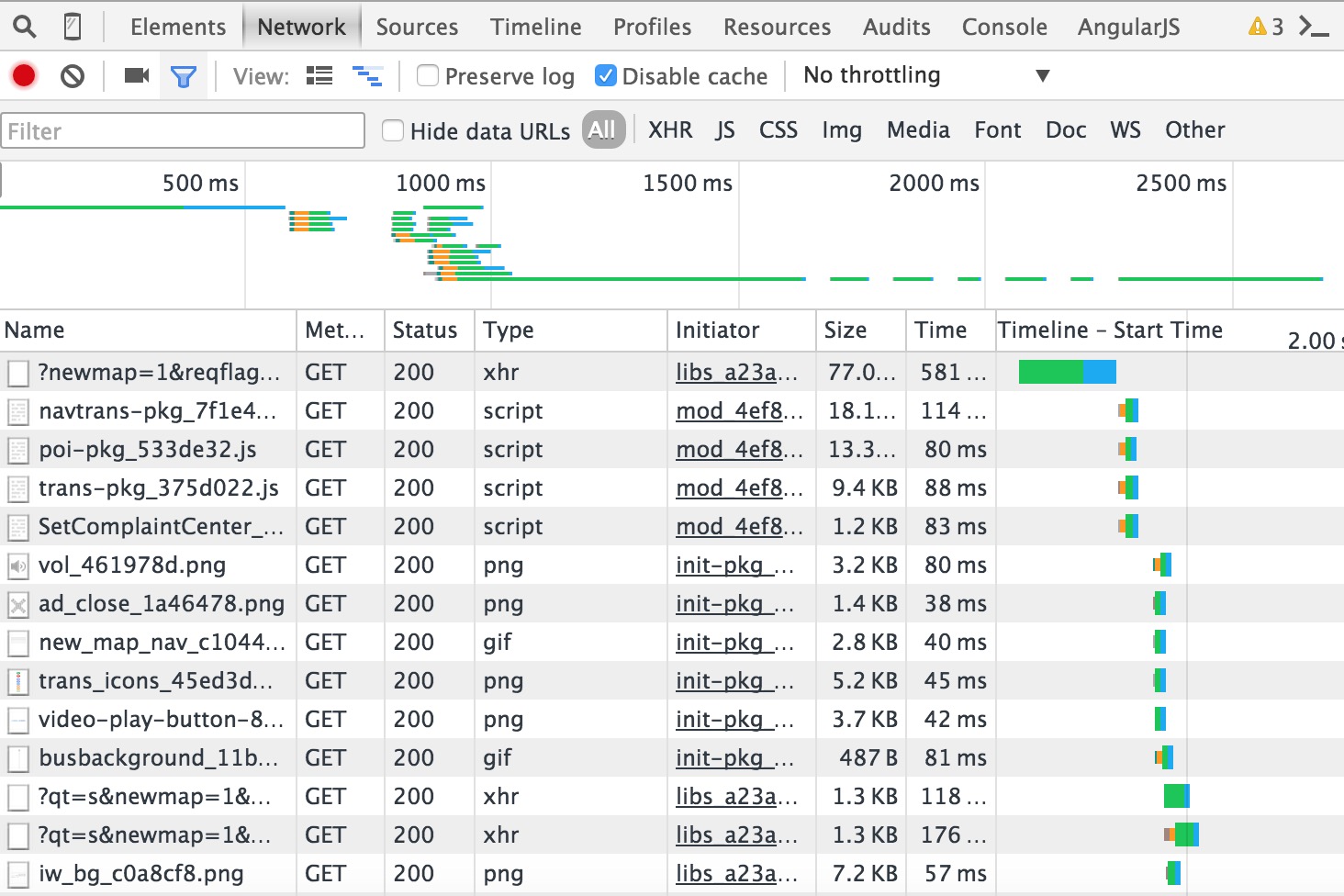
通过分析所有请求,拿到想要的请求接口(一般情况下,都不会是Type为图片类型的,并且耗时较长的)。
点击某个请求时能看到该请求的详细信息
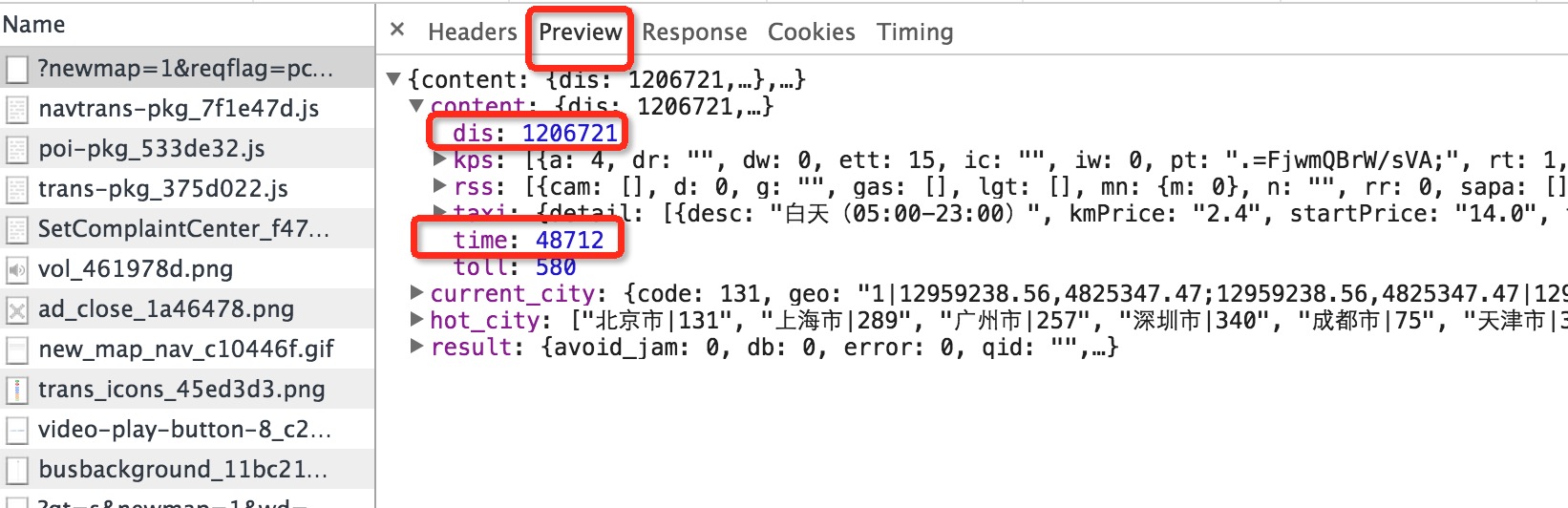
查看请求的头部信息Headers

拿到请求的地址:requestURL,例如:http://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&pcevaname=pc2&da_par=direct&from=webmap&qt=nav&da_src=pcmappg.searchBox.button&c=289&sn=2$$$$$$%E4%B8%8A%E6%B5%B7%E5%B8%82$$0$$$$&en=2$$$$$$%E5%8C%97%E4%BA%AC%E5%B8%82$$0$$$$&sc=289&ec=289&rn=5&extinfo=63&tn=B_NORMAL_MAP&nn=0&ie=utf-8&l=12&b=(13503777.31,3639994.64;13542753.31,3642234.64)&t=1443022534161
并分析,一般我们要看的是URL中的querey部分,也就是?后面的内容,一般来说由很多(字母+百分号)构成的为中文字符,是汉字被url转码获得。可以把该地址拿到地址栏查询一下,汉字的内容

那我们的数据服务API就拿到了
编写数据访问页面
接下来就是利用XMLHTTPRequerst来调取他人的服务了
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>getData</title>
</head>
<body>
<script src="http://code.jquery.com/jquery-2.1.4.min.js"></script>
<script>
var sn="北京市";
var en="上海市";
var url="http://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&pcevaname=pc2&da_par=direct&from=webmap&qt=nav&da_src=pcmappg.searchBox.button&c=289&sn=2$$$$$$"+
sn+"$$0$$$$&en=2$$$$$$"+
en+"$$0$$$$&sc=289&ec=289&rn=5&extinfo=63&tn=B_NORMAL_MAP&nn=0&ie=utf-8&l=12&b=(13503777.31,3639994.64;13542753.31,3642234.64)&t=1443022534161"; $.ajax({
url:url,
type:"get",
success:function(res){
console.log(res)
},
error:function(e){
console.log(e)
}
})
</script>
</body>
</html>
html
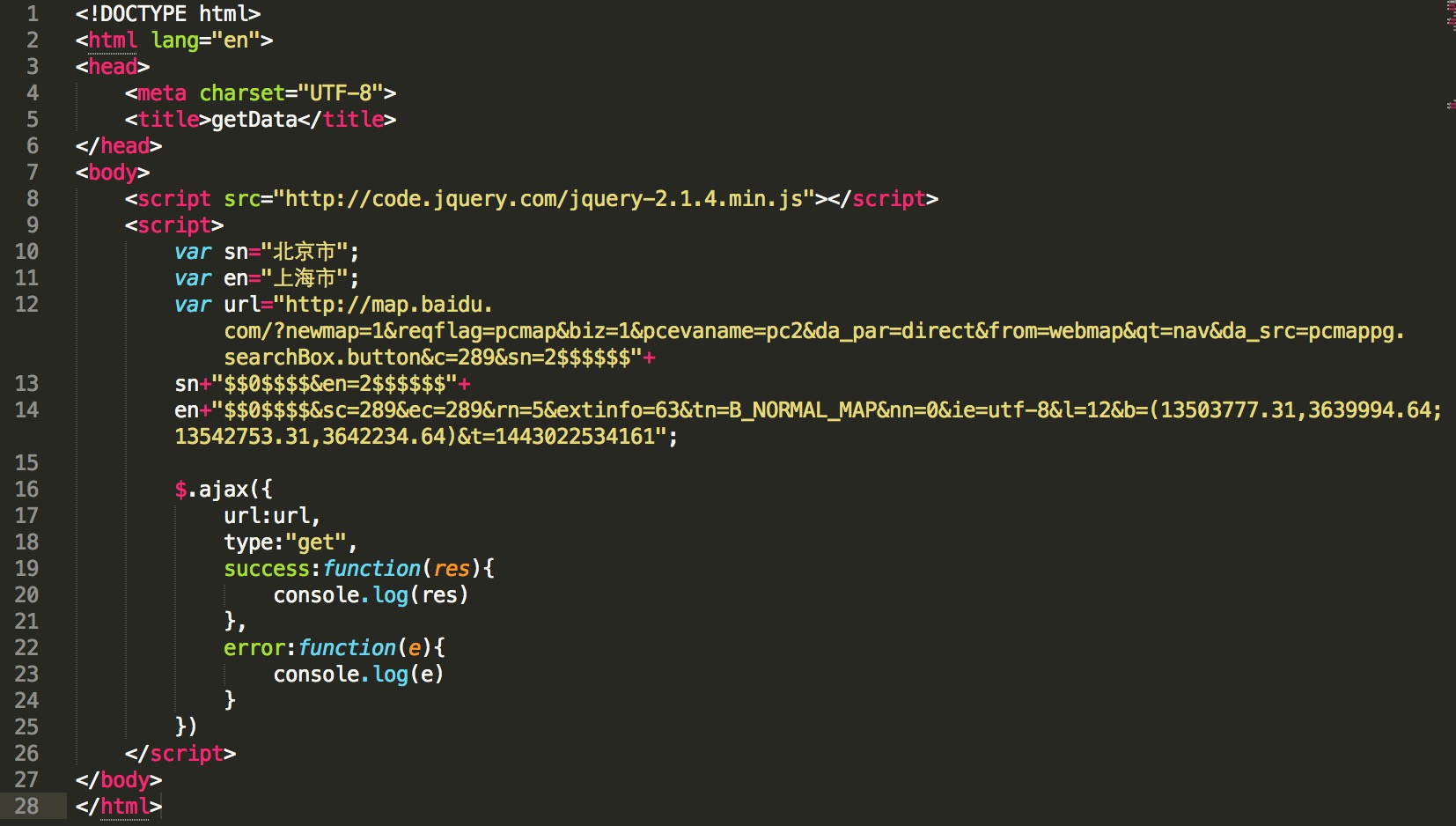
运行察看结果:

跨域提示错误,跨域(见为什么浏览器不能跨域http://www.cnblogs.com/alvinwei1024/p/4626054.html)是浏览器的行为。
方法1: 通过jsonp的方法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>getData</title>
</head>
<body>
<script src="http://code.jquery.com/jquery-2.1.4.min.js"></script>
<script>
var sn="北京市";
var en="上海市";
var url="http://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&pcevaname=pc2&da_par=direct&from=webmap&qt=nav&da_src=pcmappg.searchBox.button&c=289&sn=2$$$$$$"+
sn+"$$0$$$$&en=2$$$$$$"+
en+"$$0$$$$&sc=289&ec=289&rn=5&extinfo=63&tn=B_NORMAL_MAP&nn=0&ie=utf-8&l=12&b=(13503777.31,3639994.64;13542753.31,3642234.64)&t=1443022534161"; $.ajax({
url:url,
type:"get",
dataType:"jsonp",
jsonp:"callback",
success:function(res){
console.log(res)
},
error:function(e){
console.log(e)
}
})
</script>
</body>
</html>
html

运行结果:获取到想要的数据
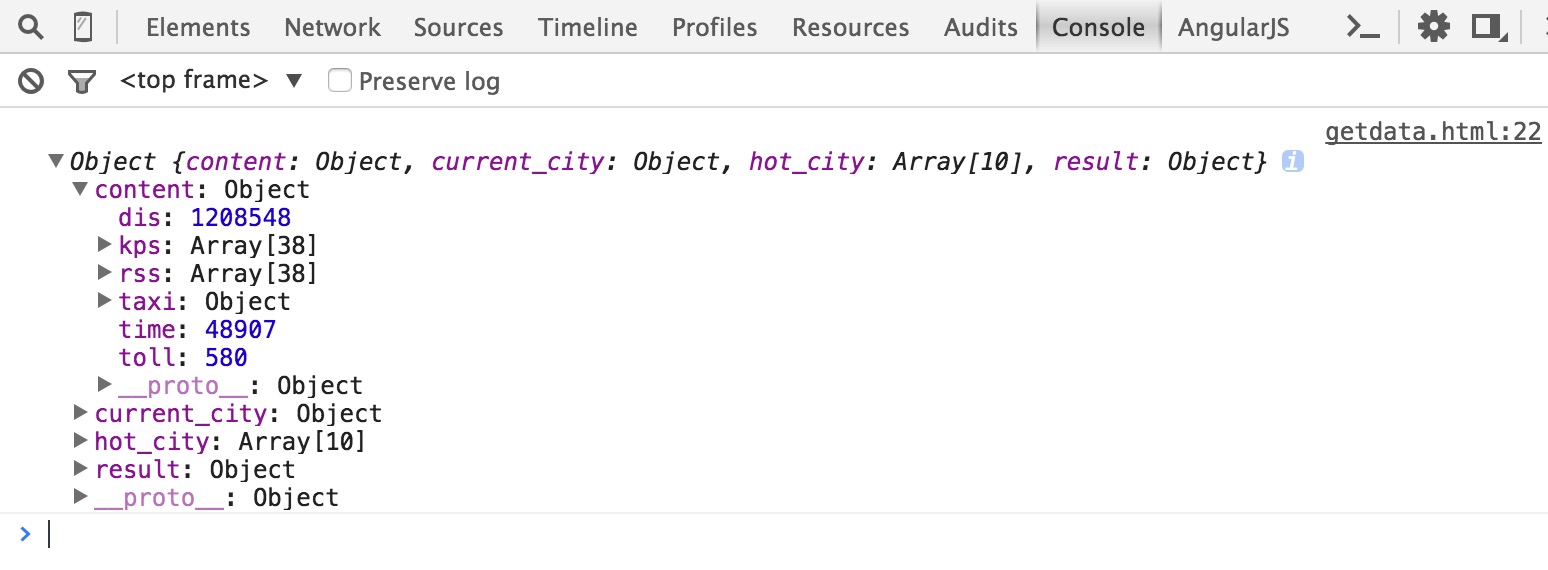
可以拿到,北京到上海的距离1208548,时间48617以及距离等。
- dis: 1208548
- kps: Array[38]
- rss: Array[38]
- taxi: Object
- time: 48617
- toll: 580
方法二:CORS
除了方法以利用jsonp跨域外,还可以通过服务器做一个代理,通过cors绕过原来资源不允许跨域的限制。
本文利用node来做服务器,原因很简单,最方便,几句代码就能搞定,方便又快捷。
var http = require('http');
var request_ = require('request');
var urlencode2=require("urlencode2");
var url=require('url')
http.createServer(function (request, response) {
var arg1 = url.parse(request.url, true).query;
var sn=arg1.sn;
var en=arg1.en;
var req_url="http://api.map.baidu.com/?qt=nav&c=131&sn=2%24%24%24%24%24%24%20"+
urlencode2(sn,'gbk')+"%24%240%24%24%24%24&en=2%24%24%24%24%24%24"+
urlencode2(en,'gbk')+"%24%240%24%24%24%24&sy=0&ie=utf-8&oue=1&fromproduct=jsapi&res=api&callback=BMap._rd._cbk54249";
request_.get({
url:req_url,
json:true
},
function(error, response_, body) {
if (!error && response_.statusCode == 200) {
var res=-1;
if(body){
res=body.split(',"toll":')[0];//time s
res=res.split('"time":')[2];
console.log(res)
if(!res){
res=-1;
}
else{
res=res/60;
}
}
response.writeHead(200, {
"Content-Type": "text/html; charset=UTF-8",
'Access-Control-Allow-Origin':request.headers.origin
});
response.end(res+'\n');
}
else{
// console.log(error)
}
}
)
}).listen(8888);
// 终端打印如下信息
console.log('Server running at http://127.0.0.1:8888/');
nodejs

其中,本文用到了request(用于发起http请求)模块和urlencode2(主要用于URLEncode)模块
request安装:
npm install request
详见:https://github.com/request/request
urlencode2安装:
详见:https://github.com/node-modules/urlencode
var http = require('http');
http.createServer(function (request, response) {
//...
response.end('welcome baby');
}).listen(8888);
这几句简单的代码就搭建了一个web服务,端口号是8888
$ node 文件名.js
在终端输入以上指令即可允许该服务。
var arg1 = url.parse(request.url, true).query;
var sn=arg1.sn;
var en=arg1.en;
var req_url="http://api.map.baidu.com/?qt=nav&c=131&sn=2%24%24%24%24%24%24%20"+
urlencode2(sn,'gbk')+"%24%240%24%24%24%24&en=2%24%24%24%24%24%24"+
urlencode2(en,'gbk')+"%24%240%24%24%24%24&sy=0&ie=utf-8&oue=1&fromproduct=jsapi&res=api&callback=BMap._rd._cbk54249";
以上是获取查询参数并拼接请求字符串
然后利用request向目标服务器发送请求,并解析出需要的信息
最重要的是以下代码:
response.writeHead(200, {
"Content-Type": "text/html; charset=UTF-8",
'Access-Control-Allow-Origin':request.headers.origin
});
response.end(res+'\n');
允许所有用户跨域访问,因此我们就能访问自己搭建的web服务了。
我在前端页面只需,请求我们的地址http://localhost:8888
并且指定sn(start node)与 en(end node)一并发送到服务器即可。
相关代码:https://github.com/AlvinWei1024/blog-resources/tree/master/20150923
作者:AlvinWei 文章出处:韦躐晟的博客 http://www.cnblogs.com/alvinwei1024/p/4834045.html
本文版权归作者和博客园共有,欢迎转载
转载请说明原文章出处
总结:
本文所用实例的百度地图api无需这么费劲去解析,可以使用其公布的公共API接口,但是每天的访问次数有10w次的限制。
nodejs抓取别人家的页面的始末的更多相关文章
- nodejs抓取页面内容,并分析有无某些内容的js文件
nodejs获取网页内容绑定data事件,获取到的数据会分几次相应,如果想全局内容匹配,需要等待请求结束,在end结束事件里把累积起来的全局数据进行操作! 举个例子,比如要在页面中找有没有www.ba ...
- 利用curl抓取远程页面内容
最基本的操作如下 $curlPost = 'a=1&b=2';//模拟POST数据$cookie_file = tempnam('./temp','kie');//可选,保存ses ...
- php curl抓取远程页面内容的代码
使用php curl抓取远程页面内容的例子. 代码如下: <?php /** * php curl抓取远程网页内容 * edit by www.jbxue.com */ $curlPost = ...
- php抓取ajax页面返回图片。
要抓取的页面:http://pic.hao123.com/ 当我们往下滚动的时候,图片是用ajax来动态获取的.这就需要我们仔细分析页面了. 可以看到,异步加载的ajax文件为: http://pic ...
- C#抓取AJAX页面的内容
原文 C#抓取AJAX页面的内容 现在的网页有相当一部分是采用了AJAX技术,所谓的AJAX技术简单一点讲就是事件驱动吧(当然这种说法可能很不全面),在你提交了URL后,服务器发给你的并不是所有是页面 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 用C#抓取AJAX页面的内容
现在的网页有相当一部分是采用了AJAX技术,不管是采用C#中的WebClient还是HttpRequest都得不到正确的结果,因为这些脚本是在服务器发送完毕后才执行的! 但我们用IE浏览页面时是正常的 ...
- c#抓取动态页面WebBrowser
在ajax横行的年代,很多网页的内容都是动态加载的,而我们的小爬虫抓取的仅仅是web服务器返回给我们的html,这其中就 跳过了js加载的部分,也就是说爬虫抓取的网页是残缺的,不完整的,下面可以看下博 ...
- nodejs抓取数据二(列表解析)
这里做得比较暴力,没有分页取出数据解析,O(∩_∩)O哈哈~,居然没有被挂机.不过解析的坑特别多...不过大部分我想要的数据都拿到了. //解析列表数据 var http = require(&quo ...
随机推荐
- php环境搭建及入门
在php文件里,写入header('content-type:text/html;charset = uft-8'); <?php header('content-type:text/html; ...
- Windows 设置开机自动登录
1. 自己一些windows的虚拟机 有时候开机之后 输入用户名密码时间特别长. 需要等待很久, 如果能够设置开机自动登录的话 能够节约很多时间. 2. 最简单的办法 运行输入 control us ...
- Docker 下 mysql 简单的 主从复制实现
1. 拉取镜像 docker pull mysql: 2. 运行这个镜像 docker run -d --name maser mysql: 3. 安装一些必要的软件 docker exec -it ...
- C# 登录窗口的设计技巧
记得很久之前要用C#做个需要登录的小东西,自己之前完全没有编写WinForm的经验,整个过程中,自己感觉应该怎么写就怎么写,时常导致许多逻辑性的错误,比如在做这个登录窗口的时候,应该实现的效果是,用户 ...
- flask再学习-重构!启动!
1.打造MVC框架: common/libs:放置一些功能公用的方法. common/models:放置ORM模型 config:配置文件属性 web/controllers:视图层,处理url和ap ...
- Courses HDU - 1083 (二分匹配模板题)
Consider a group of N students and P courses. Each student visits zero, one or more than one courses ...
- 【BZOJ1293】[SCOI2009]生日礼物(单调队列)
[BZOJ1293][SCOI2009]生日礼物(单调队列) 题面 BZOJ 洛谷 题解 离散之后随便拿单调队列维护一下就好了. #include<iostream> #include&l ...
- NOIP2018初赛提高组复习提纲(By HGOI LJC)
Download:https://pan.baidu.com/s/16khhFf_0RsUjJLETreb20w (PDF) https://pan.baidu.com/s/1BVZqLs3q1clZ ...
- 解题:CF960G Bandit Blues & FJOI 2016 建筑师
题面1 题面2 两个题推导是一样的,具体实现不一样,所以写一起了,以FJOI 2016 建筑师 的题面为标准 前后在组合意义下一样,现在只考虑前面,可以发现看到的这a个建筑将这一段划分成了a-1个区间 ...
- Libre 6010「网络流 24 题」数字梯形 (网络流,最大费用最大流)
Libre 6010「网络流 24 题」数字梯形 (网络流,最大费用最大流) Description 给定一个由n 行数字组成的数字梯形如下图所示.梯形的第一行有m 个数字.从梯形的顶部的m 个数字开 ...