dsu on tree (树上启发式合并) 详解
一直都没出过算法详解,昨天心血来潮想写一篇,于是 dsu on tree 它来了
1、前置技能
1.链式前向星(vector 建图)
2.dfs 建树
3.剖分轻重链,轻重儿子
| 重儿子 | 一个结点的所有儿子中拥有最多子树的儿子 |
|---|---|
| 轻儿子 | 一个结点的所有儿子中不是重儿子的儿子 |
| 重边 | 父亲与重儿子的连边 |
| 轻边 | 父亲与轻儿子的连边 |
| 重链 | 一堆重边连接而成的链 |
| 轻链 | 一堆轻边连接而成的链 |
2、什么是 dsu on tree(树上启发式合并) ?
dsu on tree 其实就是个优雅的暴力算法,和它一起共被称为优雅暴力的算法还有莫队
所谓优雅的暴力大概是指:“优雅思想,暴力的操作”
例如莫队我们知道它是将整个区间分块,再将询问的区间排序,最后暴力的维护所有询问的区间
其中 "整个区间分块,询问的区间排序" 为优雅的思想,而 "暴力的维护所有询问的区间" 为暴力的操作
因为需要将询问的区间排序,我们就需要先将询问的区间保存下来,也就是要离线
dsu on tree 和莫队类似,也需要离线(它们同属于静态算法)
dsu on tree 优雅的思想:
对于以 u 为根的子树
①. 先统计它轻子树(轻儿子为根的子树)的答案,统计完后删除信息
②. 再统计它重子树(重儿子为根的子树)的答案 ,统计完后保留信息
③. 然后再将重子树的信息合并到 u上
④. 再去遍历 u 的轻子树,然后把轻子树的信息合并到 u 上
⑤. 判断 u 的信息是否需要传递给它的父节点(u 是否是它父节点的重儿子)
dsu on tree 暴力的操作
dsu on tree 暴力的操作体现于统计答案上(不同的题目统计方式不一样)
3、dsu on tree 的过程演示及代码
1.图示
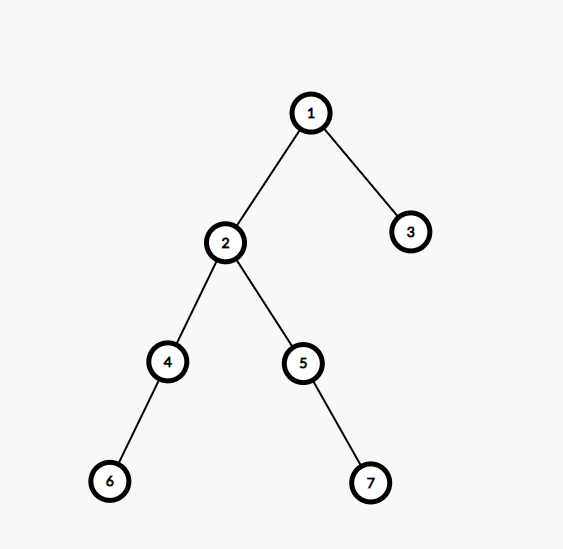
1 的重儿子为 2,轻儿子为 3
2 的重儿子为 4,轻儿子为 5
3 没有重儿子,没有轻儿子
4 的重儿子为 6,没有轻儿子
5 的重儿子为 7,没有轻儿子
6 没有重儿子,没有轻儿子
7 没有重儿子,没有轻儿子
为了更好观看,我们将节点与其重儿子的连线描红
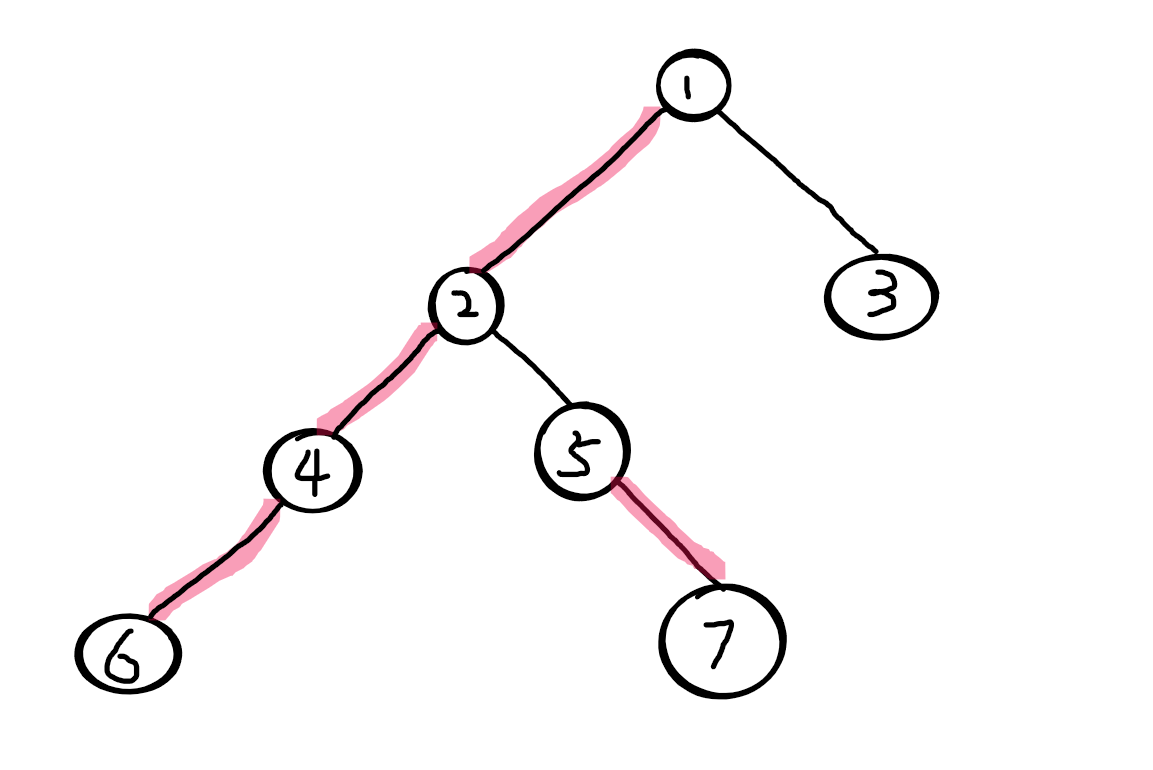
我们从根节点1进入,先找1的轻儿子,发现3,进入3
3没有别的儿子可以进入了,于是统计3的信息
统计完后即将返回父节点 1
因为1-3的边没有被描红边、3不是1的重儿子(不传递3的信息),所以删除3的信息再返回 1
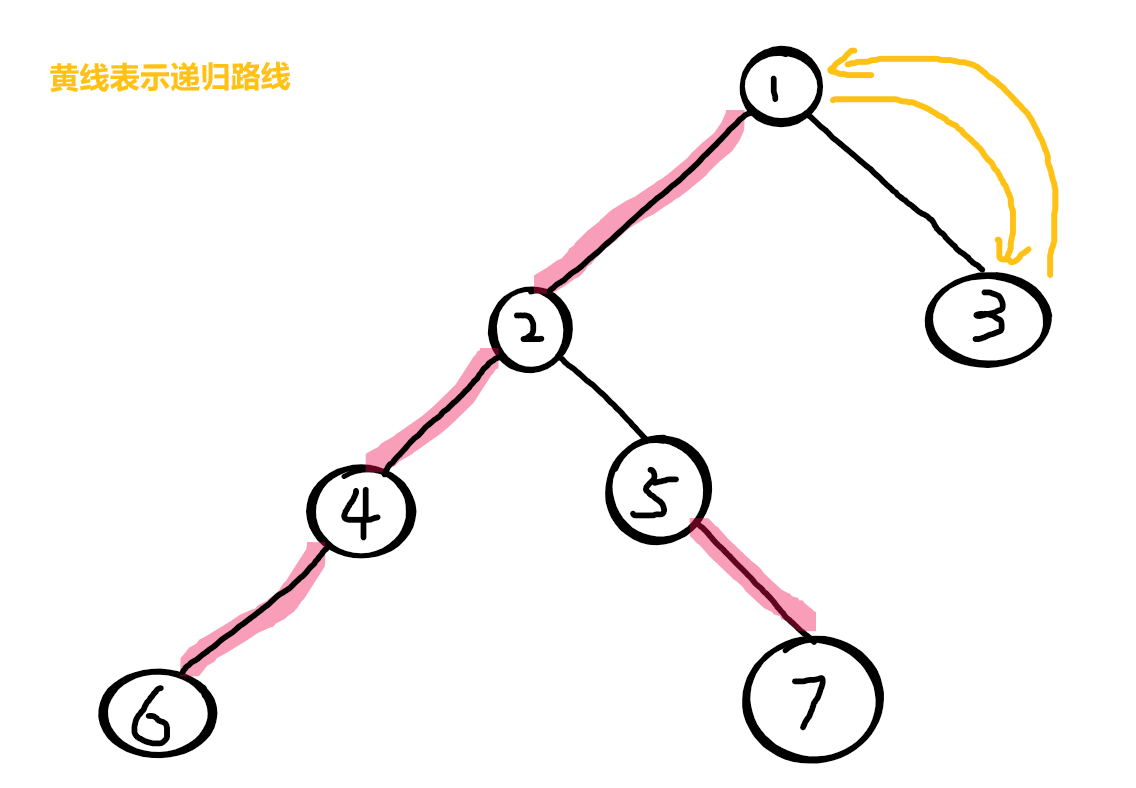
发现1没有别的轻儿子了,就找重儿子,发现2,进入2
进入2后,再找2的轻儿子,发现5,进入5
发现5没有轻儿子了,就找重儿子,发现7,进入 7
7 没有别的儿子可以进入了,于是统计 7 的信息
统计完后即将返回父节点 5
因为边5-7 有被描红边、7是5的重儿子,所以保留7的信息直接返回 5(传递7的信息的给5)
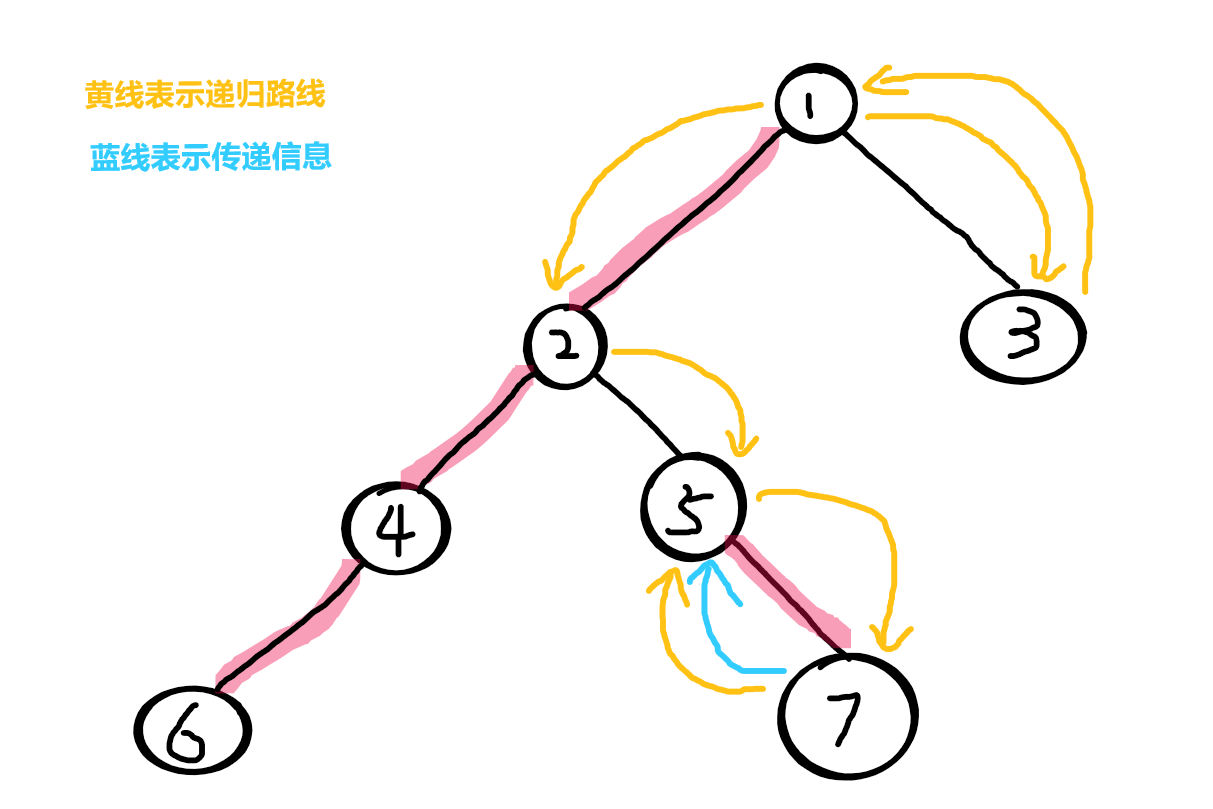
5 所有儿子都进入过了,于是统计 5 的信息
统计完后即将范围父节点 2
因为边2-5 没有被描红边、5不是2的重儿子,所以删除5的信息再返回 2
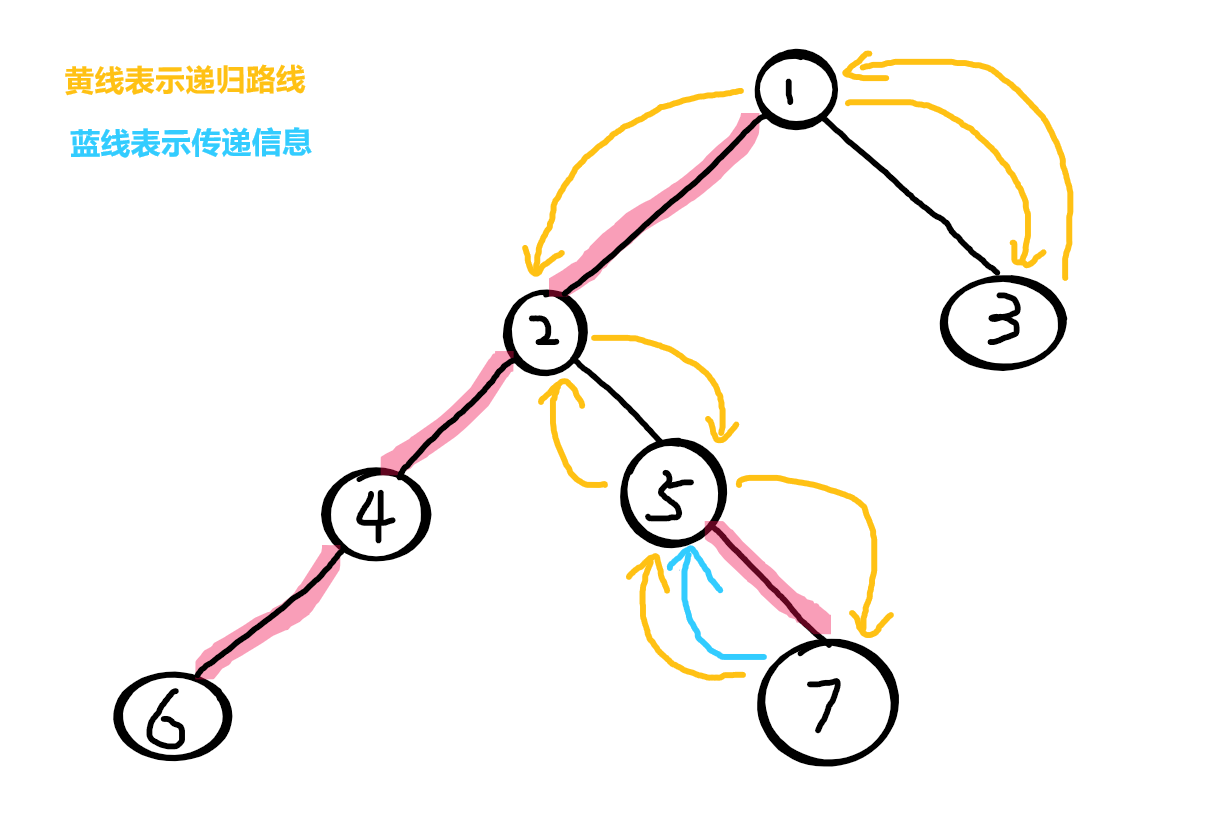
发现2没有其它轻儿子了,就找重儿子,发现4,进入4
发现4没有其它轻儿子了,就找重儿子,发现6,进入6
6 没有别的儿子可以进入了,于是统计 6 的信息
统计完后即将返回父节点 4
因为边4-6 有被描红边,6是4的重儿子,所以保留6的信息直接返回 4(传递6的信息的给4)
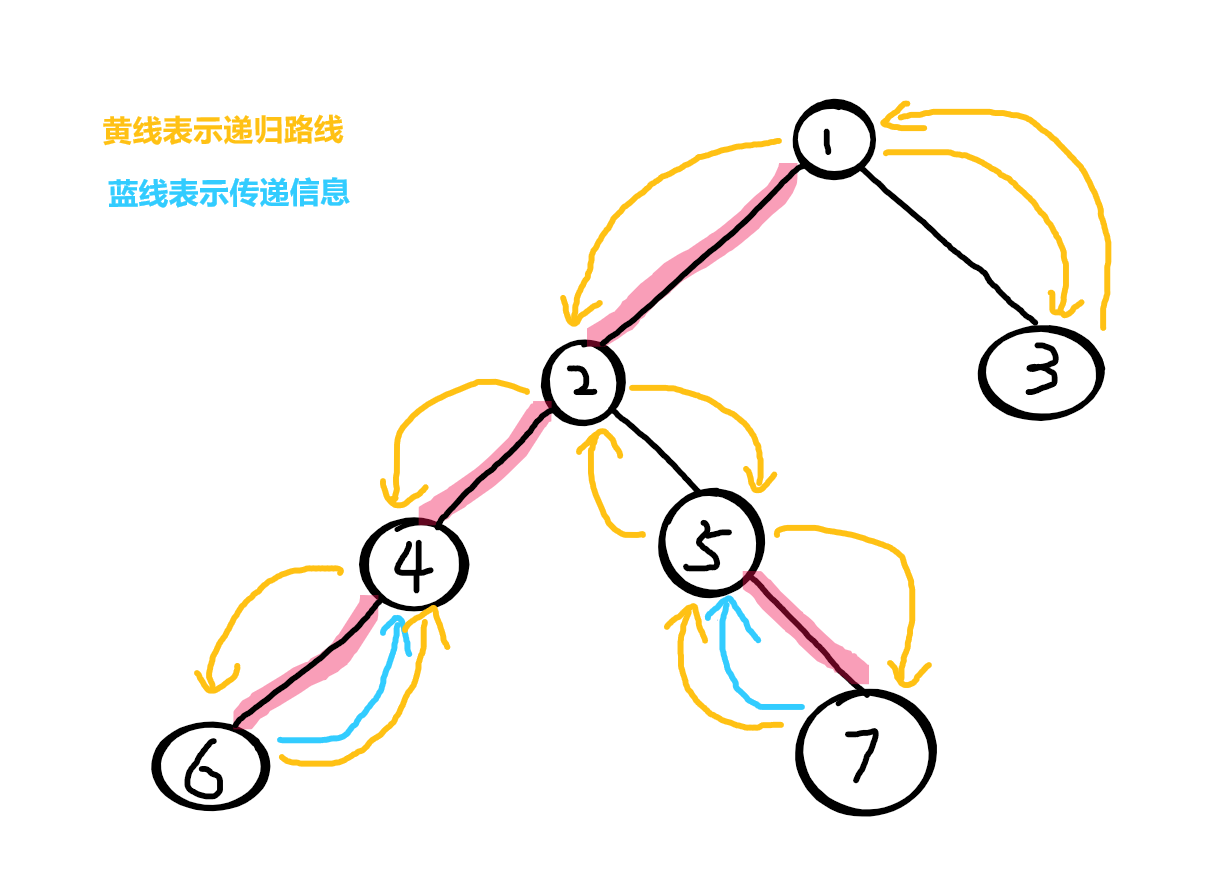
4 所有儿子都进入过了,于是统计 4 的信息
统计完后即将返回父节点 2
因为边2-4 有被描红边,4是2的重儿子,所以保留4的信息直接返回2(传递4的信息的给2)
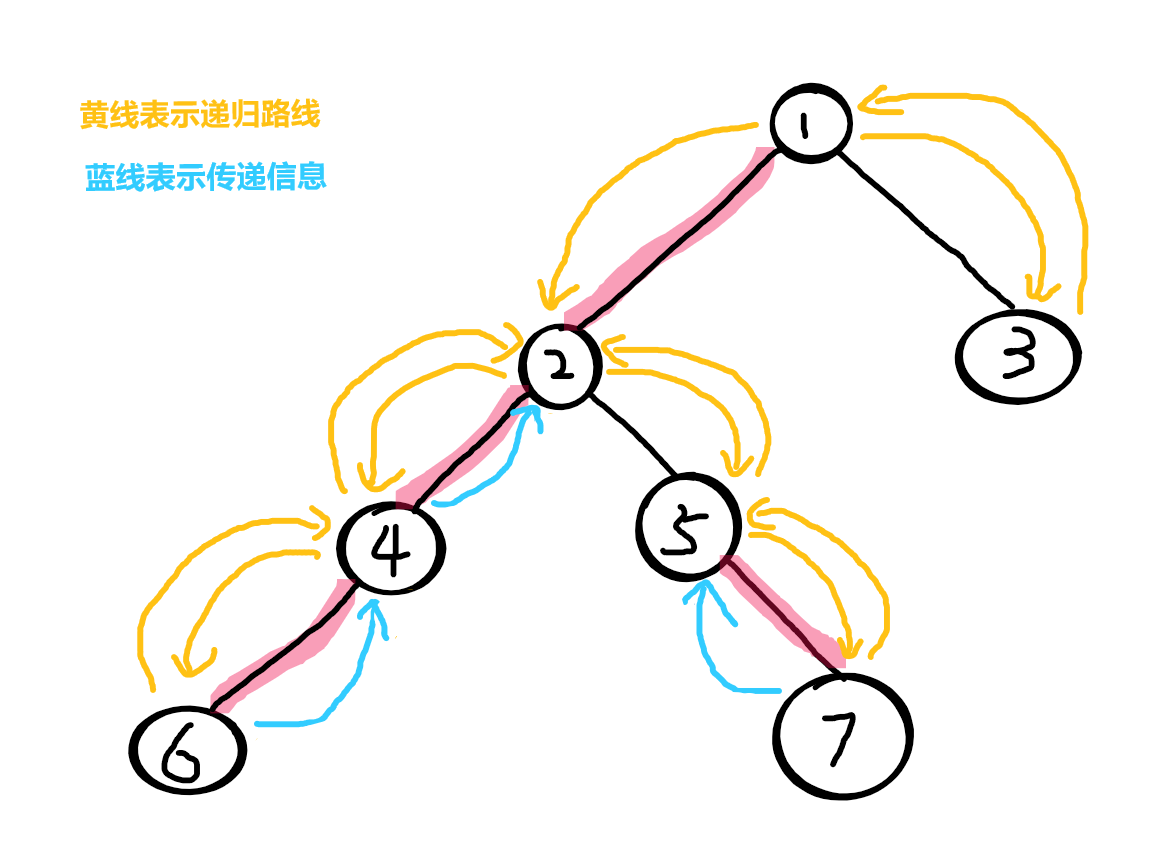
2 所有儿子都进入过了,于是统计 2 的信息
2 接受了4传递的信息,但是并没有接受5传递给它的信息(被删除了)
于是 2 再进入5(轻儿子),统计一遍以 5 为根的子树的信息,再将该信息合并到 2上

统计完后 2 后即将返回父节点 1
因为边1-2 有被描红边,2是1的重儿子,所以保留2的信息直接返回1(传递2的信息的给1)
1 所有儿子都进入过了,于是统计 1 的信息
1 接受了2传递的信息,但是并没有接受3传递给它的信息(被删除了)
于是 1 再进入3(轻儿子),统计一遍以 3 为根的子树的信息,再将该信息合并到 1 上
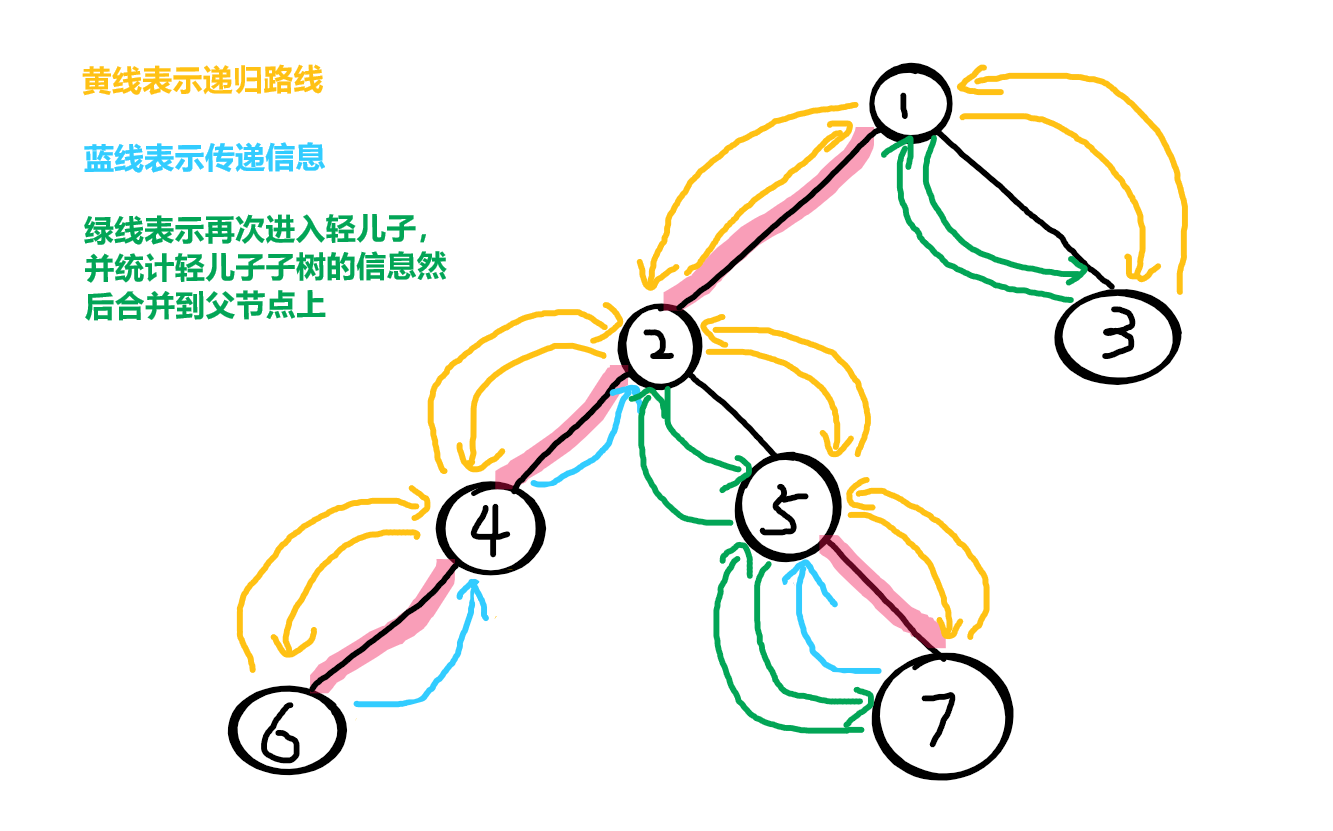
至此,整个 dsu on tree 的过程结束
2.代码
struct Edge{
int nex , to;
}edge[N << 1];
int head[N] , TOT;
void add_edge(int u , int v) // 链式前向星建图
{
edge[++ TOT].nex = head[u] ;
edge[TOT].to = v;
head[u] = TOT;
}
int sz[N]; // sz[u] 表示以 u 为根的子树大小
int hson[N]; // hson[u] 表示 u 的重儿子
int HH; // HH 表示当前根节点的重儿子
void dfs(int u , int far)
{
sz[u] = 1;
for(int i = head[u] ; i ; i = edge[i].nex) // 链式前向星
{
int v = edge[i].to;
if(v == far) continue ;
dfs(v , u);
sz[u] += sz[v];
if(sz[v] > sz[hson[u]]) hson[u] = v; // 选择 u 的重儿子
}
}
void calc(int u , int far , int val) // 统计答案
{
if(val == 1) ...; // val = 1,则添加信息
else ...; // val = -1,则删除信息
......
for(int i = head[u] ; i ; i = edge[i].nex)
{
int v = edge[i].to;
if(v == far || v == HH) continue ; // 如果 v 是当前根节点的重儿子,则跳过
calc(v , u , val);
}
}
void dsu(int u , int far , int op) // op 等于0表示不保留信息,等于1表示保留信息
{
for(int i = head[u] ; i ; i = edge[i].nex)
{
int v = edge[i].to;
if(v == far || v == hson[u]) continue ; // 如果 v 是重儿子或者父亲节点就跳过
dsu(v , u , 0); // 先遍历轻儿子 ,op = 0 :轻儿子的答案不做保留
}
if(hson[u]) dsu(hson[u] , u , 1) , HH = hson[u];
// 轻儿子都遍历完了,如果存在重儿子,遍历重儿子(事实上除了叶子节点每个点都必然有重儿子)
// op = 1 , 保留重儿子的信息
// 当前是以 u 为根节点的子树,所以根节点的重儿子 HH = hson[u]
calc(u , far , 1); // 再次遍历轻儿子统计答案
HH = 0; // 遍历结束 ,即将返回父节点,所以取消标记 HH
if(!op) calc(u , far , -1); // 如果 op = -1,则 u 对于它的父亲来说是轻儿子,不需要将信息传递给它的父亲
}
4.经典例题讲解
5.难题进阶
这是道较难的题,听说这也是 dsu on tree 的发明人专门为这个算法出的题
| 题目编号 | 题目链接 | 题解链接 |
|---|---|---|
| CF741D | https://codeforces.com/contest/741/problem/D | https://www.cnblogs.com/StarRoadTang/p/14028301.html |
┏┛ ┻━━━━━┛ ┻┓
┃ ┃
┃ ━ ┃
┃ ┳┛ ┗┳ ┃
┃ ┃
┃ ┻ ┃
┃ ┃
┗━┓ ┏━━━┛
┃ ┃ 神兽保佑
┃ ┃ 代码无BUG!
┃ ┗━━━━━━━━━┓
┃ ┣┓
┃ ┏┛
┗━┓ ┓ ┏━━━┳ ┓ ┏━┛
┃ ┫ ┫ ┃ ┫ ┫
┗━┻━┛ ┗━┻━┛dsu on tree (树上启发式合并) 详解的更多相关文章
- dsu on tree 树上启发式合并 学习笔记
近几天跟着dreagonm大佬学习了\(dsu\ on\ tree\),来总结一下: \(dsu\ on\ tree\),也就是树上启发式合并,是用来处理一类离线的树上询问问题(比如子树内的颜色种数) ...
- dsu on tree[树上启发式合并学习笔记]
dsu on tree 本质上是一个 启发式合并 复杂度 \(O(n\log n)\) 不支持修改 只能支持子树统计 不能支持链上统计- 先跑一遍树剖的dfs1 搞出来轻重儿子- 求每个节点的子树上有 ...
- dsu on tree(树上启发式合并)
简介 对于一颗静态树,O(nlogn)时间内处理子树的统计问题.是一种优雅的暴力. 算法思想 很显然,朴素做法下,对于每颗子树对其进行统计的时间复杂度是平方级别的.考虑对树进行一个重链剖分.虽然都基于 ...
- 树上启发式合并(dsu on tree)学习笔记
有丶难,学到自闭 参考的文章: zcysky:[学习笔记]dsu on tree Arpa:[Tutorial] Sack (dsu on tree) 先康一康模板题吧:CF 600E($Lomsat ...
- 【Luogu U41492】树上数颜色——树上启发式合并(dsu on tree)
(这题在洛谷主站居然搜不到--还是在百度上偶然看到的) 题目描述 给一棵根为1的树,每次询问子树颜色种类数 输入输出格式 输入格式: 第一行一个整数n,表示树的结点数 接下来n-1行,每行一条边 接下 ...
- 神奇的树上启发式合并 (dsu on tree)
参考资料 https://www.cnblogs.com/zhoushuyu/p/9069164.html https://www.cnblogs.com/candy99/p/dsuontree.ht ...
- CF741D Arpa’s letter-marked tree and Mehrdad’s Dokhtar-kosh paths 树上启发式合并(DSU ON TREE)
题目描述 一棵根为\(1\) 的树,每条边上有一个字符(\(a-v\)共\(22\)种). 一条简单路径被称为\(Dokhtar-kosh\)当且仅当路径上的字符经过重新排序后可以变成一个回文串. 求 ...
- 树上启发式合并(dsu on tree)
树上启发式合并属于暴力的优化,复杂度O(nlogn) 主要解决的问题特点在于: 1.对于树上的某些信息进行查询 2.一般问题的解决不包含对树的修改,所有答案可以离线解决 算法思路:这类问题的特点在于父 ...
- 【CF375D】Trees and Queries——树上启发式合并
(题面不是来自Luogu) 题目描述 有一个大小为n且以1为根的树,树上每个点都有对应的颜色ci.现给出m次询问v, k,问以v为根的子树中有多少种颜色至少出现了k次. 输入格式 第一行两个数n,m表 ...
随机推荐
- spring-boot-route(二十一)quartz实现动态定时任务
Quartz是一个定时任务的调度框架,涉及到的主要概念有以下几个: Scheduler:调度器,所有的调度都由它控制,所有的任务都由它管理. Job:任务,定义业务逻辑. JobDetail:基于Jo ...
- 经典剪枝算法的例题——Sticks详细注释版
这题听说是道十分经典的剪枝算的题目,不要问我剪枝是什么,我也不知道,反正我只知道用到了深度搜索 我参考了好多资料才悟懂,然后我发现网上的那些大神原理讲的很明白,但代码没多少注释,看的很懵X,于是我抄起 ...
- vue学习第一部
目录 基础操作 vue基础使用 步骤 vue的框架思想(mvvm) 显示数据 vue 常用指令 属性操作 事件绑定 操作样式 条件渲染指令 列表渲染指令 vue对象提供的属性功能 过滤器 计算和侦听属 ...
- windows下安装RabbitMq和常用命令
----RabbitMq安装-----windows下安装:(1)首先windows下安装好了erlang和rabbitmq.如下地址同时下载和安装:Erlang:http://www.erlang. ...
- java数据结构-09双端队列
一.相关概念: (Deque)双端队列能够在队头.队尾进行添加.删除等操作 二.接口设计: 三.代码实现 public class Deque<E> { private List< ...
- C语言程序设计之 数组2020-10-28
C语言程序设计之 数组2020-10-28 整理: 第一题:求最小数与第一个数交换 [问题描述] 输入一个正整数n (1<n<=100),再输入n个整数,将最小值与第一个数交换,然后输 ...
- MySQL全面瓦解4:数据定义-DDL
前言 SQL的语言分类主要包含如下几种: DDL 数据定义语言 create.drop.alter 数据定义语言 create.drop.alter 语句 . DML 数据操纵语言 insert.de ...
- selenium中如何保证操作元素的成功率?也就是说如何保证我点击的元素一定是可以点击的?
1.在寻找元素时,加上显示等待或者隐式等待,这样在对元素进行操作之前保证元素被找到,进而提高成功率: 2.在对元素操作之前,比如click,如果该元素未display(非hidden),就需要先滚动到 ...
- 推荐给 Java 程序员的 7 本书
< Java 编程思想> 适合各个阶段 Java 程序员的必备读物.书中对 Java 进行了详尽的介绍,与其它语言做了对比,解释了 Java 很多特性出现的原因和解决的问题.初学者可以通过 ...
- Java学习的第十二天
1.包名 2.接口不太懂. 3.明天开始学习第五章