ClickHouse安装使用(单机、集群、高可用)
Clickhouse版本:20.3.6.40-2

安装包地址:https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
一、单机版
1、安装依赖
yum install libicu.x86_64
2、下载安装包
http://repo.yandex.ru/clickhouse/rpm/
3、安装
rpm -ivh *.rpm --force --nodeps
4、修改数据、日志目录
vi /etc/clickhouse-server/config.xml
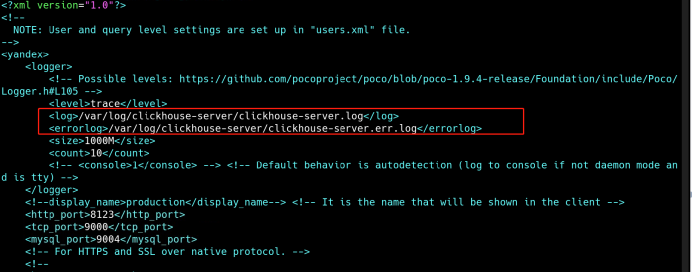
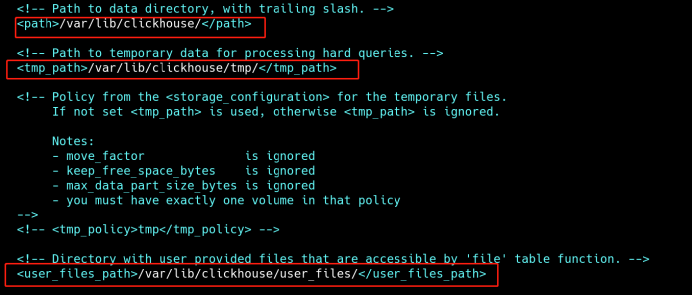
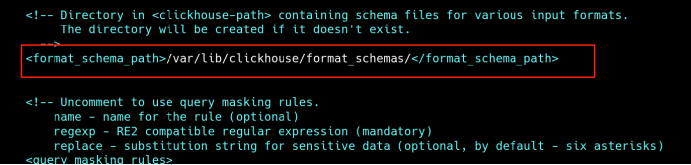
5、创建相关目录
只需创建log文件目录即可
mkdir /bigdata/clickhouse
mkdir /bigdata/clickhouse/log
chown clickhouse:clickhouse /bigdata/clickhouse
chown clickhouse:clickhouse /bigdata/clickhouse/log
6、启动
/etc/init.d/clickhouse-server start
/etc/init.d/clickhouse-server stop
7、登录
由于9000与其它服务端口冲突,故tcp端口更改为9011
clickhouse-client --host localhost --port 9011
二、集群版
1、修改配置文件(三分片、单副本)
分别在三个节点都创建文件,红色字体每个节点配置不一样
vim /etc/metrika.xml
<yandex>
<clickhouse_remote_servers>
<cluster-01>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>spbsjzy19</host>
<port>9011</port>
<user>rt</user>
<password>SPBsjzy@)@)</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>spbsjzy20</host>
<port>9011</port>
<user>rt</user>
<password>SPBsjzy@)@)</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>spbsjzy21</host>
<port>9011</port>
<user>rt</user>
<password>SPBsjzy@)@)</password>
</replica>
</shard>
</cluster-01>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>spbsjzy33</host>
<port>2181</port>
</node>
<node index="2">
<host>spbsjzy34</host>
<port>2181</port>
</node>
<node index="3">
<host>spbsjzy35</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<cluster>cluster-01</cluster>
<shard>01</shard>
<replica>spbsjzy19</replica>
<!-- <shard>02</shard>
<replica>spbsjzy20</replica>
<shard>03</shard>
<replica>spbsjzy21</replica>
-->
</macros>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
注意:
1) <macros> </macros>中的shard名
三个节点配置相同则在任意一个节点插入数据,其他节点都会查询到;不相同的话复制表之间数据不会同步(插入分布表,数据会随机分配到某个节点的复制表;插入任意一个节点的复制表,分布表可以查询到,其他节点复制表无法查到)
2) <macros> </macros>中 <cluster>表示集群名称,<shard>表示分片编号,<replica>表示副本标识,这里使用了cluster{cluster}-{shard}-{replica}的表示方式
3) <internal_replication>
如果设置为true,则往本地表写入数据时,总是写入到完整健康的副本里,然后由表自身完成复制,这就要求本地表是能自我复制的(推荐)。如果设置为false,则写入数据时,是写入到所有副本中。这时,是无法保证一致性的
4) <user></user><password></password>
添加完后使用默认default用户也可以查询分布表。
相关报错信息:
ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 516, host: spbsjzy20, port: 8123; Code: 516, e.displayText() = DB::Exception: Received from spbsjzy19:9011. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name. (version 20.3.6.40 (official build))
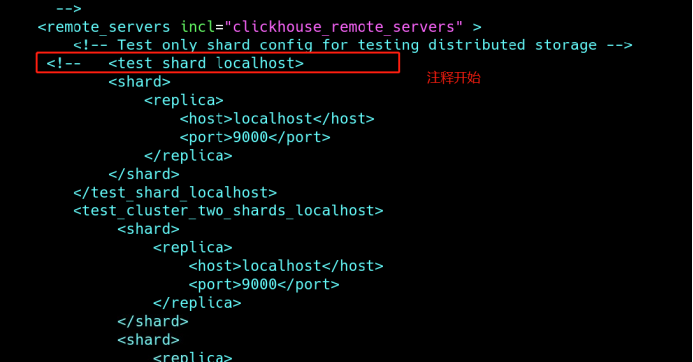
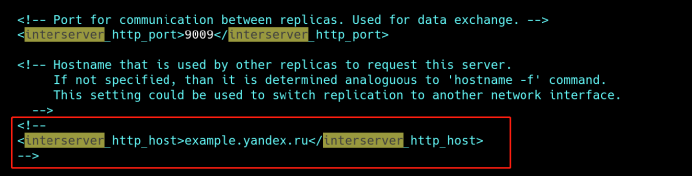
2、修改配置
vim /etc/clickhouse-server/config.xml
把注释打开,否则节点之间无法访问,分布表也无法查询其它节点数据
3、建议
生产中建议一般采用复制表和分布表;先创建复制表而后创建分布表,复制表用来存储数据,分布表用来查询和写入
ReplacingMergeTree:

4、创建表
分别在三个节点创建复制表:
分别在三个节点创建复制表:
CREATE TABLE default.test (`eventdate` Date, `company` String, `deliveryno` String, `usercardtype` String, `id` String, `name` String, `mob` String, `orgcode` String, `creditcode` String, `taxregno` String, `type` String, `cardid` String, `staffna` String, `staffmob` String, `staffaddress` String, `checkdate` String, `method` String, `address` String, `utcdate` DateTime DEFAULT now()) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test', '{replica}', eventdate, (eventdate, company, deliveryno, id, mob, name), 8192)
在一个节点创建分布表:
CREATE TABLE default.test_all (`eventdate` Date, `company` String, `deliveryno` String, `usercardtype` String, `id` String, `name` String, `mob` String, `orgcode` String, `creditcode` String, `taxregno` String, `type` String, `cardid` String, `staffna` String, `staffmob` String, `staffaddress` String, `checkdate` String, `method` String, `address` String, `utcdate` DateTime DEFAULT now()) ENGINE = Distributed('{cluster}', 'default', 'test', rand())
5、插入表
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-05','ff','vv','xx');
insert into test_all(eventdate,company,deliveryno,id) VALUES('2020-12-06','xx','vv','xx');
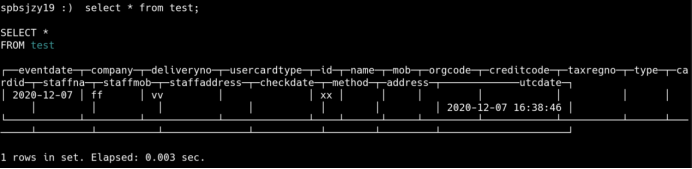
6、数据分布测试
(1)三张复制表分别执行
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-07','ff','vv','xx');
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-08','ff','vv','xx');
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-09','ff','vv','xx');
查询复制表:
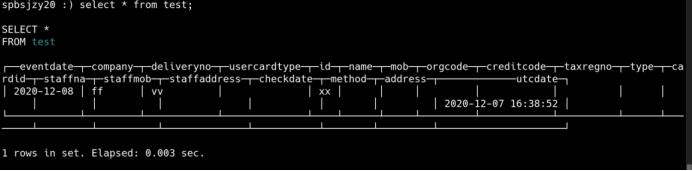
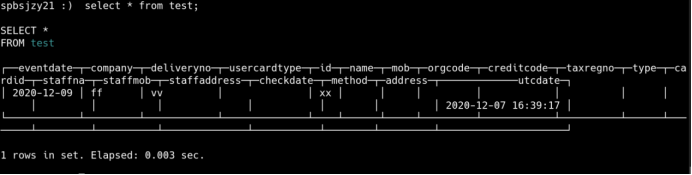
查询分布表
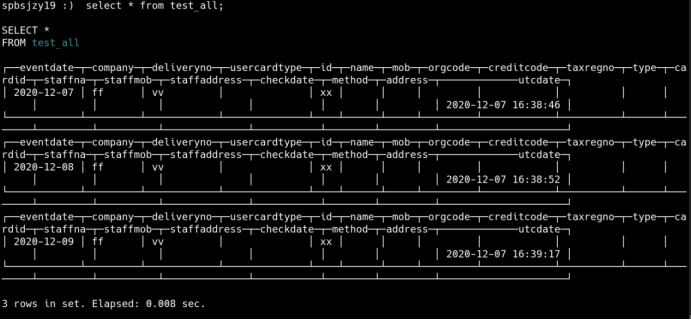
(2)插入分布表(随机分布)
insert into test_all(eventdate,company,deliveryno,id) VALUES('2020-12-07','xx','vv','xx');
insert into test_all(eventdate,company,deliveryno,id) VALUES('2020-12-08','xx','vv','xx');
查询复制表
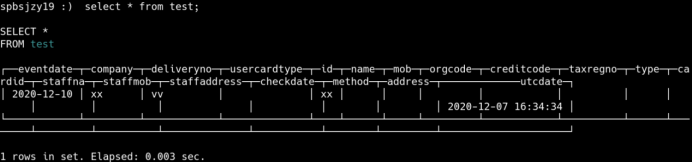
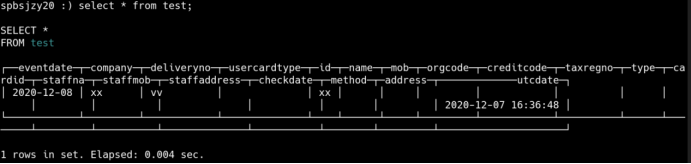
查询分布表
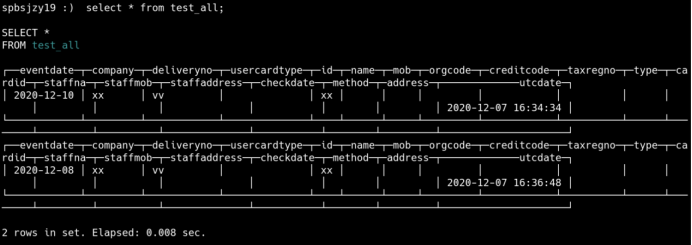
7、节点宕机测试
ClickHouse安装使用(单机、集群、高可用)的更多相关文章
- openstack pike 集群高可用 安装 部署 目录汇总
# openstack pike 集群高可用 安装部署#安装环境 centos 7 史上最详细的openstack pike版 部署文档欢迎经验分享,欢迎笔记分享欢迎留言,或加QQ群663105353 ...
- Rabbitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- 浅谈MySQL集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- bitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- mysql集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- Eureka 集群高可用配置.
SERVER:1 server: port: 1111 eureka: instance: hostname: ${spring.cloud.client.ip-address} instance-i ...
- 集群高可用之lvs+keepalive
集群高可用之lvs+keepalive keepalive简介: 负载均衡架构依赖于知名的IPVS内核模块,keepalive由一组检查器根据服务器的健康情况动态维护和管理服务器池.keepalive ...
- RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
随机推荐
- A Simple Framework for Contrastive Learning of Visual Representations 阅读笔记
Motivation 作者们构建了一种用于视觉表示的对比学习简单框架 SimCLR,它不仅优于此前的所有工作,也优于最新的对比自监督学习算法, 而且结构更加简单:这个结构既不需要专门的架构,也不需 ...
- JWT-配置与使用
1.jwt的安装配置 . 1.1安装JWT pip install djangorestframework-jwt==1.11.0 1.2 settings.py配置jwt载荷中的有效期设置 # jw ...
- Java经典小游戏——贪吃蛇简单实现(附源码)
一.使用知识 Jframe GUI 双向链表 线程 二.使用工具 IntelliJ IDEA jdk 1.8 三.开发过程 3.1素材准备 首先在开发之前应该准备一些素材,已备用,我主要找了一个图片以 ...
- MobaXterm无法退格删除
MobaXterm退格删除出现^H,总是要取消输入重新敲语句,很麻烦 解决方法:打开MobaXterm-->settings-->Configuration,把"Backspac ...
- pyhon 自动化 logger
#!/Users/windows8.1/PycharmProjects/pythonapi# @Software: PyCharm Community Edition# -*- coding: utf ...
- 实验4 汇编应用编程和c语言程序反汇编分析
1. 实验任务1 教材「实验9 根据材料编程」(P187-189)编程:在屏幕中间分别显示绿色.绿底红色.白底蓝色的字符串'welcome to masm!'. 解题思路:根据学习的知识,我知道该页在 ...
- [BUUCTF] 真的很杂
这似乎是一道安卓逆向题??我就是没有搞懂安卓逆向原来是misc吗... 安卓逆向一个例子 工具准备 1.apktool--可以反编译软件的布局文件.图片等资源,方便大家学习一些很好的布局: 2.dex ...
- python k-means聚类实例
port sys reload(sys) sys.setdefaultencoding('utf-8') import matplotlib.pyplot as plt import numpy as ...
- 简单的冒泡排序算法(java)
package lianxi; public class BubbleSort { public static void main(String[] args) { int[] array = {12 ...
- winform判断程序是否运行,且只能运行一个实例
前言 判断程序是否已经运行,使程序只能运行一个实例有很多方法,下面记录两种. 目前使用的是第一种方法. 方法1:线程互斥 static class Program { private static S ...