结巴(jieba)分词
一.介绍:
jieba:
“结巴”中文分词:做最好的 Python 中文分词组件
“Jieba” (Chinese for “to stutter”) Chinese text segmentation: built to be the best Python Chinese word segmentation module.
完整文档见 :
GitHub: https://github.com/fxsjy/jieba
特点
- 支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
- MIT 授权协议
在线演示: http://jiebademo.ap01.aws.af.cm/
安装说明
代码对 Python 2/3 均兼容
- 全自动安装: easy_install jieba 或者 pip install jieba / pip3 install jieba
- 半自动安装:先下载 https://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
- 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
- 通过 import jieba 来引用
二.功能介绍及例子
1.分词主要功能:
先介绍主要的使用功能,再展示代码输出。jieba分词的主要功能有如下几种:
1. jieba.cut:该方法接受三个输入参数:需要分词的字符串; cut_all 参数用来控制是否采用全模式;HMM参数用来控制是否适用HMM模型
2. jieba.cut_for_search:该方法接受两个参数:需要分词的字符串;是否使用HMM模型,该方法适用于搜索引擎构建倒排索引的分词,粒度比较细。
3. 待分词的字符串可以是unicode或者UTF-8字符串,GBK字符串。注意不建议直接输入GBK字符串,可能无法预料的误解码成UTF-8,
4. jieba.cut 以及jieba.cut_for_search返回的结构都是可以得到的generator(生成器), 可以使用for循环来获取分词后得到的每一个词语或者使用
5. jieb.lcut 以及 jieba.lcut_for_search 直接返回list
6. jieba.Tokenizer(dictionary=DEFUALT_DICT) 新建自定义分词器,可用于同时使用不同字典,jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
2.简单模式:
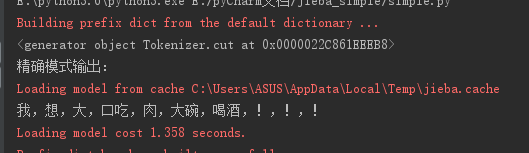
2.1.精确模式(返回结果是一个生成器,对大量数据分词很重要,占内存小):
import jieba s = '我想大口吃肉大碗喝酒!!!'
cut=jieba.cut(s)
print(cut)
#精确模式
print('精确模式输出:')
print(','.join(cut))
输出为:
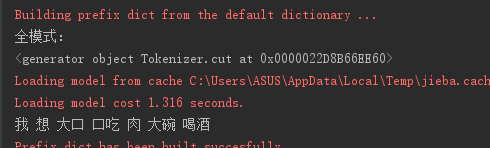
2.2.全模式(返回结果也是生成器,特点是把文本分成尽可能多的词):
import jieba s = '我想大口吃肉大碗喝酒!!!'
print('全模式:')
result=jieba.cut(s, cut_all=True)
print(result)
print(' '.join(result))
输出为:
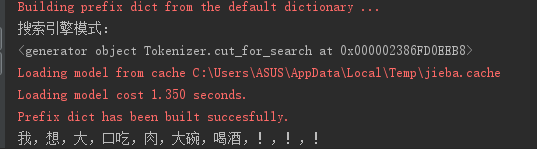
2.3.搜索引擎模式:
import jieba s = '我想大口吃肉大碗喝酒!!!'
print('搜索引擎模式:')
result=jieba.cut_for_search(s)
print(result)
print(','.join(result))
输出为:
3.获取词性:每个词都有其词性,比如名词、动词、代词等,结巴分词的结果也可以带上每个词的词性,要用到jieba.posseg
分词及输出词性:
import jieba.posseg as psg s = '我想大口吃肉大碗喝酒!!!'
print('分词及词性:')
result=psg.cut(s)
print(result)
print([(x.word,x.flag) for x in result])

过滤词性,如获取名词:
import jieba.posseg as psg s = '我想大口吃肉大碗喝酒!!!'
print('分词及词性:')
result=psg.cut(s)
print(result)
#筛选为名词的
print([(x.word,x.flag) for x in result if x.flag=='n'])
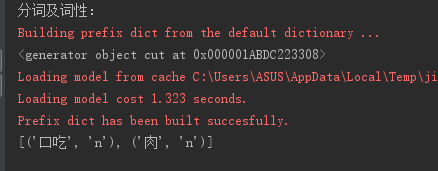
4.并行分词:在文本数据量非常大的时候,为了提高分词效率,开启并行分词就很有必要了。jieba支持并行分词,基于python自带的multiprocessing模块,但要注意的是在Windows环境下不支持。
# 开启并行分词模式,参数为并发执行的进程数
jieba.enable_parallel(5) # 关闭并行分词模式
jieba.disable_parallel()

5.获取出现频率Top n的词(有些词无实际意义,可筛选):
from collections import Counter
words_total=open('',encoding='utf-8').read()
c = Counter(words_total).most_common(20)
print (c)

6.使用用户字典提高分词准确性:
jieba分词器还有一个方便的地方是开发者可以指定自己的自定义词典,以便包含词库中没有的词,虽然jieba分词有新词识别能力,但是自行添加新词可以保证更高的正确率。
使用命令:
jieba.load_userdict(filename) # filename为自定义词典的路径。在使用的时候,词典的格式和jieba分词器本身的分词器中的词典格式必须保持一致,一个词占一行,每一行分成三部分,一部分为词语,一部分为词频,最后为词性(可以省略),用空格隔开。

7.关键词抽取:
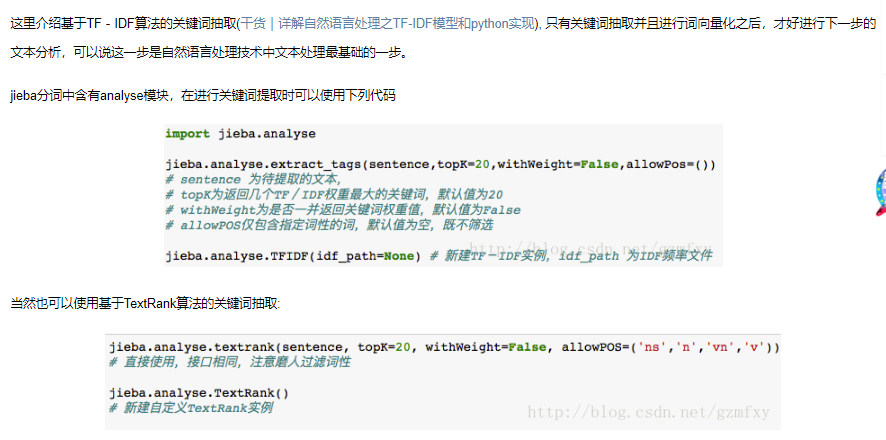
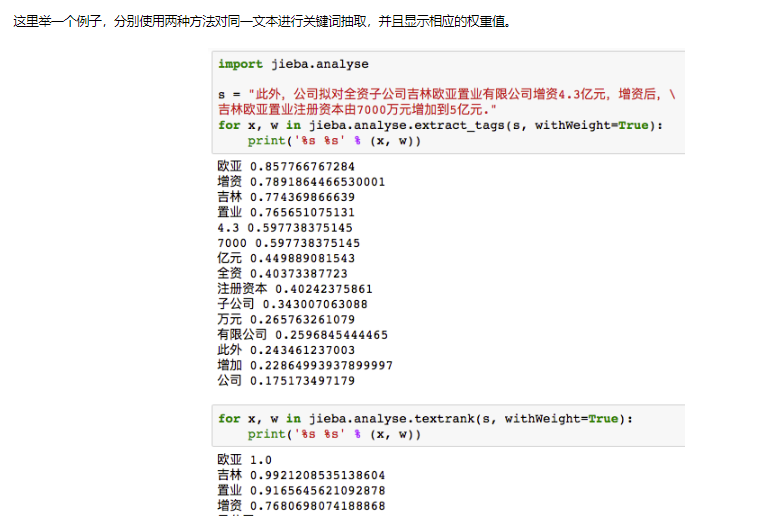
附:结巴分词词性对照表(按词性英文首字母排序)
形容词(1个一类,4个二类)
a 形容词
ad 副形词
an 名形词
ag 形容词性语素
al 形容词性惯用语
区别词(1个一类,2个二类)
b 区别词
bl 区别词性惯用语
连词(1个一类,1个二类)
c 连词
cc 并列连词
副词(1个一类)
d 副词
叹词(1个一类)
e 叹词
方位词(1个一类)
f 方位词
前缀(1个一类)
h 前缀
后缀(1个一类)
k 后缀
数词(1个一类,1个二类)
m 数词
mq 数量词
名词 (1个一类,7个二类,5个三类)
名词分为以下子类:
n 名词
nr 人名
nr1 汉语姓氏
nr2 汉语名字
nrj 日语人名
nrf 音译人名
ns 地名
nsf 音译地名
nt 机构团体名
nz 其它专名
nl 名词性惯用语
ng 名词性语素
拟声词(1个一类)
o 拟声词
介词(1个一类,2个二类)
p 介词
pba 介词“把”
pbei 介词“被”
量词(1个一类,2个二类)
q 量词
qv 动量词
qt 时量词
代词(1个一类,4个二类,6个三类)
r 代词
rr 人称代词
rz 指示代词
rzt 时间指示代词
rzs 处所指示代词
rzv 谓词性指示代词
ry 疑问代词
ryt 时间疑问代词
rys 处所疑问代词
ryv 谓词性疑问代词
rg 代词性语素
处所词(1个一类)
s 处所词
时间词(1个一类,1个二类)
t 时间词
tg 时间词性语素
助词(1个一类,15个二类)
u 助词
uzhe 着
ule 了 喽
uguo 过
ude1 的 底
ude2 地
ude3 得
usuo 所
udeng 等 等等 云云
uyy 一样 一般 似的 般
udh 的话
uls 来讲 来说 而言 说来
uzhi 之
ulian 连 (“连小学生都会”)
动词(1个一类,9个二类)
v 动词
vd 副动词
vn 名动词
vshi 动词“是”
vyou 动词“有”
vf 趋向动词
vx 形式动词
vi 不及物动词(内动词)
vl 动词性惯用语
vg 动词性语素
标点符号(1个一类,16个二类)
w 标点符号
wkz 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { <
wky 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { >
wyz 左引号,全角:“ ‘ 『
wyy 右引号,全角:” ’ 』
wj 句号,全角:。
ww 问号,全角:? 半角:?
wt 叹号,全角:! 半角:!
wd 逗号,全角:, 半角:,
wf 分号,全角:; 半角: ;
wn 顿号,全角:、
wm 冒号,全角:: 半角: :
ws 省略号,全角:…… …
wp 破折号,全角:—— -- ——- 半角:--- ----
wb 百分号千分号,全角:% ‰ 半角:%
wh 单位符号,全角:¥ $ £ ° ℃ 半角:$
字符串(1个一类,2个二类)
x 字符串
xx 非语素字
xu 网址URL
语气词(1个一类)
y 语气词(delete yg)
状态词(1个一类)
z 状态词
参考:https://pypi.org/project/jieba/#history
https://www.cnblogs.com/jiayongji/p/7119065.html
https://blog.csdn.net/gzmfxy/article/details/78994396
结巴(jieba)分词的更多相关文章
- python结巴(jieba)分词
python结巴(jieba)分词 一.特点 1.支持三种分词模式: (1)精确模式:试图将句子最精确的切开,适合文本分析. (2)全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解 ...
- 自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396) 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自 ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
- 【原】关于使用jieba分词+PyInstaller进行打包时出现的一些问题的解决方法
错误现象: 最近在做一个小项目,在Python中使用了jieba分词,感觉非常简洁方便.在Python端进行调试的时候没有任何问题,使用PyInstaller打包成exe文件后,就会报错: 错误原因分 ...
- Lucene.net(4.8.0) 学习问题记录五: JIEba分词和Lucene的结合,以及对分词器的思考
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- jieba分词(2)
结巴分词系统中实现了两种关键词抽取法,一种是TF-IDF关键词抽取算法另一种是TextRank关键词抽取算法,它们都是无监督的算法. 以下是两种算法的使用: #-*- coding:utf-8 -*- ...
- jieba分词(1)
近几天在做自然语言处理,看了一篇论文:面向知识库的中文自然语言问句的语义理解,里面提到了中文的分词,大家都知道对于英文的分词,NLTK有很好的支持,但是NLTK对于中文的分词并不是很好(其实也没有怎么 ...
- Python自然语言处理学习——jieba分词
jieba——“结巴”中文分词是sunjunyi开发的一款Python中文分词组件,可以在Github上查看jieba项目. 要使用jieba中文分词,首先需要安装jieba中文分词,作者给出了如下的 ...
- $好玩的分词——python jieba分词模块的基本用法
jieba(结巴)是一个强大的分词库,完美支持中文分词,本文对其基本用法做一个简要总结. 安装jieba pip install jieba 简单用法 结巴分词分为三种模式:精确模式(默认).全模式和 ...
- jieba分词初学
昨天,做的那个数据分析报告用到了jieba分词.但是只是借用了别人的部分代码.具体函数代表什么还不太明白.今天去官网研究了下..... jieba官网简介 "结巴"中文分词:做最好 ...
随机推荐
- 试验一下Golang 网络爬虫框架gocolly/colly
参考:http://www.cnblogs.com/majianguo/p/8186429.html 框架源码在 github.com/gocolly/colly 代码如下(github源码中的dem ...
- javascript中数组化的一般见解
javascript中数组化的一般见解,数组化浏览器中存在许多类数组对象,往往对类数组操作比较麻烦,没有数组那些非常方便的方法,在这种情况下,就有了数组化方法. 数组化的一般方法 1.第一种也是我们最 ...
- rabbitmq的五种工作模式
abbitmq的五种工作模式
- (四)surging 微服务框架使用系列之网关 转载
一.什么是API网关 API网关是一个服务器,是系统对外的唯一入口.API网关封装了系统内部架构,为每个客户端提供一个定制的API.API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入 ...
- leetcode 74. Search a 2D Matrix 、240. Search a 2D Matrix II
74. Search a 2D Matrix 整个二维数组是有序排列的,可以把这个想象成一个有序的一维数组,然后用二分找中间值就好了. 这个时候需要将全部的长度转换为相应的坐标,/col获得x坐标,% ...
- 初学Python——介绍一些内置方法
1.abs()求绝对值 a=abs(-10) print(a) # 输出:10 2.all() 用来检测列表元素是否全部为空.0.False print(all([0,5,4])) #当列表所有元素都 ...
- Luogu P3378 【模板】堆
((^ 0.0 ^) )~ 堆是一个完全二叉树,对于小根堆,所有父节点<=子节点,下标就和线段树是一样的 在STL里就是优先队列 只有堆顶元素可以操作(询问或弹出). 加入新元素时x,he ...
- Linux kprobe调试技术使用
kprobe调试技术是为了便于跟踪内核函数执行状态所设计的一种轻量级内核调试技术. 利用kprobe技术,可以在内核绝大多数函数中动态插入探测点,收集调试状态所需信息而基本不影响原有执行流程. kpr ...
- 生产者消费者 ProducerConsumer
生产者消费者是常见的同步问题.一个队列,头部生产数据,尾部消费数据,队列的长度为固定值.当生产的速度大于消费的速度时,队列逐渐会填满,这时就会阻塞住.当尾部消费了数据之后,生产者就可以继续生产了. 生 ...
- SpringBoot整合Shiro使用Ehcache等缓存无效问题
前言 整合有缓存.事务的spring boot项目一切正常. 在该项目上整合shiro安全框架,发现部分类的缓存Cache不能正常使用. 然后发现该类的注解基本失效,包括事务Transaction注解 ...