crawlergo动态爬虫去除Spidername使用
本来是想用AWVS的爬虫来联动Xray的,但是需要主机安装AWVS,再进行规则联动,只是使用其中的目标爬虫功能感觉就太重了,在github上面找到了由360 0Kee-Team团队从360天相中分离出来的动态爬虫模块crawlergo,尝试进行自定义代码联动
基础使用
下载最新的releases版本,到其目录下使用:
在PowerShell里面运行
./crawlergo -c "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" -t 10 http://testphp.vulnweb.com/

但是很明显可以看到在爬虫的请求头里面存在:

Spider-Name:crawlergo字段
crawlergo团队也说明了这个问题:
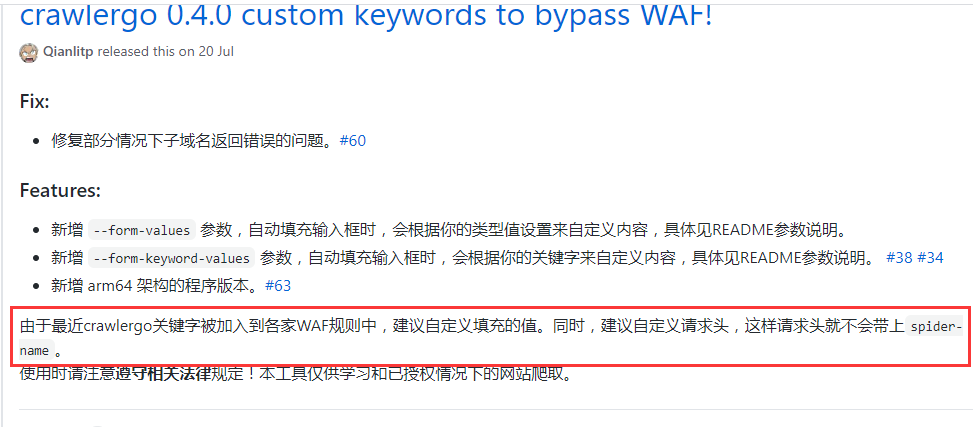
也有issue提到了这一点

所以我们先解决关键字被WAF拦截的问题,使用自定义请求头进行crawlergo页面爬取。
使用fake_useragent伪造请求头:
from fake_useragent import UserAgent
ua = UserAgent()
def GetHeaders():
headers = {'User-Agent': ua.random}
return headers
在爬取的时候指定请求头为随机生成的,即:
"--custom-headers",json.dumps(GetHeaders())
然后根据crawlergo团队给出的系统调用部分代码进行修改
原代码如下(我已将谷歌浏览器路径改为自己本地的了):
#!/usr/bin/python3
# coding: utf-8
import simplejson
import subprocess
def main():
target = "http://testphp.vulnweb.com/"
cmd = ["./crawlergo", "-c", "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe", "-o", "json", target]
rsp = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, error = rsp.communicate()
# "--[Mission Complete]--" 是任务结束的分隔字符串
result = simplejson.loads(output.decode().split("--[Mission Complete]--")[1])
req_list = result["req_list"]
print(req_list[0])
if __name__ == '__main__':
main()
该代码默认打印当前域名请求
运行结果如图:

将关键部分代码:
cmd = ["./crawlergo", "-c", "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe", "-o", "json", target]
根据项目参数:
--custom-headers Headers自定义HTTP头,使用传入json序列化之后的数据,这个是全局定义,将被用于所有请求
修改为:
cmd = ["./crawlergo", "-c", "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe", "--custom-headers",json.dumps(GetHeaders()),"-t","10","-o", "json", target]
GetHeaders()函数上面已经给出,运行结果为:

可以看到Spider-Name:crawlergo字段已经没有了。
对于返回结果的处理
当设置输出模式为 json时,返回的结果反序列化之后包含四个部分:
all_req_list: 本次爬取任务过程中发现的所有请求,包含其他域名的任何资源类型。req_list:本次爬取任务的同域名结果,经过伪静态去重,不包含静态资源链接。理论上是all_req_list的子集all_domain_list:发现的所有域名列表。sub_domain_list:发现的任务目标的子域名列表。
我们想要获取的是任务的同域名结果,所以输出:
result = simplejson.loads(output.decode().split("--[Mission Complete]--")[1])
# print(result)
req_list = result["req_list"]
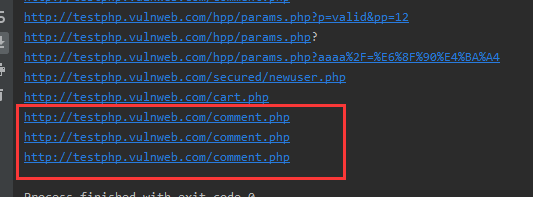
for url in req_list:
print(url['url'])

可以看到去重不算太完美
最后为了方便配置可以写一个config.py,用来放置chorme的路径,增加扫描系统的通用性,将结果存储到txt或者队列里面去。
crawlergo动态爬虫去除Spidername使用的更多相关文章
- 数字crawlergo动态爬虫结合长亭XRAY被动扫描
群里师傅分享了个挖洞的视频,搜了一下,大概就是基于这篇文章录的 https://xz.aliyun.com/t/7047 (小声哔哔一下,不得不说,阿里云先知社区和360酒仙桥六号部队公众号这两个地方 ...
- QQ空间动态爬虫
作者:虚静 链接:https://zhuanlan.zhihu.com/p/24656161 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 先说明几件事: 题目的意 ...
- scrapy + selenium 的动态爬虫
动态爬虫 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会 ...
- scala 爬虫 去除不能存储的特殊字符
scala 爬虫 去除不能存储的特殊字符 /** * 去除不能存储的特殊字符 */ def zifuChange(str: String): String = { var bo = true var ...
- 动态爬虫——selenium2搭载phantomjs入门范例
这是我学习爬虫比较深入的一步了,大部分的网页抓取用urllib2都可以搞定,但是涉及到JavaScript的时候,urlopen就完全傻逼了,所以不得不用模拟浏览器,方法也有很多,此处我采用的是sel ...
- Python3网络爬虫之requests动态爬虫:拉钩网
操作环境: Windows10.Python3.6.Pycharm.谷歌浏览器目标网址: https://www.lagou.com/jobs/list_Python/p-city_0?px=defa ...
- Selenium+Chrome或Firefox的动态爬虫程序
新版本的Selenium不再支持PhantomJS了,请使用Chrome或Firefox的无头版本来替代.
- crawler: 爬虫的基本结构
目前我所知道的爬虫在获取页面信息上,分为静态爬虫和动态爬虫:静态爬虫主要用于获取静态页面,获取速度一般也比较快:但是现在很多网站的页面都是采用动态页面,当我们用爬虫去获取信息的时候,页面的信息可能还没 ...
- 【python爬虫】初识爬虫
一.爬虫的定义 爬虫定义:程序或者脚本——自动的爬取万维网的数据的程序或者脚本. 二.爬虫可以解决的问题 1.解决冷启动问题. 2.搜索引擎的根基——通用爬虫. 3.帮助机器学习建立知识图谱. 4.制 ...
随机推荐
- Spider--补充--jsonpath的使用
# 知识点参见:https://blog.csdn.net/muzico425/article/details/102763176 # 示例:爬取示例网站的首页的评论: # 解析得到的字符串r.tex ...
- 小谢第58问:nuxt搭建企业官网
最近公司要重构公司官网,jq+bootstrap 改为了vue,刚开始我以为用vue不是挺好的嘛,后来才发现,有于vue单页面的特性,不利于搜索引擎的抓取,因此在seo方面需要另外想办法,于是乎,就找 ...
- TCP中RTT的测量和RTO的计算 以及 接收缓存大小的动态调整
RTT测量 在发送端有两种RTT的测量方法,但是因为TCP流控制是在接收端进行的,所以接收端也需要 有测量RTT的方法. /* Receiver "autotuning" code ...
- 1、线性DP 213. 打家劫舍 II
https://leetcode-cn.com/problems/house-robber-ii/ //rob 0, not rob n-1 || not rob 0,not rob n-1 ==&g ...
- c++中的几种函数调用约定(转)
C++中的函数调用约定(调用惯例)主要针对三个问题: 1.参数传递的方式(是否采用寄存器传递参数.采用哪个寄存器传递参数.参数压桟的顺序等): 参数的传递方式,最常见的是通过栈传递.函数的调用方将参数 ...
- RestPack Java实现Html转PDF文件
最近公司需要将前端一个图表统计导出为pdf.前端导出显示的pdf还是可以的,但是将会导致页面不可用与卡死状态.所以由后端寻找解决方案. 以下为解决方案调研 https://www.cnblogs.co ...
- 使用XSL解析XML输出HTML(XSL学习笔记一)
最近项目用到 XSL + XML,XML大家应该很熟悉,XSL暂且不解释,先看效果,如果想学习XSL的内容,可以先访问: https://www.w3school.com.cn/xsl/xsl_lan ...
- JavaScript正则学习笔记
RegExp 元字符 ' . ' 点号:匹配任意的字符 ^ $ 位置字符 ^ 匹配字符串开始的位置 $ 匹配字符串结束的位置 匹配数字和非数字 \d 和 \D 匹配空白字符 \s 和 \S \s 匹配 ...
- Camtasia如何给视频添加测试题
Camtasia是一款专门录制屏幕动作的工具,除此之外,它还具有即时播放和编 辑压缩的功能,可对视频片段进行剪接.添加转场效果.给视频添加测试题自然也不在话下了. 今天笔者就向大家展示一下如何使用Ca ...
- Python学习系列之列表(十一)
一.为什么需要列表 变量可以存储一个元素,而列表是一个"大容器"可以存储N多个元素,程序可以方便地对这些数据进行整体操作 列表相当于其它语言中的数组 二.列表的创建1.列表需要使用 ...