oracle 11g 分区表创建(自动按年、月、日分区)
前言:工作中有一张表一年会增长100多万的数据,量虽然不大,可是表字段多,所以一年下来也会达到 1G,而且只增不改,故考虑使用分区表来提高查询性能,提高维护性。
oracle 11g 支持自动分区,不过得在创建表时就设置好分区。
如果已经存在的表需要改分区表,就需要将当前表 rename后,再创建新表,然后复制数据到新表,然后删除旧表就可以了。
一、为什么要分区(Partition)
1、一般一张表超过2G的大小,ORACLE是推荐使用分区表的。
2、这张表主要是查询,而且可以按分区查询,只会修改当前最新分区的数据,对以前的不怎么做删除和修改。
3、数据量大时查询慢。
4、便于维护,可扩展:11g 中的分区表新特性:Partition(分区)一直是 Oracle 数据库引以为傲的一项技术,正是分区的存在让 Oracle 高效的处理海量数据成为可能,在 Oracle 11g 中,分区技术在易用性和可扩展性上再次得到了增强。
5、与普通表的 sql 一致,不需要因为普通表变分区表而修改我们的代码。
二、oracle 11g 如何按天、周、月、年自动分区
2.1 按年创建
numtoyminterval(1, 'year')
--按年创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (numtoyminterval(1, 'year'))
(partition part_t01 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
-- Create/Recreate indexes
create index test_part_create_time on TEST_PART (create_time);
2.2 按月创建
numtoyminterval(1, 'month')
--按月创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (numtoyminterval(1, 'month'))
(partition part_t01 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
2.3 按天创建
NUMTODSINTERVAL(1, 'day')
--按天创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (NUMTODSINTERVAL(1, 'day'))
(partition part_t01 values less than(to_date('2018-11-12', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
2.4 按周创建
NUMTODSINTERVAL (7, 'day')
--按周创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (NUMTODSINTERVAL (7, 'day'))
(partition part_t01 values less than(to_date('2018-11-12', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
2.5 测试
可以添加几条数据来看看效果,oracle 会自动添加分区。
--查询当前表有多少分区
select table_name,partition_name from user_tab_partitions where table_name='TEST_PART'; --查询这个表的某个(SYS_P21)里的数据
select * from TEST_PART partition(SYS_P21);
三、numtoyminterval 和 numtodsinterval 的区别
3.1 numtodsinterval(<x>,<c>) ,x 是一个数字,c 是一个字符串。
把 x 转为 interval day to second 数据类型。
常用的单位有 ('day','hour','minute','second')。
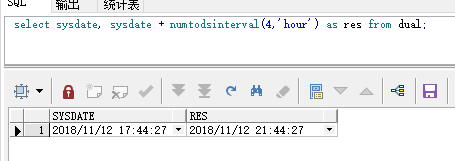
测试一下:
select sysdate, sysdate + numtodsinterval(4,'hour') as res from dual;
结果:
3.2 numtoyminterval (<x>,<c>)
将 x 转为 interval year to month 数据类型。
常用的单位有 ('year','month')。
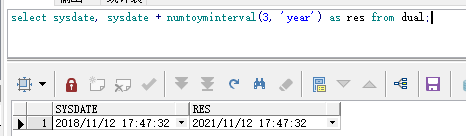
测试一下:
select sysdate, sysdate + numtoyminterval(3, 'year') as res from dual;
结果:
四、默认分区
4.1 partition part_t01 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))。
表示小于 2018-11-01 的都放在 part_t01 分区表中。
五、给已有的表分区
需要先备份表,然后新建这个表,拷贝数据,删除备份表。
-- 1. 重命名
alter table test_part rename to test_part_temp; -- 2. 创建 partition table
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (numtoyminterval(1, 'month'))
(partition part_t1 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))); -- 3. 创建主键
alter table test_part add constraint test_part_pk_1 primary key (ID) using INDEX; -- 4. 将 test_part_temp 表里的数据迁移到 test_part 表中
insert into test_part_temp select * from test_part; -- 5. 为分区表设置索引
-- Create/Recreate indexes
create index test_part_create_time_1 on TEST_PART (create_time); -- 6. 删除老的 test_part_temp 表
drop table test_part_temp purge; -- 7. 作用是:允许分区表的分区键是可更新。
-- 当某一行更新时,如果更新的是分区列,并且更新后的列植不属于原来的这个分区,
-- 如果开启了这个选项,就会把这行从这个分区中 delete 掉,并加到更新后所属的分区,此时就会发生 rowid 的改变。
-- 相当于一个隐式的 delete + insert ,但是不会触发 insert/delete 触发器。
alter table test_part enable row movement;
六、全局索引和 Local 索引
我的理解是:
当查询经常跨分区查,则应该使用全局索引,因为这是全局索引比分区索引效率高。
当查询在一个分区里查询时,则应该使用 local 索引,因为本地索引比全局索引效率高。
扩展:https://blog.csdn.net/lively1982/article/details/9398485
分区索引:
https://www.cnblogs.com/grefr/p/6095005.html
https://blog.csdn.net/w892824196/article/details/82803889
oracle 11g 分区表创建(自动按年、月、日分区)的更多相关文章
- Oracle 11g R2创建数据库之手工建库方式
在之前的博文当中梳理了关于DBCA静默方式创建数据库的过程,本文就手工通过SQL*PLUS客户端采用CREATE DATABASE语句创建数据库.这种建库方式就是完全使用手工SQL语句创建数据库,通常 ...
- oracle 11g中的自动维护任务管理
因为人员紧缺,最近又忙着去搞性能优化的事情,有时候真的是不想再搞这个事情,只是没办法,我当前的绩效几乎取决于这个项目的最终成绩,所以不管是人的事还是事的事,都得去让他顺利推进. 前段时间发生还有几台服 ...
- oracle 11g 如何创建、修改、删除list-list组合分区
Oracle11g在分区方面做了很大的提高,不但新增了4种复合分区类型,还增加了虚拟列分区.系统分区.INTERVAL分区等功能. 9i开始,Oracle就包括了2种复合分区,RANGE-HASH和R ...
- Oracle 11g R2创建数据库之DBCA静默方式
通常创建Oracle数据库都是通过DBCA(Database Configuration Assistant)工具完成的,DBCA工具可以通过两种方式完成建库任务,即图形界面方式和静默命令行方式.既然 ...
- oracle 11g dataguard创建的简单方法
oracle 10g可以通过基于备份的rman DUPLICATE实现dataguard,通过步骤需要对数据库进行备份,并在standby侧进行数据库的恢复.而到了11g,oracle推出了Dupli ...
- oracle 11g 分区表
查看所有用户分区表及分区策略(1.2级分区表均包括): SELECT p.table_name AS 表名, decode(p.partitioning_key_count, 1, '主分区') AS ...
- oracle 11g数据库--创建表空间,创建用户,用户授权并指定表空间。
使用环境:我们安装完数据库后,查看以下服务是否启动 需要建库.实质上我们是建立表空间,从而进行库的还原工作. 根据本例情况,是在下面目录下进行的操作. D:\app\Administrator\ora ...
- Oracle 11g中创建实例
1.打开“所有程序” -> “Oracle -OraDb11g_home1” -> “配置移植工具” -> “Database Configuration Assistant”. ...
- Oracle 11g之创建和管理表练习
创建表: SQL> create table name (empno number(4), ename VARCHAR2(10)); 查看表结构: desc name; SQL> desc ...
随机推荐
- Python3.5 学习二十
学会用三种方法检索数据 1.对象方式 2.字典方式 3.元组方式 models后面,如果是.values() 则为字典方式 如果是value_list() 则为元组方式 跨表操作时,如果是对象,可以用 ...
- zookeeper的命令使用
这篇是接着上篇zookeeper集群做的,所以有不熟悉的可以返回看下zookeeper集群的相关内容. 这里是相关的命名行使用方法: 基本命令用法 连接server zkCli.sh -server ...
- Shell - 简明Shell入门13 - 用户输入(UserInput)
示例脚本及注释 1 - arguments #!/bin/bash if [ -n "$1" ];then # 验证参数是否传入 echo "The first para ...
- mysql之视图,存储过程,触发器,事务
视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,可以将该结果集当做表来使用. 使用视图我们可以把查询过程中的临时 ...
- linux安装使用7zip
7z,全称7-Zip, 是一款开源软件.是目前公认的压缩比例最大的压缩解压软件. 源码编译安装 官网下载地址:http://www.7-zip.org/download.html 源文件项目地址:ht ...
- JS获取客户端IP地址、MAC和主机名的7个方法汇总
今天在搞JS(javascript)获取客户端IP的小程序,上网搜了下,好多在现在的系统和浏览器中的都无效,很无奈,在Chrome.FireFox中很少搞到直接利用ActiveX获取IP等的JS脚本. ...
- odoo开发笔记 -- 官方模块一览表
模块名称 技术名称 作者 电子发票管理 account OpenERP SA 会计与财务 account_accountant OpenERP SA 合同管理 account_analytic_ana ...
- Android通用简洁的下载器
下载逻辑在android开发中可谓很常见,那么封装一个通用简洁的下载器时很有必要的.如果不想给工程引入一个很重的jar包那么可以直接复用下面的代码即可. 主要对外接口 构造函数 : publi ...
- 一、Linq简介
语言集成查询Language Integrated Query(LINQ)是一系列将查询功能集成到C#语言的技术统称. 传统数据查询的缺点: 简单的字符串查询,没有编译时类型检查或Intellisen ...
- storm_分组策略
注意1:原始的案例 spout 和bolt都是1个并发 所以文件中30条日志 从spout发出以后 bolt接受到30条