【Hadoop】:Windows下使用IDEA搭建Hadoop开发环境
笔者鼓弄了两个星期,终于把所有有关hadoop的环境配置好了,一是虚拟机上的完全分布式集群,但是为了平时写代码的方便,则在windows上也配置了hadoop的伪分布式集群,同时在IDEA上就可以编写代码,同时在windows环境下进行运行。(如果不配置windows下的伪分布式集群,则在IDEA上编写的代码无法在windows平台下运行)。笔者在网络上找了很多有关windows下使用idea搭建hadoop开发环境的中文教程都不太全,最后使用国外的英文教程配置成功,因此这里整理一下,方便大家使用。
我的开发环境如下:
1.Windows10
2.Java 8
3.VMware-workstation-pro
1.Hadoop在windows当中的安装
首先在Windows系统里打开浏览器,下载hadoop的安装包(二进制文件):http://hadoop.apache.org/releases.html
打开网址,我们会发现这样的界面: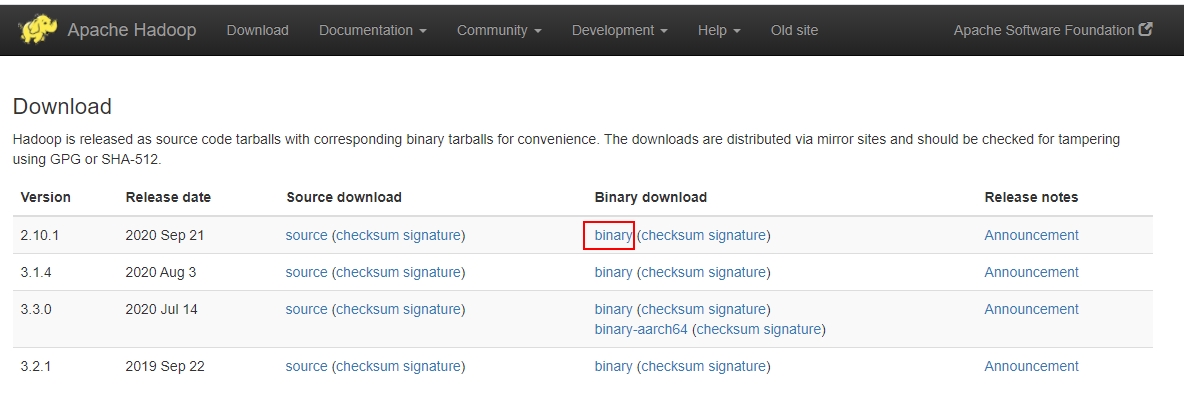
由于hadoop在开发当中我们常常使用了2.x版本的,因此这里我们这里下载2.10.1版本的。如果你想使用其他版本的进行下载,那么在下载之前需要检查以下maven仓库里是否有相应版本所对应的版本,不然在使用IDEA进行开发的时候,则无法运行。我们打开网址:https://mvnrepository.com/
在其中搜索hadoop.则会出现以下的界面:
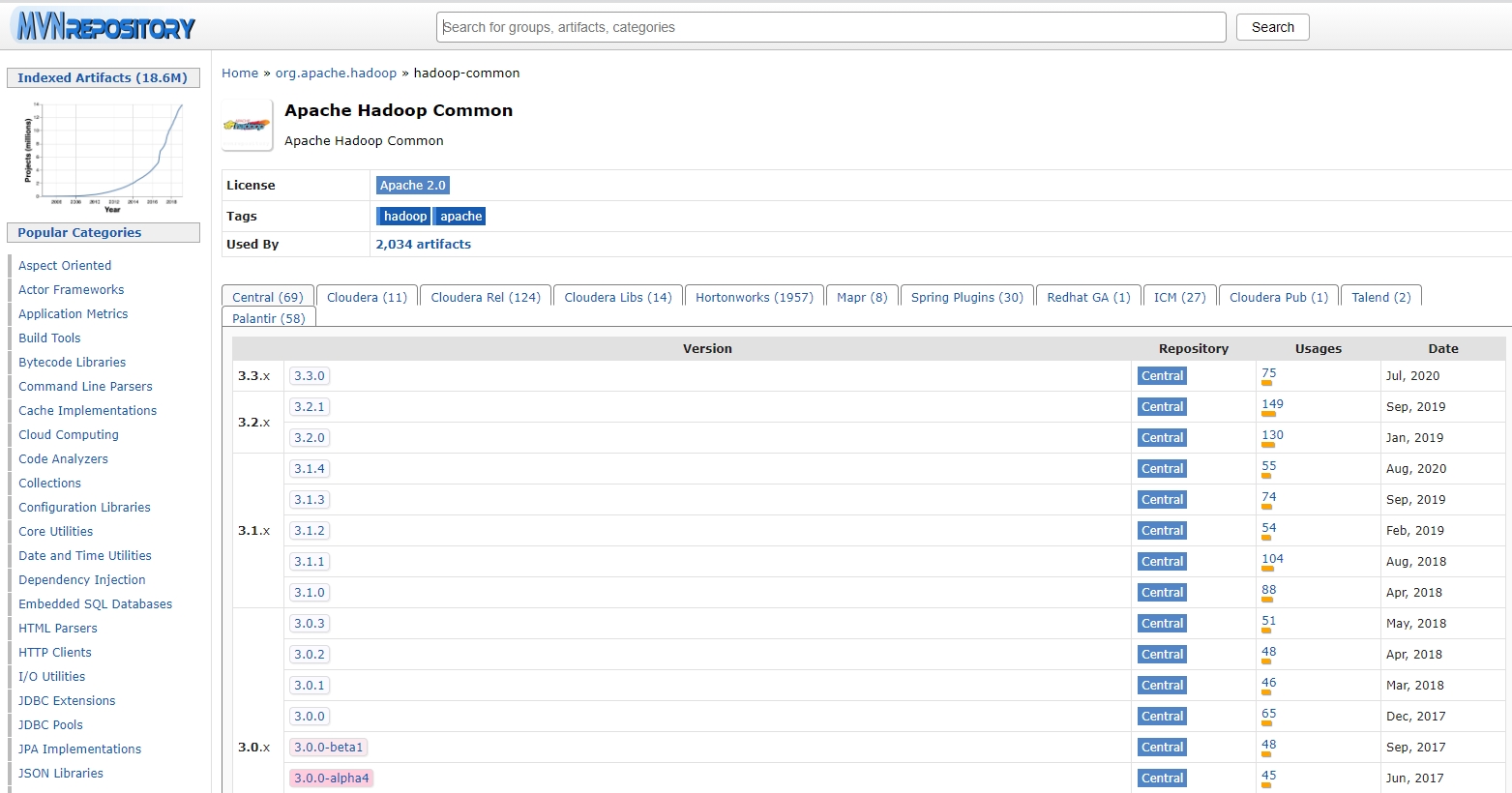
鼠标往下滑动,发现果然!2.10.1的版本出现了!因此我们可以使用找个版本的hadoop,因为在maven仓库里是可以找到的,这样就不会出现无法编程调用hadoop的问题:

2.将下载的文件进行解压
我们下载之后的文件二进制文件后缀名为tar.gz,你可以来到你下载的地方,使用windows下的压缩包软件直接进行解压,我使用的是2345压缩软件进行的解压。有些教程让我们必须在windows下模拟的linux环境下(MinGW)才能够解压,其实完全不用,就把tar.gz当作普通的压缩文件就好了,解压之后将文件夹更名为hadoop。
3.设置环境变量
- 一方面是要设置好Java的环境变量
- 另一方面是要设置好刚刚下载的Hadoop的环境变量
我们在环境变量处分别设置JAVA_HOME和HADOOP_HOME(目的是为了hadoop在运行的时候能够找到自己和java的地方在哪儿):

然后在Path里添加JAVA和hadoop的二进制文件夹,bin文件夹,目的是我们这样就可以使用cmd对java和haodoop进行操作:
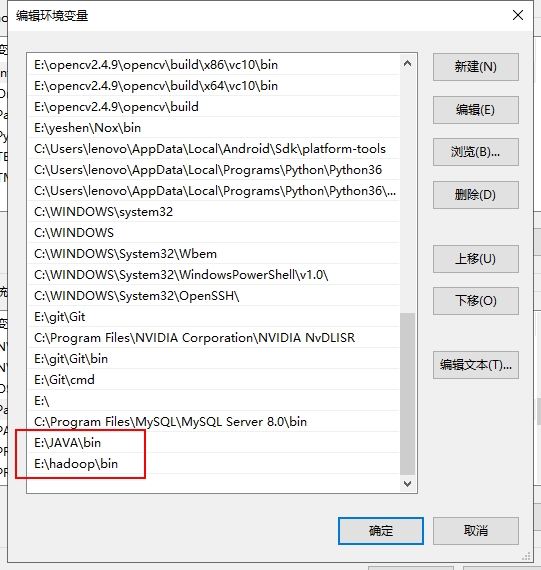
4.验证环境变量的配置
打开你的cmd,输入以下命令,出现我这样的输出说明配置环境变量成功:
C:\Users\lenovo>hadoop -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
5.HDFS的配置
接下来就是配置HDFS的文件,进行伪分布式集群以适应你的计算机。(备注:伪分布式集群也是分布式集群,可以起动分布式计算的效果)
我们来到之前解压的hadoop文件夹下,打开etc/hadoop文件夹,发现里面有很多文件:

现在我们的任务就是修改这些文件当中的代码,务必修改,不然根本无法运行hadoop!!
6.修改 hadoop-env.cmd
打开这个文件,在找个文件当中的末尾添加上:
set HADOOP_PREFIX=%HADOOP_HOME%
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\bin
7.修改core-site.xml
将configuration处更改为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
</configuration>
8.hdfs-site.xml
将configuration处更改为如下所示,其中
file:///F:/DataAnalytics/dfs/namespace_logs
file:///F:/DataAnalytics/dfs/data
这两个文件夹一定需要是已经存在的文件夹,你可以在你的hadoop文件夹下随意创建两个文件夹,然后将下面的这两个文件夹的绝对路径替换成你的文件夹,这里我也是创建了两个新的文件夹,hadoop的下载文件夹里本身是没有的。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///F:/DataAnalytics/dfs/namespace_logs</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///F:/DataAnalytics/dfs/data</value>
</property>
</configuration>
9. mapred-site.xml
将下方的%USERNAME%替换成你windows的用户名!!!这个十分重要,不要直接复制!!!
<configuration>
<property>
<name>mapreduce.job.user.name</name>
<value>%USERNAME%</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.apps.stagingDir</name>
<value>/user/%USERNAME%/staging</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>local</value>
</property>
</configuration>
10.yarn-site.xml
修改为如下所示:
<configuration>
<property>
<name>yarn.server.resourcemanager.address</name>
<value>0.0.0.0:8020</value>
</property>
<property>
<name>yarn.server.resourcemanager.application.expiry.interval</name>
<value>60000</value>
</property>
<property>
<name>yarn.server.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.server.nodemanager.remote-app-log-dir</name>
<value>/app-logs</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/dep/logs/userlogs</value>
</property>
<property>
<name>yarn.server.mapreduce-appmanager.attempt-listener.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.server.mapreduce-appmanager.client-service.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>-1</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>%HADOOP_CONF_DIR%,%HADOOP_COMMON_HOME%/share/hadoop/common/*,%HADOOP_COMMON_HOME%/share/hadoop/common/lib/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*</value>
</property>
</configuration>
11.初始化环境变量
在windows下的cmd,输入cmd的命令,用于初始化环境变量。hadoop-env.cmd后缀为cmd,说明是cmd下可执行的文件:
%HADOOP_HOME%\etc\hadoop\hadoop-env.cmd
12.格式化文件系统(File System)
这个命令在整个hadoop的配置环境和之后的使用当中务必仅使用一次!!!!不然的话后续会导致hadoop日志损坏,NameNode无法开启,整个hadoop就挂了!
将如下的命令输入到cmd当中进行格式化:
hadoop namenode -format
输出:
2018-02-18 21:29:41,501 INFO namenode.FSImage: Allocated new BlockPoolId: BP-353327356-172.24.144.1-1518949781495
2018-02-18 21:29:41,817 INFO common.Storage: Storage directory F:\DataAnalytics\dfs\namespace_logs has been successfully formatted.
2018-02-18 21:29:41,826 INFO namenode.FSImageFormatProtobuf: Saving image file F:\DataAnalytics\dfs\namespace_logs\current\fsimage.ckpt_0000000000000000000 using no compression
2018-02-18 21:29:41,934 INFO namenode.FSImageFormatProtobuf: Image file F:\DataAnalytics\dfs\namespace_logs\current\fsimage.ckpt_0000000000000000000 of size 390 bytes saved in 0 seconds.
2018-02-18 21:29:41,969 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
13.向hadoop文件当中注入winutills文件
由于windows下想要开启集群,会有一定的bug,因此我们去网站:https://github.com/steveloughran/winutils
下载对应版本的winutils.exe文件。打开这个Github仓库后如下所示: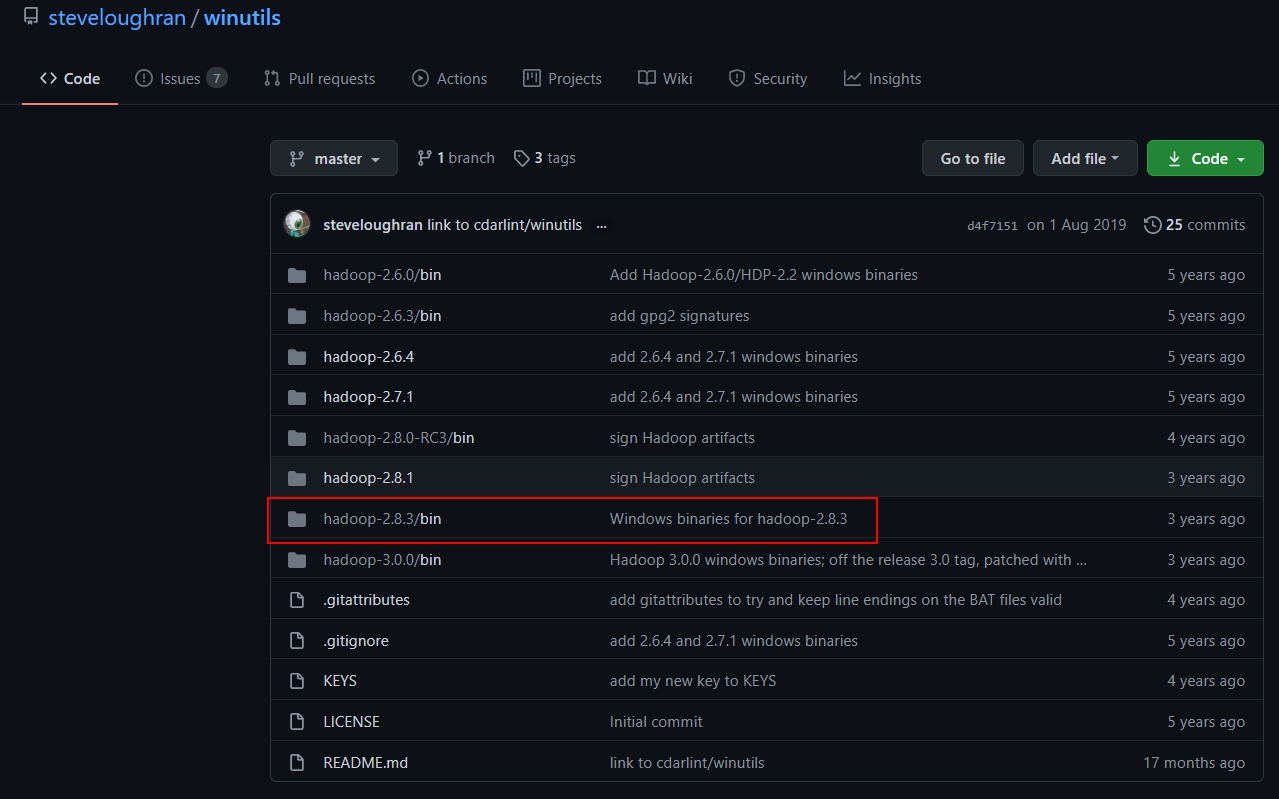
我们打开hadoop2.8.3/bin,选择其中的winutils.exe文件进行下载,然后将下载的这个文件放入到本地的hadoop/bin文件当中。不然的话,你打开一会儿你的伪分布式集群,马上hadoop就会自动关闭,缺少这两个文件的话。
我本地的bin文件最终如下所示:
14.开启hadoop集群
下面就是最激动人心的开启hadoop集群了!!!!我们在cmd当中输入:
C:\Users\lenovo>%HADOOP_HOME%/sbin/start-all.cmd
This script is Deprecated. Instead use start-dfs.cmd and start-yarn.cmd
starting yarn daemons
这样就会跳出来很多黑色的窗口,如下所示:
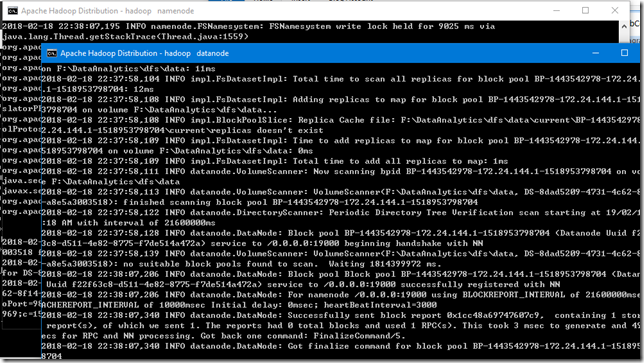
然后可以使用JPS工具查看目前开启的node有哪些,如果出现namenode,datanode的话说明集群基本上就成功了。如下所示:

15.打开本地浏览器进行验证
我们在浏览器输入localhost:50070,如果能够打开这样的网页,说明hadoop已经成功开启:
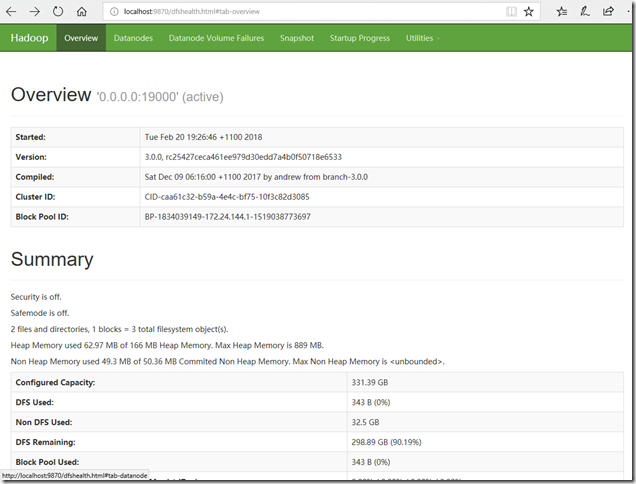
接下来就可以开始IDEA的配置了
16.创建MAVEN项目工程
打开IDEA之后,里面的参数和项目工程名称随便写,等待工程创建完毕即可。然后我们编辑pom.xml文件,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.atguigu</groupId>
<artifactId>hdfs1205</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies> </project>
因为我使用了2.10.1版本,因此导入的包均为2.10.1,除了log4j,这个是固定的2.8.2版本的。
然后点击我箭头指向的同步maven仓库,如下所示:
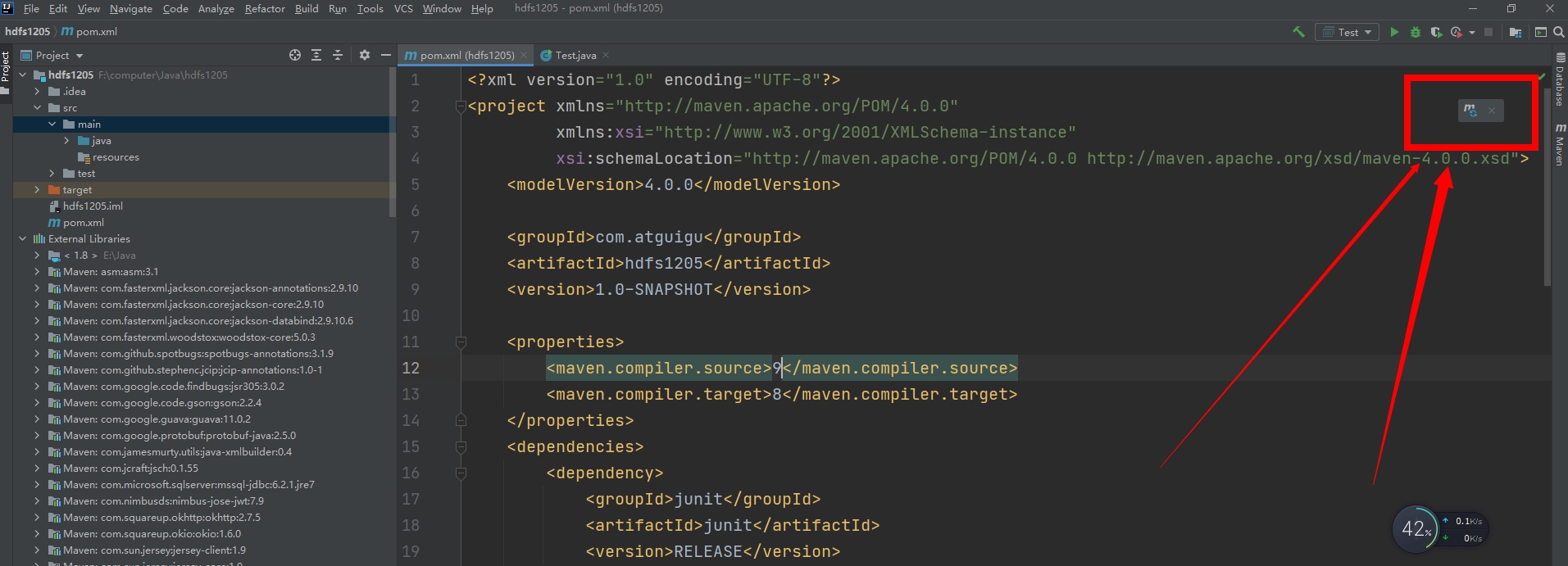
同步完成之后,IDEA左边的external libararies处就会显示大量的有关hadoop的jar包,如下所示:
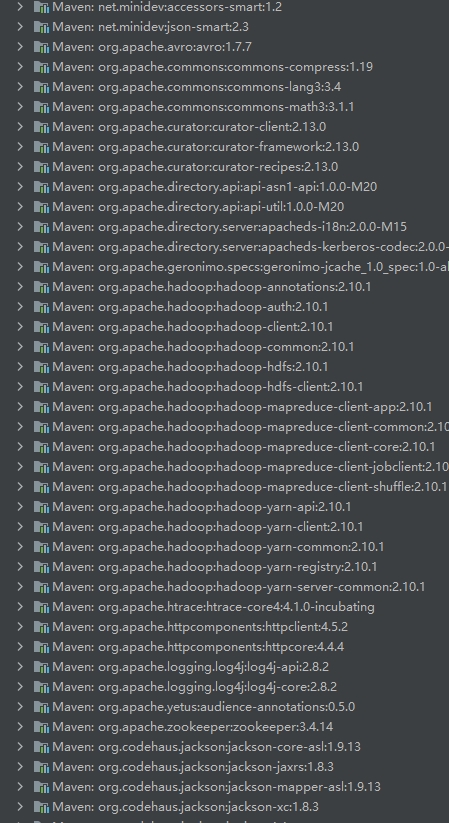
这样就说明我们导入maven仓库成功了。
17.编写代码
现在我们开始编写代码,在开启hadoop伪分布式集群之后,代码才可以运行哦!
代码如下所示:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.net.URI; public class Test {
public static void main(String[] args) throws Exception {
FileSystem fs = FileSystem.get(new URI("hdfs://127.0.0.1:9000"), new Configuration()); FileStatus[] files = fs.listStatus(new Path("/"));
for (FileStatus f : files) {
System.out.println(f);
}
System.out.println("Compile Over");
}
}
这段代码的含义是遍历hadoop文件系统(HDFS)下的root下所有文件的状态,并输出,由于我目前并没有在HDFS下put了任何文件,因此不会有输出,出现这样的输出,说明代码代码运行成功:
exit code 0,返回code为0说明运行成功!
【Hadoop】:Windows下使用IDEA搭建Hadoop开发环境的更多相关文章
- Windows下使用VS2017搭建FLTK开发环境
环境介绍 系统:win10 64位 IDE:VS 2017 Community FLTK版本:1.3.4-2 下载FLTK 截止到本文编写,FLTK的最新稳定版本是1.3.4-2.我们从官网(www. ...
- Windows+QT+Eclipse+MinGW搭建QT开发环境详细教程
Windows+QT+Eclipse+MinGW搭建QT开发环境详细教程 一.准备工具: QT-SDK for Windows:http://get.qt.nokia.com/qtsdk/qt-sd ...
- mac 下 用 glfw3 搭建opengl开发环境
mac 下 用 glfw3 搭建opengl开发环境 下载编译 glfw3 Build Setting 里面, Library Search Paths -> 设置好编译 glfw 库的路径 H ...
- (转)Lua学习笔记1:Windows7下使用VS2015搭建Lua开发环境
Lua学习笔记1:Windows7下使用VS2015搭建Lua开发环境(一)注意:工程必须添加两个宏:“配置属性”/“C或C++”/“预处理器”/“预处理器定义”,添加两个宏:_CRT_SECURE_ ...
- MAC 下用 brew 搭建 PHP 开发环境
Mac下用brew搭建PHP(LNMP/LAMP)开发环境 Mac下搭建lamp开发环境很容易,有xampp和mamp现成的集成环境.但是集成环境对于经常需要自定义一些配置的开发者来说会非常麻烦,而且 ...
- windows下Qt5.2 for android开发环境搭建
windows下Qt5.2 forAndroid开发环境配置 1.下载安装Qt 5.2.0 for Android (Windows 32-bit) http://qt-project.org/d ...
- Windows10系统下使用Docker搭建ClickHouse开发环境
前提 随着现在业务开展,几个业务系统的数据量开始急剧膨胀.之前使用了关系型数据库MySQL进行了一次数据仓库的建模,发现了数据量上来后,大量的JOIN操作在提高了云MySQL的配置后依然有点吃不消,加 ...
- HBase学习3(win下使用Eclipse搭建hbase开发环境)
第一步:创建一个java project命名为wujiadong_hbase 第二步:在该工程下创建一个folder命名为lib(储存依赖的jar包) 第三步:将集群中的hbase安装目录下载一份到w ...
- 利用 WSL 在 Windows下打造高效的 Linux 开发环境
WSL-Windows Subsystem for Linux 介绍 The Windows Subsystem for Linux lets developers run Linux environ ...
随机推荐
- sentinel降级误解
public void initDegradeRule(){ List<DegradeRule> rules=new ArrayList<>(); DegradeRule ru ...
- 思维导图学《JVM 虚拟机规范》
目录 工具 虚拟机实现 class 文件结构 字节码指令 其他 虚拟机结构 公众号 coding 笔记.点滴记录,以后的文章也会同步到公众号(Coding Insight)中,希望大家关注_ 公众号 ...
- 渗透入门rop
原文链接:https://blog.csdn.net/guiguzi1110/article/details/77663430?locationNum=1&fps=1 基本ROP 随着NX保护 ...
- 20200520_windows2012安装python和django环境
http://httpd.apache.org/download.cgi#apache24 配置文件修改后, 记得去阿里云开放端口 ServerName 172.18.196.189:9080 →不能 ...
- `prometheus-net.DotNetRuntime` 获取 CLR 运行指标原理解析
prometheus-net.DotNetRuntime 介绍 Intro 前面集成 Prometheus 的文章中简单提到过,prometheus-net.DotNetRuntime 可以获取到一些 ...
- 第8.11节 Python类中记录实例变量属性的特殊变量__dict__
一. 语法释义 调用方法:实例. __dict__属性 __dict__属性返回的是实例对象中当前已经定义的所有自定义实例变量的名和值,用字典存储,每个元素为一个"实例变量名:值" ...
- Python特殊序列\d能匹配哪些数字?
在缺省语言环境下,老猿对\d的匹配范围做了个测试,下面的数字包含半角数字.全角数字.中文数字,测试语句如下: >>> m=re.search(r'(\d*)(\D*)(\d*)',' ...
- MySQL必知必会详细总结
一.检索数据 1.检索单个列:SELECT prod_name FROM products; 2.检索多个列:SELECT prod_id,prod_name,prod_price FROM prod ...
- 箭头函数this指向问题
this指向本质 箭头函数this指向的固定化,并不是因为箭头函数内部有绑定this的机制,实际原因是箭头函数根本没有自己的this,导致内部的this就是外层代码块的this.正是因为它没有this ...
- Springboot mini - Solon详解(四)- Solon的事务传播机制
Springboot min -Solon 详解系列文章: Springboot mini - Solon详解(一)- 快速入门 Springboot mini - Solon详解(二)- Solon ...