多媒体开发(5)&音频特征:声音可以调大一点吗?
基本上,现在常用的声音采样办法是pcm,而对于压缩音频的解码,得到的也pcm数据。这个pcm数据,只是一堆数值,有正有负,看这个值看不出什么花样。
声音采集,采的是什么呢?
采的是声音的强度变化,也是声音这种能量的强弱变化,这种强弱用分贝来表示,即dB。所以,pcm数据跟这个dB就一定有关系,这个关系是这样的:
dB=20∗log10(pcm)
pcm=pow(10,(dB/20.0))
模数转换ADC时常用的位深是16bit,也就是用16位来表示一个sample,这里不考虑偷懒而使用不足16位的情况。16位能表示65536个值,也就意味着有65536个dB可以表示出来,哪又怎么样?很厉害了吗?
的确是比较厉害的了。
16位的pcm数值,分正负,那正数的范围是0至32767,负数的范围是-1至-32768,随便挑几个来看看,对应的dB是多少,如下图:
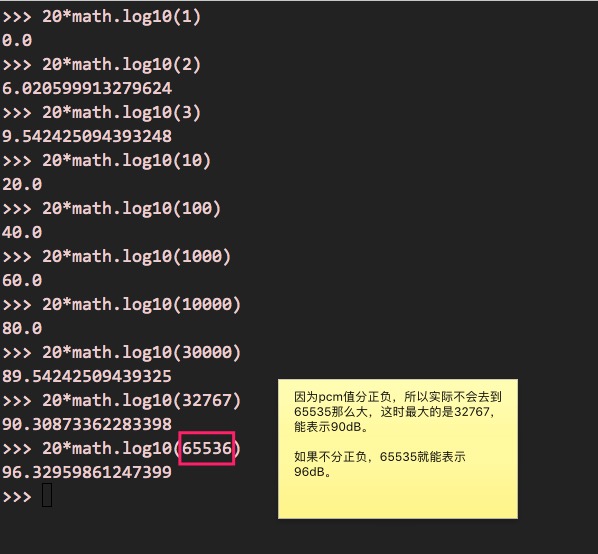
由上面的运算可知,16位的pcm值,如果不分正负,最大可以表示96dB,如果分正负,也能表示到90dB。90dB是什么概念?有数据表明(我也不清楚什么数据),85dB就会伤害了你,90dB相当于摩托车启动的声音--你有开过吗?
所以,你的pcm数据需要去到90dB以上吗?想祸害谁?一般情况下,能表示到90dB就很够用了。
既然知道了pcm数值与dB的关系,就可以搞点事情了,比如把pcm转成dB后再放大一点,再保存成新的文件,是不是播放就可以大声一点了呢?
来做个实验。
import math
import math
import wave
import audioread
import contextlib
import sys
import math
import struct
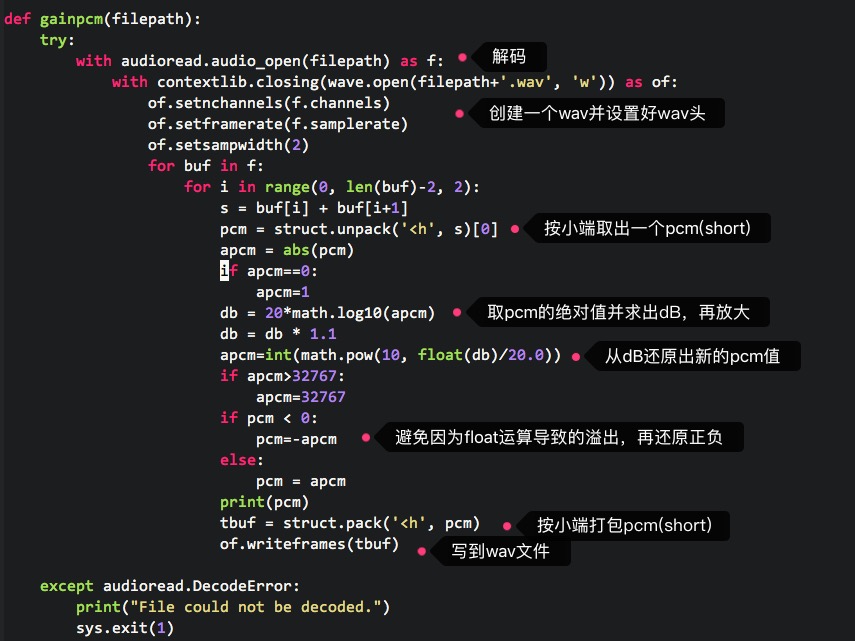
def gainpcm(filepath):
try:
with audioread.audio_open(filepath) as f:
with contextlib.closing(wave.open(filepath+'.wav', 'w')) as of:
of.setnchannels(f.channels)
of.setframerate(f.samplerate)
of.setsampwidth(2)
for buf in f:
for i in range(0, len(buf)-2, 2):
s = buf[i] + buf[i+1]
pcm = struct.unpack('<h', s)[0]
apcm = abs(pcm)
if apcm==0:
apcm=1
db = 20*math.log10(apcm)
db = db * 1.2
apcm=int(math.pow(10, float(db)/20.0))
if apcm>32767:
apcm=32767
if pcm < 0:
pcm=-apcm
else:
pcm = apcm
tbuf = struct.pack('<h', pcm)
of.writeframes(tbuf)
except audioread.DecodeError:
print("File could not be decoded.")
sys.exit(1)
if __name__ == '__main__':
gainpcm('test.mp3')
这里是对代码的简单解释:
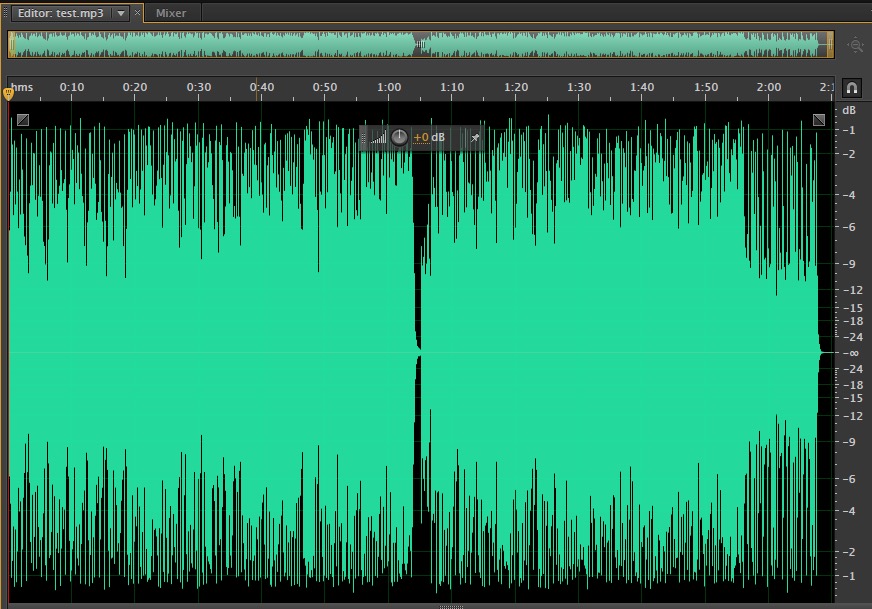
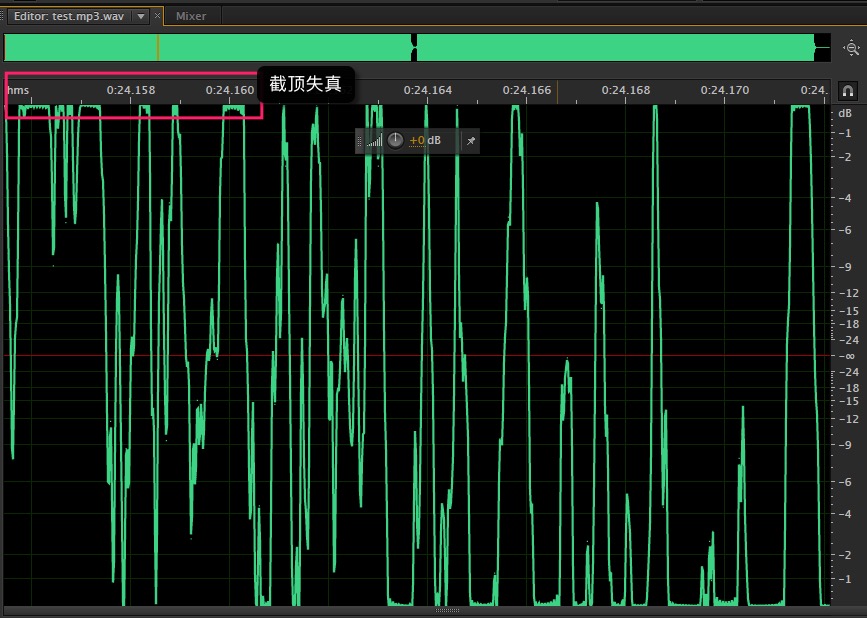
把一个mp3放过去试验,出来一个wav,发现wav文件的声音真的大了好多(好多是因为这里设置了db*1.2)。但是,另一个问题也暴露出来了,就是听起来声音失真很严重了,这是因为放大到这个程度,很多apcm都超过了32767,也就是人们说的截顶失真了,看一下原文件与放大后的文件波形图就更清楚了:
由于不能上传音频,这里就不提供直接的音频对比了。
由此可见,要想不失真,那db就不要乘那么大的数啊--另一个办法:给它限幅(压幅),或者直接使用更合适的整体技术(灵活变音量跟限幅都考虑进去了)比如agc或drc等,明显这个不是这里的内容。
好了,总结一下,本文演示了改变音量的一种最原始的办法,就是直接改pcm的值(转dB再改变,其实也可以直接改变pcm值),但这不是最好的办法,因为它会引入失真的副作用。而从pcm数据中提取出能量(dB),这个也更像是音频特征的技能。有缘再见,see you。
多媒体开发(5)&音频特征:声音可以调大一点吗?的更多相关文章
- 多媒体开发之音频编码---ffmpeg 编码aac
http://blog.csdn.net/ctroll/article/details/8169396
- graphical Layout调大一点
布局最右边的放大器按钮好难找啊
- 多媒体开发库 之 SDL 详解
SDL 简介 SDL(Simple DirectMedia Layer)是一套开放源代码的跨平台多媒体开发库,使用C语言写成.SDL提供了数种控制图像.声音.输出入的函数,让开发者只要用相同或是相似的 ...
- moviepy音视频开发:音频剪辑基类AudioClip
☞ ░ 前往老猿Python博文目录 ░ 一.背景知识介绍 1.1.声音三要素: 音调:人耳对声音高低的感觉称为音调(也叫音频).音调主要与声波的频率有关.声波的频率高,则音调也高. 音量:也就是响度 ...
- IOS开发之音频--录音
前言:本篇介绍录音. 关于录音,这里提供更为详细的讲解网址:http://www.cnblogs.com/kenshincui/p/4186022.html#audioRecord ,并且该博客有更 ...
- Kubuntu麦克风音频无声音
前段时间买了新本,装了双系统,win8和kubuntu 14.04,使用的过程感觉都不错,因为平时玩游戏看视频是用win8,但最近打算在kubuntu上听音乐时,发现音频没有声音,麦克风也没有声音,这 ...
- LiveVideoStack Meet|深圳 多媒体开发新趋势
2018年初始,音视频技术生态并不平静,Codec争夺愈加激烈,新一代标准的挑战一浪高过一浪:WebRTC的定版也为打通浏览器.移动端乃至IoT带来了机会:此外AI.区块链技术的兴起,催化着与多媒体领 ...
- 音频标签化1:audioset与训练模型 | 音频特征样本
随着机器学习的发展,很多"历史遗留"问题有了新的解决方案.这些遗留问题中,有一个是音频标签化,即如何智能地给一段音频打上标签的问题,标签包括"吉他"." ...
- iOS AVAudioPlayer播放音频时声音太小
iOS AVAudioPlayer播放音频时声音太小 //引入AVFoundation类库,设置播放模式就可以了 do { try AVAudioSession.sharedInstance().ov ...
随机推荐
- 第 3 篇 Scrum 冲刺博客
每天举行会议 会议照片: 昨天已完成的工作与今天计划完成的工作及工作中遇到的困难: 成员姓名 昨天完成工作 今天计划完成的工作 工作中遇到的困难 蔡双浩 了解任务,并做相关学习和思考,创建基本的收藏夹 ...
- element ui的el-radio踩坑
1.html 1 <div class="listPeopleDetail"> 2 <div class="item" v-for=" ...
- 【题解】切割多边形 [SCOI2003] [P4529] [Bzoj1091]
[题解]切割多边形 [SCOI2003] [P4529] [Bzoj1091] 传送门:切割多边形 \(\text{[SCOI2003] [P4529]}\) \(\text{[Bzoj1091]}\ ...
- 题解-SDOI2013 淘金
题面 SDOI2013 淘金 有一个 \(X\).\(Y\) 轴坐标范围为 \(1\sim n\) 的范围的方阵,每个点上有块黄金.一阵风来 \((x,y)\) 上的黄金到了 \((f(x),f(y) ...
- Linux 开机启动程序的顺序
1.加载BISO的硬件信息,并取得第一个开机代号 2.读取第一个开机装置的mbr的boot loader的信息 3.加载kernel操作系统核心信息,开始解压缩,并驱动所有硬件装置 4.kernel执 ...
- Oracle 常用语句1
-- 我是注释信息 sql语句 -- 创建用户: create user 用户名 identified by 密码; create user jack identified by j123; -- l ...
- 浅谈强连通分量(Tarjan)
强连通分量\(\rm (Tarjan)\) --作者:BiuBiu_Miku \(1.\)一些术语 · 无向图:指的是一张图里面所有的边都是双向的,好比两个人打电话 \(U ...
- Spark-1-调优基本原则
1基本概念和原则 每一台host上面可以并行N个worker,每一个worker下面可以并行M个executor,task们会被分配到executor上面去执行.Stage指的是一组并行运行的task ...
- Python高级语法-对象实例对象属性-Property总结(4.6.2)
@ 目录 1.说明 2.代码 关于作者 1.说明 property属性,返回的是值 不是callable的,也就是不能使用方法来调用 只能传入self,不能传入其他 用处,能返回局部数据,比如当分页的 ...
- ctf/web源码泄露及利用办法
和上一篇文章差不多,也算是对web源码泄露的一个总结,但是这篇文章更侧重于CTF 参考文章: https://blog.csdn.net/wy_97/article/details/78165051? ...