三、hadoop、yarn安装配置
本文hadoop的安装版本为hadoop-2.6.5
关闭防火墙
systemctl stop firewalld
一、安装JDK
1、下载java jdk1.8版本,放在/mnt/sata1目录下,
2、解压:tar -zxvf dk-8u111-linux-x64.tar.gz
3、vim /etc/profile
#在文件最后添加
export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
export PATH=$PATH:$JAVA_HOME/bin
4、刷新配置
source /etc/profile
5、检测是否成功安装:java -version
二、安装Hadoop(单机版)
1、下载hadoop-2.6.5.tar.gz放在/mnt/sata1目录下
2、解压:tar -zxvf hadoop-2.6.5.tar.gz
三、修改配置文件
1、修改hadoop-env.sh,配置java jdk路径
echo $JAVA_HOME
/mnt/sata1/jdk1.8.0_111
#将默认的export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
2、修改core-site.xml,配置内容如下
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<!-- yang为主机名 -->
<name>fs.defaultFS</name>
<value>hdfs://yang:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/sata1/hadoop_data</value>
</property>
</configuration>
3、修改hdfs-site.xml,修改配置如下
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4、将hadoop添加到环境变量,然后更新一下环境变量:source /etc/profile
export HADOOP_HOME=/mnt/sata1/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新配置
source /etc/profile
6、配置免密(这里以单节点自己对自己免密)
1、创建dsa免密代码:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2、将生成的公钥发送给需要做免密的主机:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
7、进入/mnt/sata1/hadoop-2.6.5/bin进行格式化
./hdfs nameode -format
8、启动服务
start-dfs.sh
注:
如果没有配置环境变量,到目录/mnt/sata1/hadoop-2.6.5/bin启动(./
start-dfs.sh
)
9、

三、yarn(单机版)
1、修改mapred-site.xml 由于在配置文件目录(/mnt/sata1/hadoop-2.6.5/etc/hadoop)下没有,需要修改名称:mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、修改yarn-site.xml,修改内容如下
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
localhost:主机名
3、启动yarn
cd /mnt/sata1/hadoop-2.6.5/
./start-yarn.sh
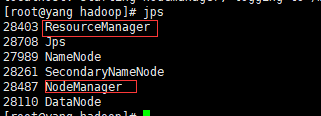
四、Hadoop(集群版)yarn集群版
1、修改hadoop-env.sh,配置java jdk路径
echo $JAVA_HOME
/mnt/sata1/jdk1.8.0_111
#将默认的export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
2、修改core-site.xml,配置内容如下
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<!-- yang为主机名 -->
<name>fs.defaultFS</name>
<value>hdfs://yang:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/sata1/hadoop_data</value>
</property>
</configuration>
3、修改hdfs-site.xml,修改配置如下
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave01:50090</value>
</property>
4、SecondaryNameNode与namenode的分开配置,新建一个masters文件,内容为secondnamenode所在节点
/mnt/hadoop/etc/hadoop
[root@master hadoop]# cat masters
slave01
同时在hdfs-site.xml文件加入:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave01:50090</value>
</property>
4、配置yarn
1.修改hadoop配置目录:
复制文件: cp mapred-site.xml.templta mapred-site.xml
mapred-site.xm加入以下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.yarn-site.xml加入以下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
5、将hadoop的目录文件分发到其他主机
scp -r hadoop root@slave01:/mnt
scp -r hadoop root@slave02:/mnt
6、配置环境变量
export HADOOP_HOME=/mnt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
7、进入/mnt/hadoop/bin进行格式化(在master所在节点执行)
./hdfs namenode -format
6、启动服务hdfs、yarn
start-dfs.sh start-yarn.sh
注:
如果没有配置环境变量,到目录/mnt/hadoop/bin启动(./
start-dfs.sh
)
三、hadoop、yarn安装配置的更多相关文章
- Hadoop Yarn环境配置
抄一个可行的Hadoop Yarn环境配置.用的官方的2.2.0版本. http://www.jdon.com/bigdata/yarn.html Hadoop 2.2新特性 将Mapreduce框架 ...
- Hadoop 2.x(YARN)安装配置LZO
今天尝试在Hadoop 2.x(YARN)上安装和配置LZO,遇到了很多坑,网上的资料都是基于Hadoop 1.x的,基本没有对于Hadoop 2.x上应用LZO,我在这边记录整个安装配置过程 1. ...
- Hadoop的安装配置(一)
一.Hadoop的安装①Hadoop运行的前提是本机已经安装了JDK,配置JAVA_HOME变量②在Hadoop中启动多种不同类型的进程 例如NN,DN,RM,NM,这些进程需要进行通信 ...
- Storm on Yarn 安装配置
1.背景知识 在不修改Storm任何源代码的情况下,让Storm运行在YARN上,最简单的实现方法是将Storm的各个服务组件(包括Nimbus和Supervisor),作为单独的任务运行在YARN上 ...
- Hadoop Yarn 安装
环境:Linux, 8G 内存.60G 硬盘 , Hadoop 2.2.0 为了构建基于Yarn体系的Spark集群.先要安装Hadoop集群,为了以后查阅方便记录了我本次安装的详细步骤. 事前准备 ...
- Hadoop单机安装配置过程:
1. 首先安装JDK,必须是sun公司的jdk,最好1.6版本以上. 最后java –version 查看成功与否. 注意配置/etc/profile文件,在其后面加上下面几句: export JAV ...
- Hadoop详细安装配置过程
步骤一:基础环境搭建 1.下载并安装ubuntukylin-15.10-desktop-amd64.iso 2.安装ssh sudo apt-get install openssh-server op ...
- 【大数据】Hadoop单机安装配置
1.解压缩hadoop-2.7.6.tar.gz到/home/hadoop/Soft目录中 2.创建软链接,方便hadoop升级 ln -s /home/hadoop/Soft/hadoop-2.7 ...
- Hadoop简单安装配置
Hadoop开始设计以Linux平台为运行目标,所以这里推荐在Linux发行版比如Ubuntu进行安装,目前已经有Hadoop for Windows出来,大家自行搜下文章. Hadoop运行模式分为 ...
随机推荐
- PyQt Designer中连接信号和槽时为什么只能连接控件自己的信号和槽函数?
老猿在学习ListView组件时,想实现一个在ListView组件中选中一个选择项后触发消息给主窗口,通过主窗口显示当前选中的项的内容. 进入QtDesigner后,设计一个图形界面,其中窗口界面使用 ...
- 3、tensorflow变量运算,数学运算
import tensorflow as tf import numpy as np a = tf.range(1,7) a = tf.reshape(a,[2,3]) b = tf.constant ...
- 「IOI2017」接线 的另类做法
看到这题,我的第一反应是:这就是一个费用流模型?用模拟费用流的方法? 这应该是可以的,但是我忘记了怎么模拟费用流了IOI不可能考模拟费用流.于是我就想了另外一个方法. 首先我们考虑模拟费用流的模型如下 ...
- AcWing 326. XOR和路径
大型补档计划 题目链接 如果整体来做,发现既有加法,也有整体异或,这样不容易搞. 考虑异或,各个位置互不干扰,按位考虑一下. 枚举每一位 \(k\) 发现如果设 \(f[u]\) 为这一位的期望结果还 ...
- Angular:自定义属性指令
①在命令行窗口下用 CLI 命令ng g directive创建指令类文件 ②将directives/light.directive.ts文件改造一番 import { Directive, Elem ...
- python 全局变量与局部变量 垃圾回收机制
掌握L.E.G.B(作用域) 掌握局部作用域修改全局变量 步骤- 1.命名空间和作用域 命名空间:变量名称与值的映射关系作用域:变量作用的区域,即范围. 注意:class/def/模块会产生作用域:分 ...
- 【Azure Redis 缓存】Azure Redis 服务不支持指令CONFIG
问题描述 在Azure Redis的门户页面中,通过Redis Console连接到Redis后,想通过CONFIG命令来配置Redis,但是系统提示CONFIG命令不能用. 错误消息为:(error ...
- virtualbox sharefolder mount fail
ubuntu 14.04.1 LTS 64bit 安装完GuestAdditions后,在终端输入 sudo mount -t vboxsf sharename /mnt/share 提示错误:mou ...
- Windows安装Pytorch并配置Anaconda与Pycharm
1 开发环境准备 Python 3.7+Anaconda3 5.3.1(64位)+CUDA+Pycharm Community 2 安装Anaconda 2.1 进入官网下载: 根据windows版本 ...
- vue封装API接口
第一步: 首先引入axios 然后创建两个文件夹api和http http.js 里面的 1 import axios from 'axios';//引入axios 2 3 //环境的切换 开发环境( ...