Elasticsearch搜索资料汇总
Elasticsearch 简介
Elasticsearch(ES)是一个基于Lucene
构建的开源分布式搜索分析引擎,可以近实时的索引、检索数据。具备高可靠、易使用、社区活跃等特点,在全文检索、日志分析、监控分析等场景具有广泛应用。
lucene
Elasticsearch 中文社区:https://elasticsearch.cn/article/
Elasticsearch 官方文档:https://www.elastic.co/guide/index.html
Elasticsearch 各客户端API(eg:.NET、JAVA、Python、Go)
Elasticsearch .net client NEST 5.x 使用总结(初始化、查询、权重、排序、聚合等)
Elasticsearch 客户端SDK使用建议:创建索引的Setting和mapping使用elasticsearch 提供的DSL语法更加简单。因为客户端API代码里面只提供基础的SDK,如(ik拼音等)插件就没有对应接口提供
Elasticsearch术语(索引、类型、文档、集群、节点、分片)
ES数据架构的主要概念(与关系数据库Mysql对比)
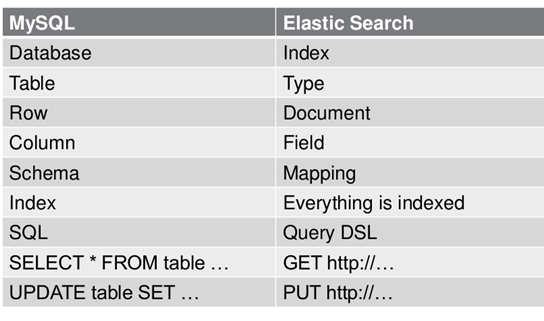
在ES
早期版本,一个索引下是可以有多个Type
,从7.0
开始,一个索引只有一个Type,即_doc。一个Type 下的文档,都有相同的字段(Field)
安装
ELK
ELK 是elastic 公司旗下三款产品ElasticSearch
、Logstash 、Kibana 的首字母组合。
#、ElasticSearch 是一个基于Lucene
构建的开源,分布式,RESTful
搜索引擎。
#、Logstash 传输和处理你的日志、事务或其他数据。
#、Kibana 将Elasticsearch
的数据分析并渲染为可视化的报表。
分词器
分词器是专门处理分词的组件,分词器由如下三部分组成:
1、Character Filters:针对原始文本处理,比如:去除html 标签
2、Tokenizer:按照规则切分为单词,比如:按照空格切分
3、Token Filters:将切分的单词进行加工,比如:大写转小写,删除stopwords,拼音,同义词等
analyzer = CharFilters(0个或多个)+
Tokenizer(一个) +
TokenFilters(0个或多个)
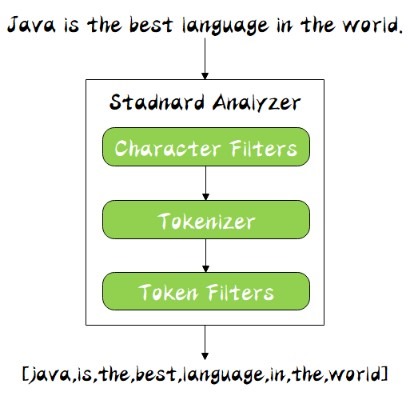
从图中能够看出,从上到下依次通过Character
Filters,Tokenizer
以及Token
Filters,这个顺序比较好理解,一个文本进来确定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
elasticSearch Analysis Token Filters作用及相关样例
ElasticSearch查看字段分词结果 (便于查为什么匹配不出的问题)
Elasticsearch7 分词器(内置分词器和自定义分词器)
Elasticsearch-Analysis-IK中文分词器配置使用
elasticsearch 之分词器配置 (IK+pinyin)
Elasticsearch 使用ik中文分词器增加分词热词(自定义词)
Elasticsearch mapping
搞懂Elasticsearch 之Mapping (Reindex)
Mapping中的store属性(按需查询字段)
Elasticsearch中的store field跟non-store field的区别
Elasticsearch 理解mapping中的store属性
Elasticsearch 动态模板(dynamic_templates)
normalizer 的使用
ElasticSearch Normalizer 的使用方法
Adding normalizer for all keyword fields NEST
Elasticsearch DLS语法
Elasticsearch 查询语法(模糊、精确、sort、相关性、and|or、slop间隔等)
Elasticsearch 查询语法(多条件bool复杂查询(must、should、filter)、日期范围查询)
Elasticsearch 查询语法(bool复杂查询、operator(||、&&、!、+))
ElasticSearch 组合多查询(bool, must, should, must_not, filter)
Elasticsearch中match、match_phrase、query_string和term的区别
相关性score
ElasticSearch 的分数(_score) 是怎么计算得出 (2.X & 5.X)
ElasticSearch 多级排序(eg:产品要根据:销量、热度、相关性排序)
Elasticsearch 搜索条件权重控制(boost)-- 默认情况下,搜索条件的权重都是1
聚合查询
Elasticsearch 聚合语法(Aggregations)
分页查询
Elasticsearch 查询语法(使用scroll响应式返回大集合文档)
Elasticsearch 高亮显示匹配关键词(Highlight)
同义词
elasticsearch 使用同义词(synonym.txt)
搜索建议词(Suggest功能)
ElasticSearch使用completion实现补全功能
Elasticsearch Suggester详解(自动补全)
elasticsearch 7.0 新特性之 search as you type
安全性
Meow攻击删除开放的的Elasticsearch(及MongoDB) 索引,建一堆以Meow结尾的奇奇怪怪的索引(如:m3egspncll-meow)----关闭外网访问端口,或至少修改ES默认端口
用nginx给kibana、elasticsearch做权限认证
集中式日志分析平台- ELK Stack - 安全解决方案 X-Pack
常用es语法
版本:Elasticsearch 7.9.0
删除索引
DELETE mall.completion
创建索引,并指定settings
PUT mall.completion
{
"settings":{
"analysis":{
"analyzer":{
"ik_smart_pinyin":{
"type":"custom",
"tokenizer":"ik_smart",
"filter":["g_pinyin","word_delimiter"]
},
"ik_max_word_pinyin":{
"type":"custom",
"tokenizer":"ik_max_word",
"filter":["g_pinyin","word_delimiter"]
}
},
"filter":{
"g_pinyin":{
"type":"pinyin",
"keep_separate_first_letter":false,
"keep_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"lowercase":true,
"remove_duplicated_term":true
}
}
}
},
"mappings": {
"properties":
{
"kw_completion": {
"type": "completion"
},
"kw_text":{
"type": "text",
"analyzer":
"ik_smart_pinyin"
}
}
}
}
查看索引设置
GET mall.completion/_settings
查看mapping结构
GET mall.completion/_mapping
批量插入数据
POST _bulk/?refresh=true
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目","kw_text": "项目"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目进度","kw_text": "项目进度"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目管理","kw_text": "项目管理"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目进度及调整 汇总.doc_文档","kw_text": "项目进度及调整 汇总.doc_文档"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目","kw_text": "项目"}
查看指定分词器对文本进行分词的结果
GET mall.completion/_analyze
{
"analyzer": "ik_smart_pinyin",
"text": "很棒的冬天暖心羽绒服"
}
根据字段的mapping,进行分词测试
GET mall.completion/_analyze
{
"field": "kw_text",
"text": "很棒的冬天暖心羽绒服"
}
查询文档
GET mall.completion/_search
{
"query": {
"match":
{
"kw_text": "项目"
}
}
}
查看文档中的分词结果
GET
mall.completion/_doc/CYlJTnUBrvWtEbASfvRa/_termvectors?fields=kw_text
使用completion获取搜索补全建议(前缀搜索)
GET mall.completion/_search
{
"suggest":
{
"my-completion": {
"prefix": "项目",
"completion": {
"field":
"kw_completion",
"size": 20,
"skip_duplicates":
true
}
}
}
}
获取搜索建议词 (xang为拼写错误,会建议为:xiang)
GET mall.completion/_search
{
"suggest": {
"my-suggestion":
{
"text": "xang",
"term": {
"suggest_mode":
"missing",
"field": "kw_text"
}
}
}
}
多字段匹配案例
GET mall.completion/_search
{
"query":{
"multi_match":
{
"query": "米",
"fields":
["name","description","brandName","labelName","menuCategoryNamePath"]
}
}
}
查询包含字段"keyword"的文档
GET mall.completion/_search
{
"query":{
"exists":
{
"field": "keyword"
}
}
}
多条件查询语法案例
must 文档 必须 匹配这些条件才能被包含进来。
must_not 文档 必须不 匹配这些条件才能被包含进来。
should 如果满足这些语句中的任意语句,将增加_score
,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter 必须
匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
{
"bool":
{
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": {
"tag": "spam" }},
"should": [
{ "match": { "tag": "starred"
}}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte":
"2014-01-01" }}},
{
"range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks"
}}
]
}
}
}
}
其他推荐阅读
ElasticSearch 电商搜索实现(按"地里坐标"排序)
Implementing A Modern E-Commerce Search
==============================================================================
over,谢谢查阅,觉得文章对你有收获,请多帮推荐。欢迎向我提供更好的资料信息。
Elasticsearch搜索资料汇总的更多相关文章
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- iOS超全开源框架、项目和学习资料汇总(5)AppleWatch、经典博客、三方开源总结篇
完整项目 v2ex – v2ex 的客户端,新闻.论坛.apps-ios-wikipedia – apps-ios-wikipedia 客户端.jetstream-ios – 一款 Uber 的 MV ...
- 【转】iOS超全开源框架、项目和学习资料汇总
iOS超全开源框架.项目和学习资料汇总(1)UI篇iOS超全开源框架.项目和学习资料汇总(2)动画篇iOS超全开源框架.项目和学习资料汇总(3)网络和Model篇iOS超全开源框架.项目和学习资料汇总 ...
- 机器学习&深度学习经典资料汇总,data.gov.uk大量公开数据
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- MongoDB资料汇总专题[转发]
转发下..这个哥收集的很全 MongoDB资料汇总专题 作者:nosqlfan http://blog.nosqlfan.com/html/3548.html 最后更新时间:2013-04-22 1. ...
- (zhuan) 深度学习全网最全学习资料汇总之模型介绍篇
This blog from : http://weibo.com/ttarticle/p/show?id=2309351000224077630868614681&u=5070353058& ...
- MongoDB资料汇总专题
原文地址:http://bbs.chinaunix.net/thread-3675396-1-1.html 上一篇Redis资料汇总专题很受大家欢迎,这里将MongoDB的系列资料也进行了简单整理.希 ...
- Java进阶资料汇总
Java经过将近20年的发展壮大,框架体系已经丰满俱全:从前端到后台到数据库,从智能终端到大数据都能看到Java的身影,个人感觉做后台进要求越来越高,越来越难. 为什么现在Java程序员越来越难做,一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
随机推荐
- Go 包管理历史以及 Go mod 使用
之前也写过 Go 管理依赖工具 godep 的使用,当时看 godep 使用起来还是挺方便,其原因主要在于有总比没有强.关于依赖管理工具其实还是想从头聊聊这个需求以及大家做这个功能的各种出发点. GO ...
- Linux系统Yum仓库制作
在使用Linux系统的时候,通常需要安装许多软件,Linux系统通常安装软件有源码包安装(文件格式:.tar.gz 或.tar.bz2:安装过程:解压.环境检查.编译和安装).Rpm包安装(文件格式: ...
- Spring Boot + Druid 多数据源绑定
date: 2019-12-19 14:40:00 updated: 2019-12-19 15:10:00 Spring Boot + Druid 多数据源绑定 版本环境:Spring Boot 2 ...
- Redis分布式锁及分区
以下内容是翻译的官网文档RedLock和分区部分,可以简单了解分布式锁在redis如何实现及其方式 redis分区的方法 redis实现的分布式锁RedLock算法,分布式锁,即在多个master上获 ...
- 2. HttpRunnner录制生成用例
录制生成用例 为了简化测试用例的编写工作,HttpRunner 实现了测试用例生成的功能,对应的转换工具为一个独立的项目:har2case. 简单来说,就是当前主流的抓包工具和浏览器都支持将抓取得到的 ...
- 什么PO模式?
PO模式PO是Page Object的缩写,PO模式是自动化测试项目开发实践的最佳设计模式之一.核心思想是通过对界面元素的封装减少冗余代码,同时在后期维护中,若元素定位发生变化, 只需要调整页面元素封 ...
- STM32移植FreeRTOS(1)
"STM32F103VET6<_>FreeRTOS" 1.项目功能实现 1)LED灯定时闪烁 2)KEY按键检测 3)FreeRTOS任务创建 4)串口输出程序运行状态 ...
- python爬虫自定义header头部
一.Handler处理器 和 自定义Opener 关注公众号"轻松学编程"了解更多. opener是 urllib.OpenerDirector 的实例,我们之前一直都在使用的ur ...
- MyBatis重要核心概念
一.SqlSessionFactoryBuilder 从命名上可以看出,这个是一个 Builder 模式的,用于创建 SqlSessionFactory 的类.SqlSessionFactoryBui ...
- Android Google官方文档解析之——Device Compatibility
Android is designed to run on many different types of devices, from phones to tablets and television ...