Reinforcement learning in populations of spiking neurons
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!


Abstract
尽管存在神经元变异性,但是群体编码被广泛认为是实现可靠行为响应的重要机制。但是,随着全局奖励信号与任何单独神经元的性能越来越不相关,标准的强化学习随着群体规模的增长而减慢。我们发现,如果除了全局奖励之外,有关群体响应的反馈能够调节突触可塑性,则学习会随着群体规模的增加而加快。
已经深入研究了神经元群体在编码感觉刺激中的作用1,2。但是,大多数带有脉冲神经元的强化学习模型都只关注单独神经元或小的神经元组件3-6。此外,以下结果表明,此类模型无法随群体规模很好地扩展。在大型网络中,使用由全局奖励调节的脉冲时间依赖可塑性,需要100次学习试验才能以80%的概率正确地将单个刺激与两个响应之一相关联,并且在进行更多训练后性能不会提高7。相比之下,行为结果表明,强化学习可以是可靠且快速的。猕猴对仅12次试验进行了平均后,就正确地将四个复杂视觉场景之一与四个目标响应之一相关联8。
人工智能中的程序(例如,反向传播算法)不像在强化学习中那样简单地广播全局奖励信号,而是使用涉及的机制来生成针对每个神经元量身定制的反馈信号。我们发现,这种生物学上不切实际的程序与标准强化之间存在广阔的中间地带。在这里,我们提出了一种学习规则,其中不仅通过奖励来调节可塑性,而且通过编码群体活动的单个额外反馈信号来调节可塑性。突触通过周围神经递质的浓度接收两个信号,从而导致在线可塑性规则,在此规则中,第一个刺激的学习与后续刺激的处理同时发生。现在,随着群体数量的增加,学习速度加快,而不是像标准强化那样恶化。
我们研究了N个神经元的群体,这些神经元学习有关突触前输入的决策任务(在线补充图1)。输入模式由持续时间为500ms的50个脉冲序列(平均频率为6Hz)组成。 作为随机投影的结果,N个突触后神经元中的每一个都从50个突触前脉冲序列中的大约40个接收输入。因此,输入从一个神经元到另一个神经元变化,但高度相关。不同的神经元会产生不同的突触后脉冲序列,并且将这些响应汇总到群体决策中必须与神经元如何编码信息相匹配。我们假设了一个评分函数c(Yv),该函数为由神经元v的刺激诱发的突触后脉冲序列Yv分配了一个数值。利用这个函数,汇聚响应就等于添加突触后评分以获得群体活动的度量P。在纯频率编码中,例如,c(Yv)是神经元v发放的脉冲次数,P是群体脉冲的总数,可以通过将P与阈值进行比较来得出群体决策。在这里,我们将重点讨论脉冲或无脉冲编码的简单情况,其中c(Yv)仅记录神经元是否响应刺激而发放。为方便起见,如果神经元未发放,则设置c(Yv) = -1;如果神经元发放,则设置c(Yv) = 1。群体决策(以及行为决策)由大多数神经元决定。如果超过一半的神经元响应刺激而发放,这就等于1,否则就等于-1。在正规形式里,群体决策是P的符号,即脉冲或无脉冲评分的总和。
在强化学习中,随机神经元处理使人们能够探索对给定刺激的不同响应。奖励信号R提供有关群体决策是否正确(R = 1)或不正确(R = -1)的环境反馈。可塑性由该全局反馈信号和每个突触处局部计算量(称为资格迹)驱动。在我们的仿真中,我们使用了逃逸噪声神经元5,它是LIF神经元,具有随机波动的脉冲阈值。对于此模型,突触的资格迹取决于突触前和突触后脉冲的时间以及胞体电位(在线补充方法)。
我们首先考虑了一个标准的强化学习规则,其中每个突触的强度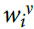 (i是突触索引,n是神经元索引)由以下等式改变:
(i是突触索引,n是神经元索引)由以下等式改变:
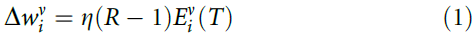
在这里,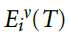 是资格迹,在刺激结束且变化发生的时间T进行评估。比例常数η称为学习率。作为R - 1项的结果,如果群体决策正确(R = 1),则不会发生任何变化。但是对于R = -1,该变化通过降低神经元在进一步的试验中以相同的刺激再现相同的突触后脉冲序列的可能性,从而激励了新的响应。
是资格迹,在刺激结束且变化发生的时间T进行评估。比例常数η称为学习率。作为R - 1项的结果,如果群体决策正确(R = 1),则不会发生任何变化。但是对于R = -1,该变化通过降低神经元在进一步的试验中以相同的刺激再现相同的突触后脉冲序列的可能性,从而激励了新的响应。
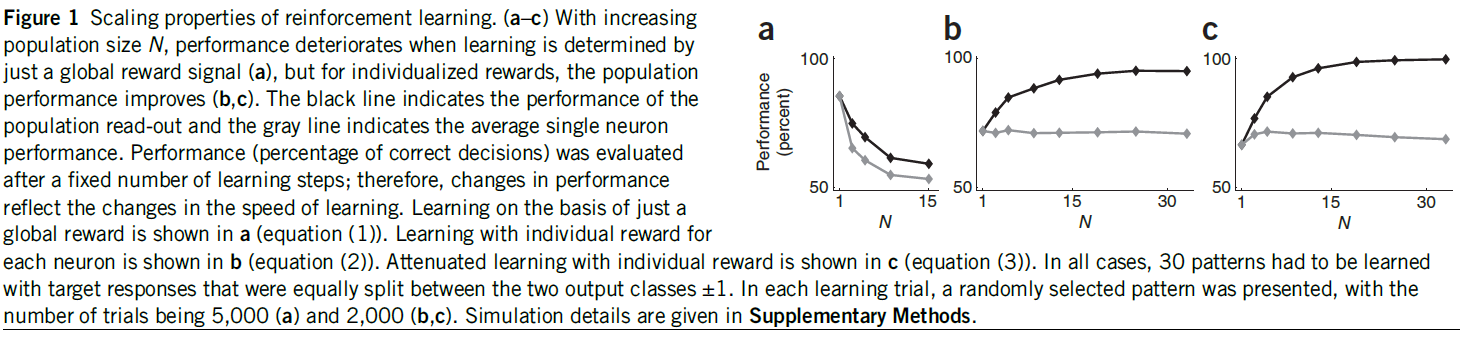
图1:强化学习的缩放特性。(a–c)随着群体数量N的增加,仅通过全局奖励信号确定学习时,性能会下降(a),但是对于单独奖励,群体性能会提高(b, c)。黑线表示群体读出的性能,而灰线表示单独神经元的平均性能。经过一定数量的学习步骤后,对性能(正确决策的百分比)进行评估;因此,性能的变化反映了学习速度的变化。a展示出仅基于全局奖励的学习(等式(1))。b展示出对每个神经元的单独奖励学习(等式(2))。带有单独奖励的衰减学习显示在c中(等式(3))。在所有情况下,必须学习30种模式,目标响应在两个输出类别±1之间平均划分。在每个学习试验中,都会呈现一个随机选择的模式,试验数量为5000(a)和2000(b, c)。仿真细节在补充方法中给出。
我们确定了针对不同的群体规模N(图1a)使用此规则实现的群体性能(正确决策的百分比),并将其与单独神经元的性能进行了比较。尽管群体性能优于单独神经元的平均,但随着N的增加,两种性能度量均迅速下降。原因很简单。从单独神经元的角度来看,全局奖励信号R是一种不可靠的性能度量,因为神经元可能会由于其他神经元犯的错误而对正确的响应进行惩罚,并且这种情况发生的概率会随着群体规模的增加而增加。
用人的术语来说,标准强化类似于让班级的学生参加考试,然后仅告诉他们班级的大多数是通过还是未通过,而对个别成绩进行保密。一个明显的替代方法是单独训练神经元,并且仅使用群体读数来提高性能。为此,我们假设一个单独的奖励信号rv = ±1,表明神经元v是否做正确的事情并对突触的变化使用:
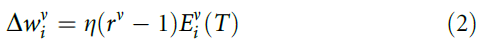
因此,单独神经元的平均性能是恒定的,但是随着N增加,群体性能得以改进到95±1%(图1b)。尽管单独奖励的效果远胜于全局奖励,但是群体增长的确会发生饱和,因为神经元将倾向于犯同样的错误,因为他们都在尝试学习相同的东西。
为了增加群体增长,我们考虑一旦群体决定是可靠和正确的,学习就会衰减。可靠性与群体活动P(神经元评分的总和)相关。如果P的量级很大(与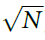 相比),则由于带噪的神经处理,P的符号(即群体决定)不太可能波动。如果响应也正确,那么即使某些神经元响应不正确,也几乎不需要进一步学习。因此,我们引入了衰减因子a并考虑了学习规则:
相比),则由于带噪的神经处理,P的符号(即群体决定)不太可能波动。如果响应也正确,那么即使某些神经元响应不正确,也几乎不需要进一步学习。因此,我们引入了衰减因子a并考虑了学习规则:
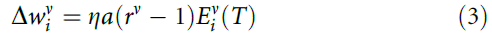
如果R = 1,则有a = exp(-P2/N)。否则,对于错误的群体决策,则有a = 1。该规则不再试图迫使所有神经元对所有刺激正确响应。因此,任何给定的神经元都可以专注于刺激的某个子集,从而导致分工。现在,随着群体规模的增加,性能达到了理想值(图1c)。等式(3)可以理解为梯度下降法则(补充方法)。
衰减学习似乎需要生物学上难以置信的数量的反馈信号。但是,如果每个神经元都保留了其过去的活动,则仅需要两个反馈信号,即全局奖励和群体活动。例如,如果群体中的大多数神经元错误地发放脉冲(P > 0,R = -1),则保持沉默(c(Yv) = -1)的神经元v做的是正确的事情。因此,其单独奖励为rv = 1。更一般而言,单独奖励为:

在此基础上,我们现在提供等式(3)的完全在线版本,该等式显式地建模反馈的传播。与上面的episodic规则相反,这些episodic规则假定突触变化是由刺激结束立即触发的,而在线版本则考虑了反馈传播的延迟和正在进行的神经元活动之间的相互作用。
从对突触可塑性调节的实验工作中得到信号10,11,我们假设R和P由周围神经递质水平的变化编码。为了获得奖励,可塑性由浓度变量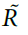 调节,浓度变量是瞬时信号R的低通滤波形式。在没有强化作用的情况下,神经递质信号奖励(例如多巴胺)的浓度保持在稳态水平(= 0),其中基准释放率通过指数衰减来平衡。强化导致释放率的瞬时变化,导致浓度与其稳态水平的瞬时偏差(≠ 0;图2a)。类似地,经由具有浓度变量
调节,浓度变量是瞬时信号R的低通滤波形式。在没有强化作用的情况下,神经递质信号奖励(例如多巴胺)的浓度保持在稳态水平(= 0),其中基准释放率通过指数衰减来平衡。强化导致释放率的瞬时变化,导致浓度与其稳态水平的瞬时偏差(≠ 0;图2a)。类似地,经由具有浓度变量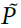 的第二神经递质提供关于群体活动P的反馈。对于,我们还假设释放率的变化(以及本身)随P值的增加而衰减(补充方法)。对于记忆机制,使每个神经元能够确定其评分c(Yv),我们假设类似钙的变量sv。当神经元不发放时,sv以500ms的时间常数τM呈指数衰减。如果在时间t有突触后脉冲,它将更新为sv(t) = 1。因此,sv的值与自上一次脉冲以来经过的时间直接相关。
的第二神经递质提供关于群体活动P的反馈。对于,我们还假设释放率的变化(以及本身)随P值的增加而衰减(补充方法)。对于记忆机制,使每个神经元能够确定其评分c(Yv),我们假设类似钙的变量sv。当神经元不发放时,sv以500ms的时间常数τM呈指数衰减。如果在时间t有突触后脉冲,它将更新为sv(t) = 1。因此,sv的值与自上一次脉冲以来经过的时间直接相关。
现在,突触可以使用以下公式读出等式(4)中单独奖励信号rv的近似值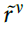 :
:
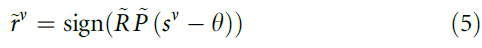
为了很好地选择阈值θ(和时间常数τM),试验后 的值立即等于rv。但是,由于正在进行的活动,
的值立即等于rv。但是,由于正在进行的活动, 会随时间变化(图2b)。为了解决这个问题,我们引入了有效学习率
会随时间变化(图2b)。为了解决这个问题,我们引入了有效学习率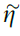 ,该学习率由奖励变量的大小调节,并使用可塑性规则:
,该学习率由奖励变量的大小调节,并使用可塑性规则:
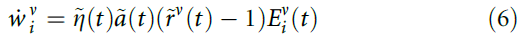
其中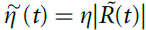 。的调节将更新限制在一个时间窗口内,因为在每次试验结束后约100ms,已经接近于0。因此,突触可以进一步使用资格迹的瞬时值
。的调节将更新限制在一个时间窗口内,因为在每次试验结束后约100ms,已经接近于0。因此,突触可以进一步使用资格迹的瞬时值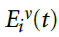 ,而不是记住
,而不是记住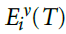 ,即迹在试验终点时的值。因为我们假设当群体多数很大时,衰减,对于正确的响应(> 0),设置
,即迹在试验终点时的值。因为我们假设当群体多数很大时,衰减,对于正确的响应(> 0),设置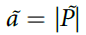 ,并且对于< 0,
,并且对于< 0,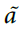 = 1实现了学习的衰减。
= 1实现了学习的衰减。
等式(6)的性能与episodic版本的性能非常相似(图2c)。学习后,突触后脉冲时间分布相当均匀(图2c),表明群体决策考虑了刺激的整个时间范围。尽管τM不再与刺激持续时间精确匹配,但在线程序在可变长度的刺激下也表现良好(图2c)。为了进一步检查鲁棒性,我们假设奖励信息本身仅在每个试验结束后100ms可用(有效地将图2a中的黄色曲线向右移动了刺激持续时间的20%),然后模拟了延迟补强。现在在随后的试验中出现了奖励发作,但是尽管学习速度变慢,但仍达到了完美的性能(图2c)。为了专注于鲁棒性,我们在在线过程中为这三个任务使用了相同的参数值。
作为特定的神经元模型,我们使用了逃逸噪声神经元5,但是我们的方法可以很容易地在单独神经元水平上适应于其他强化程序3,4,6。的确,对于episodic学习,神经元甚至可以是速度加速器。绝对而言,群体性能显然将取决于神经元模型和可塑性规则的细节,但是关于学习性能随群体规模的变化,我们希望我们的发现具有普遍性。
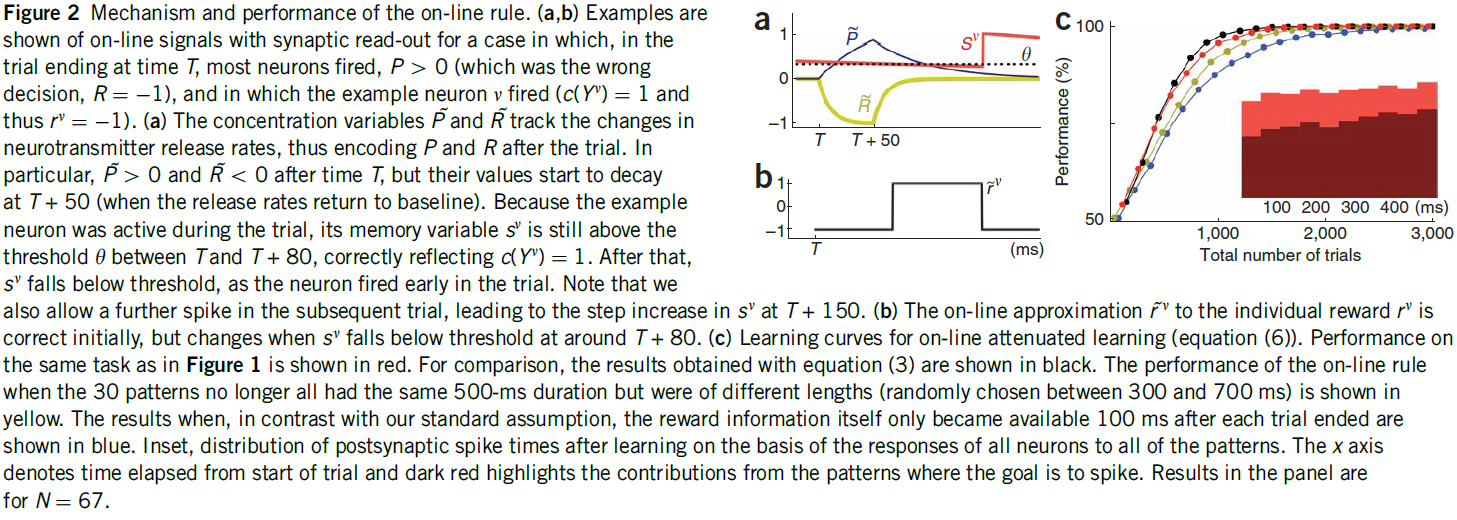
图2:在线规则的机制和性能。(a, b)显示了在以下情况下具有突触读数的在线信号的示例,在时间T的试验终点中,大多数神经元发放,P > 0(这是错误的决定,R = -1),其中示例神经元v发放(c(Yv) = 1,因此rv = -1)。(a)浓度变量和跟踪神经递质释放率的变化,从而在试验后对和进行编码。特别地,在时间T之后> 0和> 0,但是它们的值在T + 50处开始衰减(当释放率返回基准时)。由于示例神经元在试验期间处于活动状态,因此其记忆变量sv仍在T与T + 80之间的阈值θ之上,正确反映了c(Yv) = 1。此后,随着神经元在试验早期发放,sv降至阈值以下。请注意,我们也允许在随后的试验中进一步发放脉冲,导致sv在T + 150处逐步增加。(b)对单独奖励rv的在线近似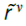 最初是正确的,但是当sv在T + 80左右下降到阈值以下时发生变化。(c)在线衰减学习的学习曲线(等式(6))。与图1相同的任务的性能以红色显示。为了进行比较,用等式(3)获得的结果以黑色显示。当30个模式不再具有相同的500ms持续时间但具有不同的长度(在300到700ms之间随机选择)时,在线规则的性能显示为黄色。与我们的标准假设相反,奖励信息本身在每次试验结束后100ms才可用的结果显示为蓝色。根据所有神经元对所有模式的响应,学习后突触后脉冲时间的分布。x轴表示从开始试验起经过的时间,深红色突出显示目标为脉冲的模式的贡献。面板中的结果为N = 67。
最初是正确的,但是当sv在T + 80左右下降到阈值以下时发生变化。(c)在线衰减学习的学习曲线(等式(6))。与图1相同的任务的性能以红色显示。为了进行比较,用等式(3)获得的结果以黑色显示。当30个模式不再具有相同的500ms持续时间但具有不同的长度(在300到700ms之间随机选择)时,在线规则的性能显示为黄色。与我们的标准假设相反,奖励信息本身在每次试验结束后100ms才可用的结果显示为蓝色。根据所有神经元对所有模式的响应,学习后突触后脉冲时间的分布。x轴表示从开始试验起经过的时间,深红色突出显示目标为脉冲的模式的贡献。面板中的结果为N = 67。
Reinforcement learning in populations of spiking neurons的更多相关文章
- Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to Atari Breakout game
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1903.11012v3 [cs.LG] 19 Aug 2019 Neural Networks, 25 November 2 ...
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- A review of learning in biologically plausible spiking neural networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Contents: ABSTRACT 1. Introduction 2. Biological background 2.1. Spik ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (zhuan) Paper Collection of Multi-Agent Reinforcement Learning (MARL)
this blog from: https://github.com/LantaoYu/MARL-Papers Paper Collection of Multi-Agent Reinforcemen ...
- Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract 在中脑多巴胺能神经元的研究中取得了许多最新进展.要了解这些进步以及它们之间的相互关系,需要对作为解释框架并指导正在进行的 ...
- Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
Reinforcement Learning 对于控制决策问题的解决思路:设计一个回报函数(reward function),如果learning agent(如上面的四足机器人.象棋AI程序)在决定 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
随机推荐
- 构建私有的verdaccio npm服务
用了很长一段时间的cnpmjs做库私有库,发现两个问题 1. 最开始是mysql对表情emoij的支持不好,但由于数据库没办法调整所以只好把第三方库都清掉,只留私有库 2. mac 上面cnpm in ...
- Python os.dup() 方法
概述 os.dup() 方法用于复制文件描述符 fd.高佣联盟 www.cgewang.com 语法 dup()方法语法格式如下: os.dup(fd); 参数 fd -- 文件描述符 返回值 返回复 ...
- PHP similar_text() 函数
实例 计算两个字符串的相似度并返回匹配字符的数目: <?php高佣联盟 www.cgewang.comecho similar_text("Hello World",&quo ...
- QDC day4
图论. 强连通图 与 弱连通图 . 最短路 .dij 不支持负权.显然 值得一提的是利用斐波那契堆m+nlogn . 一张 边权都是2的整数次幂 考虑 一下直接 结构体维护这个2的整次幂数组但比大小 ...
- Sharding-JDBC主键生成策略
当使用分库分表等功能之后,就不能再依赖数据库自带的主键生成机制了,一方面主键ID不能重复,另外需要在新增之前就知道主键ID,才能保证ID能够均匀分布到不同的数据库或数据表中,所以要使用一个合理的主键生 ...
- 一文入门人工智能的明珠:生成对抗网络(GAN)
一.简介 在人工智能领域内,GAN是目前最为潮流的技术之一,GAN能够让人工智能具备和人类一样的想象能力.只需要给定计算机一定的数据,它就可以自动联想出相似的数据.我们学习和使用GAN的原因如下: 1 ...
- Ubuntu安装海思SDK(转)
问题 海思SDK安装时,无法运行sdk.unpack 原因 BASH 和 DASH 的问题. Debian和Ubuntu中,/bin/sh默认已经指向dash,这是一个不同于bash的shell,它主 ...
- Python3.x+Fiddler抓取APP数据
随着移动互联网的市场份额逐步扩大,手机APP已经占据我们的生活,以往的数据分析都借助于爬虫爬取网页数据进行分析,但是新兴的产品有的只有APP,并没有网页端这对于想要提取数据的我们就遇到了些问题,本章以 ...
- selenium WebDriverWait类等待机制的实现
在自动化测试脚本的运行过程中,可以通过设置等待的方式来避免由于网络延迟或浏览器卡顿导致的偶然失败,常用的等待方式有三种: 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法 ...
- Python 超简单 提取音乐高潮(附批量提取)
很多时候我们想提取某首歌的副歌部分(俗称 高潮部分),只能手动直接卡点剪切,但是对于大批量的获取就很头疼,如何解决? 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后 ...