我的Python成长之路---第四天---Python基础(16)---2016年1月23日(寒风刺骨)
四、正则表达式
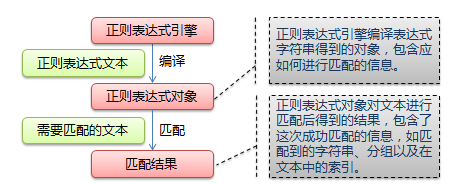
1、Python支持的正则表达式元字符和语法
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| 字符 | |||
| 一般字符 | 匹配自己 | abc | abc |
| . | 匹配任意字符“\n”除外 DOTALL模式中(re.DOTALL)也能匹配换行符 |
a.b | abc或abc或a1c等 |
| [...] | 字符集[abc]表示a或b或c,也可以-表示一个范围如[a-d]表示a或b或c或d | a[bc]c | abc或adc |
| [^...] | 非字符集,也就是非[]里的之外的字符 | a[^bc]c | adc或aec等 |
| 预定义字符集(也可以系在字符集[...]中) | |||
| \d | 数字:[0-9] | a\dc | a1c等 |
| \D | 非数字:[^0-9]或[^\d] | a\Dc | abc等 |
| \s | 空白字符:[<空格>\t\n\f\v] | a\sc | a b等 |
| \S | 非空白字符:[^s] | a\Sc | abc等 |
| \w | 字母数字(单词字符)[a-zA-Z0-9] | a\wc | abc或a1c等 |
| \W | 非字母数字(非单词字符)[^\w] | a\Wc | a.c或a_c等 |
| 数量词(用在字符或(...)分组之后) | |||
| * | 匹配0个或多个前面的表达式。(注意包括0次) | abc* | ab或abcc等 |
| + | 匹配1个或多个前面的表达式。 | abc+ | abc或abcc等 |
| ? | 匹配0个或1个前面的表达式。(注意包括0次) | abc? | ab或abc |
| {m} | 匹配m个前面表达式(非贪婪) | abc{2} | abcc |
| {m,} | 匹配至少m个前面表达式(m至无限次) | abc{2,} | abcc或abccc等 |
| {m,n} | 匹配m至n个前面的表达式 | abc{1,2} | abc或abcc |
| 边界匹配(不消耗待匹配字符中的字符) | |||
| ^ | 匹配字符串开头,在多行模式中匹配每一行的开头 | ^abc | abc或abcd等 |
| $ | 匹配字符串结尾,在多行模式中匹配每一行的结尾 | abc$ | abc或123abc等 |
| \A | 仅匹配字符串开头 | \Aabc | abc或abcd等 |
| \Z | 仅匹配字符串结尾 | abc\Z | abc或123abc等 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 | ||
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 | ||
| 逻辑、分组 | |||
| | | 或左右表达式任意一个(短路)如果|没有在()中表示整个正则表达式(注意有括号和没括号的区别) | abc|def ab(c|d)ef |
abc或def abcef或abdef |
| (...) | 分组,可以用来引用,也可以括号内的被当做一组进行数量匹配后接数量词 | (abc){2}a | abcabca |
| (?P<name>...) | 分组别名,给分组起个名字,方便后面调用 | ||
| \<number> | 引用编号为<number>的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (\d)abc\1 | 1ab1或5ab5等 |
| (?=name) | 引用别名为name的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (?P<id>\d)abc(?P=id) | 1ab1或5ab5等 |
2、数量词的贪婪模式与分贪婪模式
3、python的re模块
import re # 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello') # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!') if match:
# 使用Match获得分组信息
print match.group()
hello
macth = re.match('hello', 'hello world')
if match:
print match.group()
4、re模块的常用方法
re.compile(strPattern[, flag])
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
>>> import re
>>> s = 'hello world'
>>> print(re.match('ello', s))
None
>>> print(re.search('ello',s ))
<_sre.SRE_Match object; span=(1, 5), match='ello'>
说明:可以看到macth只匹配开头,开头不匹配,就不算匹配到,search则可以从中间,只要能有匹配到就算匹配
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。有点像search的扩展,把所有匹配的子串放到一个列表
参数:同match
返回值:所有匹配的子串,没有匹配则返回空列表
>>> import re
>>> s = 'one1two2three3four4'
>>> re.findall('\d+', s)
['', '', '', '']
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
>>> import re
>>> s = 'one1two2three3four4'
>>> re.split('\d+', s)
['one', 'two', 'three', 'four', '']
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
if __name__ == '__main__':
import re
s = '--(1.1+1+1-(-1)-(1+1+(1+1+2.2)))+-----111+--++--3-+++++++---+---1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3'
def replace_sign(expression):
'''
替换多个连续+-符号的问题,例如+-----,遵循奇数个负号等于正否则为负的原则进行替换
:param expression: 表达式,包括有括号的情况
:return: 返回经过处理的表达式
'''
def re_sign(m):
if m:
if m.group().count('-')%2 == 1:
return '-'
else:
return '+'
else:
return ''
expression = re.sub('[\+\-]{2,}', re_sign, expression)
return expression s = replace_sign(s)
print(s)
执行结果
24 +(1.1+1+1-(-1)-(1+1+(1+1+2.2)))-111+3-1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3
我的Python成长之路---第四天---Python基础(16)---2016年1月23日(寒风刺骨)的更多相关文章
- 我的Python成长之路---第四天---Python基础(15)---2016年1月23日(寒风刺骨)
二.装饰器 所谓装饰器decorator仅仅是一种语法糖, 可作用的对象可以是函数也可以是类, 装饰器本身是一个函数, 其主要工作方式就是将被装饰的类或者函数当作参数传递给装饰器函数.本质上, ...
- 我的Python成长之路---第四天---Python基础(14)---2016年1月23日(寒风刺骨)
一.生成器和迭代器 1.迭代器 迭代器是访问集合元素的一种方式.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退. ...
- 我的Python成长之路---第三天---Python基础(13)---2016年1月16日(雾霾)
五.Python的常用的内置函数 Python为我们准备了大量的内置函数,如下图所示 这里我们只讨论红框内的内置函数 abs(x) 返回一个数的绝对值(模),参数可以是真说或浮点数 >>& ...
- python成长之路——第四天
内置函数: callable:查看对象是否能被调用(对象是函数的话能被调用) #callable def f1(): pass f2="a" print(callable(f1)) ...
- 我的Python成长之路---第七天---Python基础(21)---2016年2月27日(晴)
四.面向对象进阶 1.类方法 普通的方法通过对象调用,至少有一个self参数(调用的时候系统自动传递,不需要手工传递),而类方法由类直接调用,至少有一个cls参数,执行时,自动将调用该方法的类赋值个c ...
- 我的Python成长之路---第三天---Python基础(12)---2016年1月16日(雾霾)
四.函数 日常生活中,要完成一件复杂的功能,我们总是习惯把“大功能”分解为多个“小功能”以实现.在编程的世界里,“功能”可称呼为“函数”,因此“函数”其实就是一段实现了某种功能的代码,并且可以供其它代 ...
- 我的Python成长之路---第三天---Python基础(11)---2016年1月16日(雾霾)
三.深浅拷贝 在Python中将一个变量的值传递给另外一个变量通常有三种:赋值.浅拷贝以及深拷贝 讨论深浅拷贝之前我们把Python的数据类型分为基本数据类型包括数字.字符串.布尔以及None等,还有 ...
- 我的Python成长之路---第三天---Python基础(10)---2016年1月16日(雾霾)
二.collections collections是对Python现有的数据类型的补充,在使用collections中的对象要先导入import collections模块 1.Counter——计数 ...
- Python高手之路【四】python函数装饰器
def outer(func): def inner(): print('hello') print('hello') print('hello') r = func() print('end') p ...
随机推荐
- 加密PHP文件的方式,目测这样可以写个DLL来加密了
<?php function encode_file_contents($filename) { $type=strtolower(substr(strrchr($filename,'.'),1 ...
- idea中使用sbt构建scala项目及依赖
1.安装scala插件 http://www.cnblogs.com/yrqiang/p/5310700.html 2. 详细了解sbt: http://www.scala-sbt.org/0.13/ ...
- java集合分析(转载)
参考文章:浅谈Java中的Set.List.Map的区别 Java 7 Collections详解 java中集合分为三类: Set(集) List(列表) Map(映射) Set和List继承自Co ...
- IOS 定位服务与地图的应用开发
1.定位服务 现在的移动设备很多都提供定位服务,IOS设备提供3种不同定位途径: (1)WiFi定位,通过查询一个WiFi路由器的地理位置的信息,比较省电:IPhone,IPod touch和IPad ...
- win7 原版下载&激活
参考http://bbs.ithome.com/thread-478939-1-1.html品牌机 win7 32 位系下载http://bbs.ithome.com/forum.php?mod=vi ...
- xp的停止更新对我们有什么影响?
微软与2001年推出windows xp系统,这款系统的成功毋庸置疑,但由于太过成功,微软在随后推出的vista系统和win7系统普及起来却异常困难.大多数人已经习惯了xp的操作,再加上一批铁杆旧电脑 ...
- [转] tomcat组成及工作原理
1 - Tomcat Server的组成部分 1.1 - Server A Server element represents the entire Catalina servlet containe ...
- QTableView另类打印解决方案(复用render函数去解决print问题)
Qt QTableView另类打印解决方案 上回书说道Qt的model/view,我就做了个demo用于显示数据库中的内容.没想到tableview的打印竟然成了问题.我困惑了,难道Qt不应该 ...
- 关于 OnCloseQuery: 顺序、不能关机等(所有的windows的广播消息都是逐窗口传递的)——如果一个窗体的OnCloseQuery事件中如果写了代码那么WM_QUERYENDSESSION消息就传不过去了msg.result会返回0,关机事件也就停止了
系统关闭窗体的事件顺序为: OnCloseQuery ----> OnClose ----> OnDestroy 下面的代码说明问题: unit Unit3; interface uses ...
- 通往WinDbg的捷径
通往WinDbg的捷径(一) 原文:http://www.debuginfo.com/articles/easywindbg.html译者:arhat时间:2006年4月13日关键词:CDB WinD ...