Elasticsearch搜索资料汇总
Elasticsearch 简介
Elasticsearch(ES)是一个基于Lucene
构建的开源分布式搜索分析引擎,可以近实时的索引、检索数据。具备高可靠、易使用、社区活跃等特点,在全文检索、日志分析、监控分析等场景具有广泛应用。
lucene
Elasticsearch 中文社区:https://elasticsearch.cn/article/
Elasticsearch 官方文档:https://www.elastic.co/guide/index.html
Elasticsearch 各客户端API(eg:.NET、JAVA、Python、Go)
Elasticsearch .net client NEST 5.x 使用总结(初始化、查询、权重、排序、聚合等)
Elasticsearch 客户端SDK使用建议:创建索引的Setting和mapping使用elasticsearch 提供的DSL语法更加简单。因为客户端API代码里面只提供基础的SDK,如(ik拼音等)插件就没有对应接口提供
Elasticsearch术语(索引、类型、文档、集群、节点、分片)
ES数据架构的主要概念(与关系数据库Mysql对比)
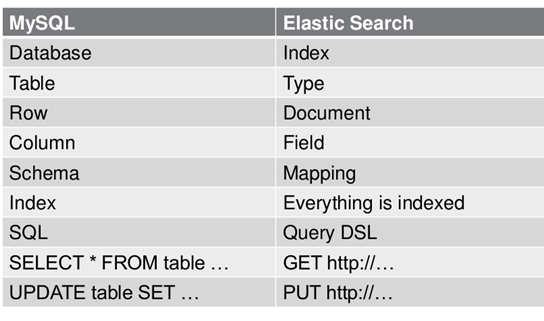
在ES
早期版本,一个索引下是可以有多个Type
,从7.0
开始,一个索引只有一个Type,即_doc。一个Type 下的文档,都有相同的字段(Field)
安装
ELK
ELK 是elastic 公司旗下三款产品ElasticSearch
、Logstash 、Kibana 的首字母组合。
#、ElasticSearch 是一个基于Lucene
构建的开源,分布式,RESTful
搜索引擎。
#、Logstash 传输和处理你的日志、事务或其他数据。
#、Kibana 将Elasticsearch
的数据分析并渲染为可视化的报表。
分词器
分词器是专门处理分词的组件,分词器由如下三部分组成:
1、Character Filters:针对原始文本处理,比如:去除html 标签
2、Tokenizer:按照规则切分为单词,比如:按照空格切分
3、Token Filters:将切分的单词进行加工,比如:大写转小写,删除stopwords,拼音,同义词等
analyzer = CharFilters(0个或多个)+
Tokenizer(一个) +
TokenFilters(0个或多个)
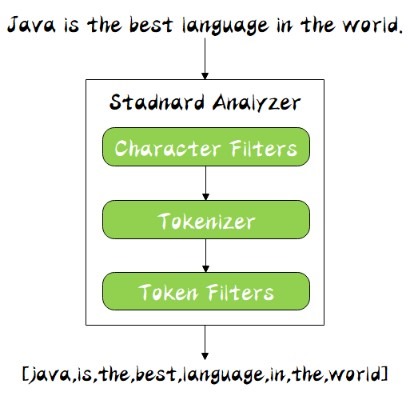
从图中能够看出,从上到下依次通过Character
Filters,Tokenizer
以及Token
Filters,这个顺序比较好理解,一个文本进来确定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
elasticSearch Analysis Token Filters作用及相关样例
ElasticSearch查看字段分词结果 (便于查为什么匹配不出的问题)
Elasticsearch7 分词器(内置分词器和自定义分词器)
Elasticsearch-Analysis-IK中文分词器配置使用
elasticsearch 之分词器配置 (IK+pinyin)
Elasticsearch 使用ik中文分词器增加分词热词(自定义词)
Elasticsearch mapping
搞懂Elasticsearch 之Mapping (Reindex)
Mapping中的store属性(按需查询字段)
Elasticsearch中的store field跟non-store field的区别
Elasticsearch 理解mapping中的store属性
Elasticsearch 动态模板(dynamic_templates)
normalizer 的使用
ElasticSearch Normalizer 的使用方法
Adding normalizer for all keyword fields NEST
Elasticsearch DLS语法
Elasticsearch 查询语法(模糊、精确、sort、相关性、and|or、slop间隔等)
Elasticsearch 查询语法(多条件bool复杂查询(must、should、filter)、日期范围查询)
Elasticsearch 查询语法(bool复杂查询、operator(||、&&、!、+))
ElasticSearch 组合多查询(bool, must, should, must_not, filter)
Elasticsearch中match、match_phrase、query_string和term的区别
相关性score
ElasticSearch 的分数(_score) 是怎么计算得出 (2.X & 5.X)
ElasticSearch 多级排序(eg:产品要根据:销量、热度、相关性排序)
Elasticsearch 搜索条件权重控制(boost)-- 默认情况下,搜索条件的权重都是1
聚合查询
Elasticsearch 聚合语法(Aggregations)
分页查询
Elasticsearch 查询语法(使用scroll响应式返回大集合文档)
Elasticsearch 高亮显示匹配关键词(Highlight)
同义词
elasticsearch 使用同义词(synonym.txt)
搜索建议词(Suggest功能)
ElasticSearch使用completion实现补全功能
Elasticsearch Suggester详解(自动补全)
elasticsearch 7.0 新特性之 search as you type
安全性
Meow攻击删除开放的的Elasticsearch(及MongoDB) 索引,建一堆以Meow结尾的奇奇怪怪的索引(如:m3egspncll-meow)----关闭外网访问端口,或至少修改ES默认端口
用nginx给kibana、elasticsearch做权限认证
集中式日志分析平台- ELK Stack - 安全解决方案 X-Pack
常用es语法
版本:Elasticsearch 7.9.0
删除索引
DELETE mall.completion
创建索引,并指定settings
PUT mall.completion
{
"settings":{
"analysis":{
"analyzer":{
"ik_smart_pinyin":{
"type":"custom",
"tokenizer":"ik_smart",
"filter":["g_pinyin","word_delimiter"]
},
"ik_max_word_pinyin":{
"type":"custom",
"tokenizer":"ik_max_word",
"filter":["g_pinyin","word_delimiter"]
}
},
"filter":{
"g_pinyin":{
"type":"pinyin",
"keep_separate_first_letter":false,
"keep_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"lowercase":true,
"remove_duplicated_term":true
}
}
}
},
"mappings": {
"properties":
{
"kw_completion": {
"type": "completion"
},
"kw_text":{
"type": "text",
"analyzer":
"ik_smart_pinyin"
}
}
}
}
查看索引设置
GET mall.completion/_settings
查看mapping结构
GET mall.completion/_mapping
批量插入数据
POST _bulk/?refresh=true
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目","kw_text": "项目"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目进度","kw_text": "项目进度"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目管理","kw_text": "项目管理"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目进度及调整 汇总.doc_文档","kw_text": "项目进度及调整 汇总.doc_文档"}
{ "index": { "_index": "mall.completion"
}}
{ "kw_completion": "项目","kw_text": "项目"}
查看指定分词器对文本进行分词的结果
GET mall.completion/_analyze
{
"analyzer": "ik_smart_pinyin",
"text": "很棒的冬天暖心羽绒服"
}
根据字段的mapping,进行分词测试
GET mall.completion/_analyze
{
"field": "kw_text",
"text": "很棒的冬天暖心羽绒服"
}
查询文档
GET mall.completion/_search
{
"query": {
"match":
{
"kw_text": "项目"
}
}
}
查看文档中的分词结果
GET
mall.completion/_doc/CYlJTnUBrvWtEbASfvRa/_termvectors?fields=kw_text
使用completion获取搜索补全建议(前缀搜索)
GET mall.completion/_search
{
"suggest":
{
"my-completion": {
"prefix": "项目",
"completion": {
"field":
"kw_completion",
"size": 20,
"skip_duplicates":
true
}
}
}
}
获取搜索建议词 (xang为拼写错误,会建议为:xiang)
GET mall.completion/_search
{
"suggest": {
"my-suggestion":
{
"text": "xang",
"term": {
"suggest_mode":
"missing",
"field": "kw_text"
}
}
}
}
多字段匹配案例
GET mall.completion/_search
{
"query":{
"multi_match":
{
"query": "米",
"fields":
["name","description","brandName","labelName","menuCategoryNamePath"]
}
}
}
查询包含字段"keyword"的文档
GET mall.completion/_search
{
"query":{
"exists":
{
"field": "keyword"
}
}
}
多条件查询语法案例
must 文档 必须 匹配这些条件才能被包含进来。
must_not 文档 必须不 匹配这些条件才能被包含进来。
should 如果满足这些语句中的任意语句,将增加_score
,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter 必须
匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
{
"bool":
{
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": {
"tag": "spam" }},
"should": [
{ "match": { "tag": "starred"
}}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte":
"2014-01-01" }}},
{
"range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks"
}}
]
}
}
}
}
其他推荐阅读
ElasticSearch 电商搜索实现(按"地里坐标"排序)
Implementing A Modern E-Commerce Search
==============================================================================
over,谢谢查阅,觉得文章对你有收获,请多帮推荐。欢迎向我提供更好的资料信息。
Elasticsearch搜索资料汇总的更多相关文章
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- iOS超全开源框架、项目和学习资料汇总(5)AppleWatch、经典博客、三方开源总结篇
完整项目 v2ex – v2ex 的客户端,新闻.论坛.apps-ios-wikipedia – apps-ios-wikipedia 客户端.jetstream-ios – 一款 Uber 的 MV ...
- 【转】iOS超全开源框架、项目和学习资料汇总
iOS超全开源框架.项目和学习资料汇总(1)UI篇iOS超全开源框架.项目和学习资料汇总(2)动画篇iOS超全开源框架.项目和学习资料汇总(3)网络和Model篇iOS超全开源框架.项目和学习资料汇总 ...
- 机器学习&深度学习经典资料汇总,data.gov.uk大量公开数据
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- MongoDB资料汇总专题[转发]
转发下..这个哥收集的很全 MongoDB资料汇总专题 作者:nosqlfan http://blog.nosqlfan.com/html/3548.html 最后更新时间:2013-04-22 1. ...
- (zhuan) 深度学习全网最全学习资料汇总之模型介绍篇
This blog from : http://weibo.com/ttarticle/p/show?id=2309351000224077630868614681&u=5070353058& ...
- MongoDB资料汇总专题
原文地址:http://bbs.chinaunix.net/thread-3675396-1-1.html 上一篇Redis资料汇总专题很受大家欢迎,这里将MongoDB的系列资料也进行了简单整理.希 ...
- Java进阶资料汇总
Java经过将近20年的发展壮大,框架体系已经丰满俱全:从前端到后台到数据库,从智能终端到大数据都能看到Java的身影,个人感觉做后台进要求越来越高,越来越难. 为什么现在Java程序员越来越难做,一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
随机推荐
- 论文解读《ImageNet Classification with Deep Convolutional Neural Networks》
这篇论文提出了AlexNet,奠定了深度学习在CV领域中的地位. 1. ReLu激活函数 2. Dropout 3. 数据增强 网络的架构如图所示 包含八个学习层:五个卷积神经网络和三个全连接网络,并 ...
- java数据结构-04单循环链表
单循环链表与单链表的不同是,单循环链表尾结点的next指向第一个结点(或头结点) 代码: 无头结点: public class SingleCircleLinkedList<E> ext ...
- 专攻知识小点——回顾JavaWeb中的servlet(三)
HttpSession基本概述 ** ** 1.HttpSession:是服务器端的技术.和Cookie一样也是服务器和客户端的会话.获得该对象是通过HTTPServletRequest的方法getS ...
- python机器学习识别手写数字
手写数字识别 关注公众号"轻松学编程"了解更多. 导包 import numpy as np import matplotlib.pyplot as plt %matplotlib ...
- 微信小程序授权页面
这里也是比较简单的 直接复制粘贴就可以用,可能图片位置不对.. <template> <view id="imporwer"> <image src= ...
- (二)http请求方法和状态码
1.HTTP请求方法 根据 HTTP 标准,HTTP 请求可以使用多种请求方法. HTTP1.0 定义了三种请求方法: GET.POST 和 HEAD方法. HTTP1.1 新增了六种请求方法:OPT ...
- MySQL中load data infile将文件中的数据批量导入数据库
有时候我们需要将文件中的数据直接导入到数据库中,那么我们就可以使用load data infile,下面具体介绍使用方法. dao中的方法 @Autowired private JdbcTemplat ...
- leetcode95:jump game
题目描述 给出一个非负整数数组,你最初在数组第一个元素的位置 数组中的元素代表你在这个位置可以跳跃的最大长度 判断你是否能到达数组最后一个元素的位置 例如 A =[2,3,1,1,4], 返回 tru ...
- vuex和axios的基本操作
1.在src目录下创建一个api 是用于集中处理axios的相关配置 index.js就是处理axios的文件 具体如何使用axios 还请百度axios 2.URLs.js是存放需要请求的地址的 3 ...
- Netty源码解析 -- 零拷贝机制与ByteBuf
本文来分享Netty中的零拷贝机制以及内存缓冲区ByteBuf的实现. 源码分析基于Netty 4.1.52 Netty中的零拷贝 Netty中零拷贝机制主要有以下几种 1.文件传输类DefaultF ...