当你在浏览器输入一个网址(如http://www.taobao.com),按回车之后发生了什么?
首先你输入了一个网址并按下了回车,这个时候浏览器会根据这个URL去查找其对应的IP,具体过程如下:
首先是查找浏览器缓存,浏览器会保存一段时间你之前访问过的一些网址的DNS信息,不同浏览器保存的时常不等。
如果没有找到对应的记录,这个时候浏览器会尝试调用系统缓存来继续查找这个网址的对应DNS信息。
如果还是没找到对应的IP,那么接着会发送一个请求到路由器上,然后路由器在自己的路由器缓存上查找记录,路由器一般也存有DNS信息。
如果还是没有,这个请求就会被发送到ISP(注:Internet Service Provider,互联网服务提供商,就是那些拉网线到你家里的运营商,中国电信中国移动什么的),ISP也会有相应的ISP DNS服务器,一听中国电信就知道这个DNS服务器的规模肯定不会小,所以基本上都能在这里找得到。题外话:会跑到这里进行查询是因为你没有改动过"网络中心"的"ipv4"的DNS地址,万恶的电信联通可以改动了这个DNS服务器,换句话说他们可以让你的浏览器跳转到他们设定的页面上,这也就是人尽皆知的DNS和HTTP劫持,ISP们还美名曰“免费推送服务”。强烈鄙视这种霸王行为。我们也可以自行修改DNS服务器来防止DNS被ISP污染。
如果还是没有的话, 你的ISP的DNS服务器会将请求发向根域名服务器进行搜索。根域名服务器就是面向全球的顶级DNS服务器,共有13台逻辑上的服务器,从A到M命名,真正的实体服务器则有几百台,分布于全球各大洲。所以这些服务器有真正完整的DNS数据库。如果到了这里还是找不到域名的对应信息,那只能说明一个问题:这个域名本来就不存在,它没有在网上正式注册过。或者卖域名的把它回收掉了(通常是因为欠费)。 这也就是为什么打开一个新页面会有点慢,因为本地没什么缓存,要这样递归地查询下去。
多说一句,例如"mp3.baidu.com",域名先是解析出这是个.com的域名,然后跑到管理.com域名的服务器上进行进一步查询,然后是.baidu,最后是mp3, 所以域名结构为:三级域名.二级域名.一级域名。
浏览器终于得到了IP以后,浏览器接着给这个IP的服务器发送了一个http请求,方式为get,例如访问nbut.cn。
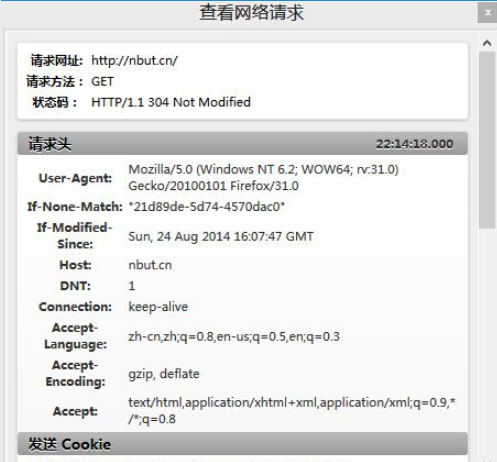
这个get请求包含了主机(host)、用户代理(User-Agent),用户代理就是自己的浏览器,它是你的"代理人",Connection(连接属性)中的keep-alive表示浏览器告诉对方服务器在传输完现在请求的内容后不要断开连接,不断开的话下次继续连接速度就很快了。其他的顾名思义就行了。还有一个重点是Cookies,Cookies保存了用户的登陆信息,在每次向服务器发送请求的时候会重复发送给服务器。Corome上的F12与Firefox上的firebug(快捷键shift+F5)均可查看这些信息。
发送完请求接下来就是等待回应了,如下图:
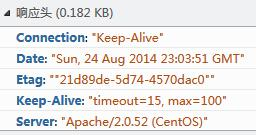
当然了,服务器收到浏览器的请求以后(其实是WEB服务器接收到了这个请求,WEB服务器有iis、apache等),它会解析这个请求(读请求头),然后生成一个响应头和具体响应内容。接着服务器会传回来一个响应头和一个响应,响应头告诉了浏览器一些必要的信息,例如重要的Status Code,2开头如200表示一切正常,3开头表示重定向,4开头,如404,呵呵。响应就是具体的页面编码,就是那个......,浏览器先读了关于这个响应的说明书(响应头),然后开始解析这个响应并在页面上显示出来。在下一次CF的时候(不是穿越火线,是http://codeforces.com/),由于经常难以承受几千人的同时访问,所以CF页面经常会出现崩溃页面,到时候可以点开火狐的firebug或是Chrome的F12看看状态,不过这时候一般都急着看题和提交代码,似乎根本就没心情理会这个状态吧-.-。
如果是个静态页面,那么基本上到这一步就没了,但是如今的网站几乎没有静态的了吧,基本全是动态的。所以这时候事情还没完,根据我们的经验,浏览器打开一个网址的时候会慢慢加载这个页面,一部分一部分的显示,直到完全显示,最后标签栏上的圈圈就不转了。这是因为,主页(index)页面框架传送过来以后,浏览器还要继续向服务器发送请求,请求的内容是主页里面包含的一些资源,如图片,视频,css样式等等。这些"非静态"的东西要一点点地请求过来,所以标签栏转啊转,内容刷啊刷,最后全部请求并加载好了就终于好了。

需要说明的是,对于静态的页面内容,浏览器通常会进行缓存,而对于动态的内容,浏览器通常不会进行缓存。缓存的内容通常也不会保存很久,因为难保网站不会被改动。
当你在浏览器输入一个网址(如http://www.taobao.com),按回车之后发生了什么?的更多相关文章
- 在浏览器中简单输入一个网址,解密其后发生的一切(http请求的详细过程)
在浏览器中简单输入一个网址,解密其后发生的一切(http请求的详细过程) 原文链接:http://www.360doc.com/content/14/1117/10/16948208_42571794 ...
- 我们在地址栏中输入一个网址,比如百度(www.baidu.com)后浏览器做了哪些事
在浏览器输入网址,Enter之后发生的事情: 1. 浏览器接收域名 2. 发送域名给DNS,中文名字是域名系统服务器,一般位于ISP(互联网服务提供商,比如我们熟知的联通.移动.电信等) 中.浏览器会 ...
- 浏览器输入一个url到整个页面显示出来经历了哪些过程?
https://cloud.tencent.com/developer/article/1396399 https://www.cnblogs.com/haonanZhang/p/6362233.ht ...
- 当你输入一个网址/点击一个链接,发生了什么?(以www.baidu.com为例)
>>>点击网址后,应用层的DNS协议会将网址解析为IP地址: DNS查找过程: 浏览器会检查缓存中有没有这个域名对应的解析过的IP地址,如果缓存中有,这个解析过程就将结束. 如果用户 ...
- 浏览器输入一个url的过程,以及加载完html文件和js文件的标志
简单理解: 当在浏览器地址栏输入一url时,浏览器会做以下几个步骤: 1.将url转化为ip地址,也就是DNS解析,(先找本地host文件中是否有对应的ip地址,如果有就直接用,没有的话,就按域名的二 ...
- 笔试常考--浏览器输入一个URL点击回车之后发生了什么
解析URL:浏览器首先对拿到的URL进行识别,抽取出域名字段. DNS解析: 查询浏览器缓存(浏览器会缓存之前拿到的DNS 2-30分钟时间),如果没有找到, 检查系统缓存,检查hosts文件,这个文 ...
- 2020-07-02:在浏览器输入一个url后按回车,会发生什么?
福哥答案2020-07-02: 简单回答: 域名解析. 建立TCP连接. 请求. 处理. 响应. 释放TCP连接. 页面渲染. 中级回答: 域名解析 浏览器DNS缓存. 操作系统DNS缓存. 路由器缓 ...
- 当在浏览器输入一个url访问后发生了什么
首先根据DNS获取该url的ip地址,ip地址的获取可能通过本地缓存,路由缓存等得到. 然后在网络层通过路由选择查找一条可达路径,最后利用tcp/ip协议来进行数据的传输. 其中在传输层将信息添加源端 ...
- 当你在浏览器地址栏输入一个URL后回车,将会发生的事情?
原文:http://igoro.com/archive/what-really-happens-when-you-navigate-to-a-url/ 作为一个软件开发者,你一定会对网络应用如何工作有 ...
随机推荐
- ERP中HR模块的操作与设计--开源软件诞生26
赤龙ERP的EHR功能讲解--第26篇 用日志记录"开源软件"的诞生 [进入地址 点亮星星]----祈盼着一个鼓励 博主开源地址: 码云:https://gitee.com/red ...
- php post请求https
<?php $url = 'https://www.xxx.com'; $curl = curl_init(); curl_setopt($curl, CURLOPT_URL, $url); c ...
- [MIT6.006] 1. Algorithmic Thinking, Peak Finding 算法思维,峰值寻找
[MIT6.006] 系列笔记将记录我观看<MIT6.006 Introduction to Algorithms, Fall 2011>的课程内容和一些自己补充扩展的知识点.该课程主要介 ...
- nice-ni 耗光cpu
可以看到 低优先级的进程 暂用了比较高的CPU时间. top 命令中可以看到 NI 为19, 其优先级最低 但是使用cpu 最高. 说明这个进程需要经行优化了, 通过gdb 发现此进程一直都在处理报文 ...
- (3)ElasticSearch在linux环境中安装与配置head插件
1.简介 ElasticSearch-Head跟Kibana一样也是一个针对ElasticSearch集群操作的API的可视化管理工具,它提供了集群管理.数据可视化.增删改查.查询语句等功能,最重要还 ...
- Python_爬虫伪装_ scrapy中fake_userAgent的使用
scrapy 伪装代理和fake_userAgent的使用 伪装浏览器代理 在爬取网页是有些服务器对请求过滤的不是很高可以不用ip来伪装请求直接将自己的浏览器信息给伪装也是可以的. 第一种方法: 1. ...
- 网络发布工具 Apache/Nginx
四大主流发布服务器 注:发布服务器的背后都是socket套接字 1.Apache阿帕奇 - 多进程 2.IIS -多线程 3.Nginx (engine x)(新) -支持异步IO,是现在最快的发布服 ...
- spring-boot-starter-parent和spring-boot-dependencies
如何创建一个SpringBoot项目,SpringBoot的依赖引入都是基于starter的,通常创建一个SpringBoot项目都是通过继承关系指定pom文件中的parent. <parent ...
- 分布式监控系统之Zabbix网络发现
前文我们了解了zabbix的宏,自定义item和模板的相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/14013331.html:今天我们来了解下zab ...
- 「LOJ 541」「LibreOJ NOIP Round #1」七曜圣贤
description 题面很长,这里给出题目链接 solution 用队列维护扔掉的红茶,同时若后扔出的红茶比先扔出的红茶编号更小,那么先扔出的红茶不可能成为答案,所以可以用单调队列维护 故每次询问 ...