Python利用openpyxl带格式统计数据(1)- 处理excel数据
统计数据的随笔写了两篇了,再来一篇,这是第三篇,前面第一篇是用xlwt写excel数据,第二篇是用xlwt写mysql数据。先贴要处理的数据截图:

再贴最终要求的统计格式截图:
第三贴代码:
1 '''
2 #利用openpyxl向excel模板写入数据
3 '''
4 #首先写本地excel的
5 import xlwt
6 import xlrd
7 import openpyxl
8
9 #提取数据
10 xlsx = xlrd.open_workbook("要处理的数据表路径/xxx.xlsx")
11 table = xlsx.sheet_by_index(0)
12
13 #空列表,用以存储数据
14 all_data = []
15
16 #循环,读取表格的每个单元格
17 for n in range(1, table.nrows):
18 date = table.cell_value(n, 0)
19 company = table.cell_value(n, 1)
20 province = table.cell_value(n, 2)
21 price = table.cell_value(n, 3)
22 weight = table.cell_value(n, 4)
23 #print(company,price,weight)
24 #开始提取我们需要的数据并存储到字典
25 data = {'company':company, 'price':price, 'weight':weight}
26 #print(data)
27 #将上面字典的每一项以追加的方式追加到空列表all_data
28 all_data.append(data)
29
30 #print(all_data,type(all_data))
31
32 #开始从字典里读取数据
33 a_weight = [] #存储张三粮配每车重量的列表
34 a_total_price = [] #存储张三粮配每车总价格的列表
35 b_weight = []
36 b_total_price = []
37 c_weight = []
38 c_total_price = []
39 d_weight = []
40 d_total_price = []
41 for i in all_data:
42 if i['company'] == "张三粮配":
43 a_weight.append(i['weight'])
44 a_total_price.append(i['weight'] * i['price'])
45 if i['company'] == "李四粮食":
46 b_weight.append(i['weight'])
47 b_total_price.append(i['weight'] * i['price'])
48 if i['company'] == "王五小麦":
49 c_weight.append(i['weight'])
50 c_total_price.append(i['weight'] * i['price'])
51 if i['company'] == "赵六麦子专营":
52 d_weight.append(i['weight'])
53 d_total_price.append(i['weight'] * i['price'])
54 #开始按表格要求的数据细化数据
55 #首先是张三的
56 a_che = len(a_weight)
57 a_dun = sum(a_weight)
58 a_sum_price = sum(a_total_price)
59 #李四
60 b_che = len(b_weight)
61 b_dun = sum(b_weight)
62 b_sum_price = sum(b_total_price)
63 #王五
64 c_che = len(c_weight)
65 c_dun = sum(c_weight)
66 c_sum_price = sum(c_total_price)
67 #赵六
68 d_che = len(d_weight)
69 d_dun = sum(d_weight)
70 d_sum_price = sum(d_total_price)
71
72 #开始用openpyxl导入模板
73 tem_workbook = openpyxl.load_workbook("模板路径/统计表_openpyxl.xlsx") #这里注意是xlsx格式的
74 #获取工作表
75 tem_sheet = tem_workbook['Sheet1'] #这里获取的工作表就是工作簿里的第一个表,表名看清楚
76 #开始写入数据
77 #写张三的,张三的在第三行第二到第四列
78 tem_sheet['B3'] = a_che #在第三行第二列写入总车数
79 tem_sheet['C3'] = a_dun #在第三行第三列写入总吨数
80 tem_sheet['D3'] = a_sum_price #在第三行第四列写入总价格
81 #开始写李四的,李四在第四行,第二到第四列
82 tem_sheet['B4'] = b_che
83 tem_sheet['C4'] = b_dun
84 tem_sheet['D4'] = b_sum_price
85 #开始写王五,王五的在第五行,第二到第四列
86 tem_sheet['B5'] = c_che
87 tem_sheet['C5'] = c_dun
88 tem_sheet['D5'] = c_sum_price
89 #开始写赵六,赵六的在第五行,第二到第四列
90 tem_sheet['B6'] = d_che
91 tem_sheet['C6'] = d_dun
92 tem_sheet['D6'] = d_sum_price
93
94 #保存工作簿
95 tem_workbook.save('路径/2020-11-04-openpyxl-excel.xlsx')
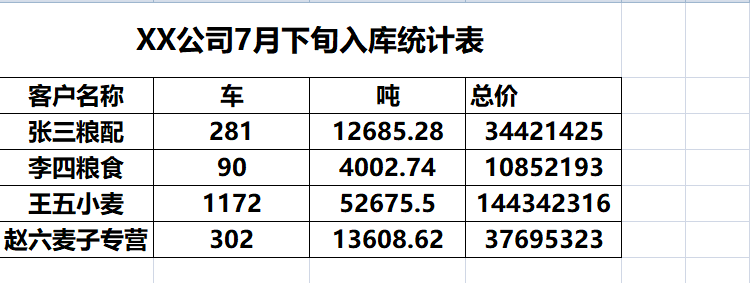
最后贴效果截图:
Python利用openpyxl带格式统计数据(1)- 处理excel数据的更多相关文章
- Python利用openpyxl带格式统计数据(2)- 处理mysql数据
上一篇些了openpyxl处理excel数据,再写一篇处理mysql数据的,还是老规矩,贴图,要处理的数据截图: 再贴最终要求的统计格式截图: 第三贴代码: 1 ''' 2 #利用openpyxl向e ...
- oracle xmltype导入并解析Excel数据 (三)解析Excel数据
包声明 create or replace package PKG_EXCEL_UTILS is -- Author: zkongbai-- Create at: 2016-07-06-- Actio ...
- 把数据库中的数据制作成Excel数据
把数据库中的数据制作成Excel数据 如果我们在使用Excel的时候,需要把数据库中的数据制作成Excel数据透视表,我们该怎么操作呢?如果数据在数据库中,我们不用把数据导入到工作表中,我们可以直接以 ...
- 数据透视:Excel数据透视和Python数据透视
作者 | leo 早于90年代初,数据透视的概念就被提出,主要的应用场景是处理大量数据的交互式汇总查询,它实现了行或列的移动,使得行可以移到列上,列移到行上,从而根据使用者的诉求取对关注的数据子集进行 ...
- python 利用jieba库词频统计
1 #统计<三国志>里人物的出现次数 2 3 import jieba 4 text = open('threekingdoms.txt','r',encoding='utf-8').re ...
- 小白学 Python 数据分析(7):Pandas (六)数据导入
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- python通过openpyxl操作excel
python 对Excel操作常用的主要有xlwt.xlrd.openpyxl ,前者xlwt主要适合于对后缀为xls比较进行写入,而openpyxl主要是针对于Excel 2007 以上版本进行操作 ...
- 办公室文员必备python神器,将PDF文件表格转换成excel表格!
[阅读全文] 第三方库说明 # PDF读取第三方库 import pdfplumber # DataFrame 数据结果处理 import pandas as pd 初始化DataFrame数据对象 ...
- oracle xmltype导入并解析Excel数据 (一)创建表与序
表说明: T_EXCEL_IMPORT_DATASRC: Excel数据存储表,(使用了xmltype存储Excel数据) 部分字段说明: BUSINESSTYPE: Excel模板类型,一个Exce ...
随机推荐
- 【mq读书笔记】如何保证三个消息文件的最终一致性。
考虑转发任务未成功执行,此时消息服务器Broker宕机,导致commitlog,consumeQueue,IndexFile文件数据不一致. commitlog,consumeQueue遍历每一条消息 ...
- c++11-17 模板核心知识(十)—— 区分万能引用(universal references)和右值引用
引子 如何区分 模板参数 const disqualify universal reference auto声明 引子 T&&在代码里并不总是右值引用: void f(Widget&a ...
- 虚拟机VM15 Ubuntu18.04写第一个c程序并实现ssh连接
输入"su",再输入密码进入根用户 1.开启ssh服务 /etc/init.d/ssh start 若没有安装会出现: (1).安装ssh apt-get install open ...
- 01_Activity生命周期及传递数据
1. Activity的生命周期: 2. Activity启动另一个Activity,并传递数据: package com.example.activitydemo; import android.a ...
- Alpha冲刺-第九次冲刺笔记
Alpha冲刺-冲刺笔记 这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzzcxy/2018SE2 这个作业要求在哪里 https://edu.cnblogs. ...
- Kubernetes Ingress-nginx使用
目录 简介 1. 部署Ingress-Controller 2. 使用Ingress规则 2.1 Ingress地址重写 2.2 配置HTTPS 2.3 黑白名单配置 2.4 匹配请求头 2.5 速率 ...
- Fist—— 团队展示
作业要求 软件工程1班 团队名称 Fist 这个作业的目标 团队合作开发项目,加强团队合作,进一步了解相应岗位. 作业正文 https://www.cnblogs.com/team4/p/137730 ...
- JZOJ2020年8月12日提高组反思
JZOJ2020年8月12日提高组反思 真·难亿一点点 T1 题目长并附带伤害-- 暴力搜 对于字符串,我选择\(Pascal\) T2 概率问题,再见 T3 样例没懂,再见 T4 有史以来见过的条件 ...
- vue上传视屏或者图片到七牛云
首先下载七牛云的JavaScript-SDK npm install qiniu-js 下载完成JavaScript-SDK以后就可以上传图片信息了 <template> <div& ...
- DockerFile理解与应用
1.DockerFile是什么? DockerFile是用来构建Docker镜像的构建文件,一般分为四部分:基础镜像信息.维护者信息.镜像操作指令和容器启动时执行指令,'#' 为 Dockerfile ...