Python实现百度贴吧自动顶贴机
开发这款小工具,我们需要做一些准备:
- url.txt:多个需要顶起的帖子地址。
- reply:多条随机回复的内容。
- selenium:浏览器自动化测试框架
首先,我们先使用pip完成selenium的安装。
示例代码:
pip install -U selenium接下来,我们添加对浏览器的支持,这里使用火狐浏览器。
对应Windows环境下的火狐浏览器,我们需要下载一个小程序:geckodriver.exe
下载地址:http://download.csdn.net/download/xingbb99/10245371
把下载下来的压缩包解压缩,将exe文件直接放在项目文件夹中。
这里需要注意,如果火狐浏览器不是默认安装的话,需要将浏览器的安装路径添加到系统环境变量的Path中。
完成以上准备,我们就可以进行编程了。
一、导入必需的模块
示例代码:
'''
想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
from selenium import webdriver # 导入网页内驱动模块
from selenium.webdriver.common.keys import Keys # 导入按键类
from selenium.webdriver.common.action_chains import ActionChains # 导入动作类
from random import choice
from time import sleep
import re
二、创建浏览器测试对象
示例代码:
profile = webdriver.FirefoxProfile(r'C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\nczl01ld.default')
browser = webdriver.Firefox(profile, timeout=300) # 使用profile可以实现自动登录
三、定义将Cookie添加到测试对象的函数
Cookie的获取可以在火狐浏览器中打开贴吧地址后,按F12或右键菜单中选择【查看元素】,在打开的开发工具界面中,选择网络(NetWork),点开右侧收起的消息栏,点选【Cookie】复制其中的内容。
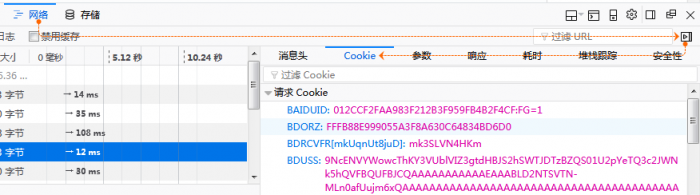

将Cookie内容存入变量,通过正则表达式获取字段并转换为字典后,添加到浏览器测试对象中。
示例代码:
def cookie():
cookies = '''
BAIDUID = 012CCF2FAA983F21333F959FB4B2F4CF:FG=1;
BDORZ = FFFB88E999055A3F86630C64834BD6D0;
BDUSS = 9NcENVYWowcThKY3VUblVIZ3g...太长了此处省略一部分...S01U2AAABvKe1obyntaaG;
BIDUPSID = 23A4C6D0C2851099D66FBFDBA99EDF3B;
FP_UID = 0d8be11adc641cb5501f1e68270d8bea;
H_PS_PSSID = 1457_21116_22072;
MCITY = -131:;
PSINO = 1;
PSTM = 1506587758;
'''
cookiesList = re.findall(r'([\S\s]*?)=([\S\s]*?);', cookies)
for cookie in cookiesList:
ck = {'name': cookie[0].strip(), 'value': cookie[1].strip()}
browser.add_cookie(ck) # 添加cookie到浏览器测试对象
四、定义随机获取评论内容的函数
示例代码:
def get_content():
file = open('reply.txt', encoding='utf-8').readlines() # 读取所有评论
return choice(file).strip() # 随机获取一行评论并返回
五、定义写入评论并提交的函数
示例代码: def reply():
content = get_content() # 获取评论内容
js = "document.getElementById('ueditor_replace').innerHTML='%s'" % content # 编写js脚本
browser.execute_script(js) # 执行js脚本
browser.find_element_by_css_selector('.poster_submit').click() # 点击发表按钮
六、定义主程序函数
def main():
count = 0
for url in open('url.txt', encoding='utf-8').readlines(): # 逐行读取url文件
count += 1
if count >= 5: # 从url文件中的第5个地址开始回复
browser.get(url) # 打开地址
sleep(10) # 避免回复过快,地址打开后等待10秒钟。
cookie() # 添加cookie
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") # 滚动到页面底部
reply() # 写入回复内容并提交
sleep(5) # 等待完成提交
ActionChains(browser).key_down(Keys.CONTROL).send_keys("w").key_up(Keys.CONTROL).perform() # 关闭网页
完成以上代码之后,我们运行主程序,就能够自动回复了。
注意:请申请小号进行测试,以免封号。
示例代码:
if __name__ == '__main__':
main()
完整代码
from selenium import webdriver # 导入网页内驱动模块
from selenium.webdriver.common.keys import Keys # 导入按键类
from selenium.webdriver.common.action_chains import ActionChains # 导入动作类
from random import choice
from time import sleep
import re
'''
想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
profile = webdriver.FirefoxProfile(r'C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\nczl01ld.default')
browser = webdriver.Firefox(profile, timeout=300) # 使用profile可以实现自动登录 def cookie():
cookies = '''
BAIDUID = 012CCF2FAA983F21333F959FB4B2F4CF:FG=1;
BDORZ = FFFB88E999055A3F86630C64834BD6D0;
BDUSS = 9NcENVYWowcThKY3VUblVIZ3g...太长了此处省略一部分...S01U2AAABvKe1obyntaaG;
BIDUPSID = 23A4C6D0C2851099D66FBFDBA99EDF3B;
FP_UID = 0d8be11adc641cb5501f1e68270d8bea;
H_PS_PSSID = 1457_21116_22072;
MCITY = -131:;
PSINO = 1;
PSTM = 1506587758;
'''
cookiesList = re.findall(r'([\S\s]*?)=([\S\s]*?);', cookies)
for cookie in cookiesList:
ck = {'name': cookie[0].strip(), 'value': cookie[1].strip()}
browser.add_cookie(ck) # 添加cookie到浏览器测试对象 def get_content():
file = open('reply.txt', encoding='utf-8').readlines() # 读取所有评论
return choice(file).strip() # 随机获取一行评论并返回 def reply():
content = get_content() # 获取评论内容
js = "document.getElementById('ueditor_replace').innerHTML='%s'" % content # 编写js脚本
browser.execute_script(js) # 执行js脚本
browser.find_element_by_css_selector('.poster_submit').click() # 点击发表按钮 def main():
count = 0
for url in open('url.txt', encoding='utf-8').readlines(): # 逐行读取url文件
count += 1
if count >= 5: # 从url文件中的第5个地址开始回复
browser.get(url) # 打开地址
sleep(10) # 避免回复过快,地址打开后等待10秒钟。
cookie() # 添加cookie
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") # 滚动到页面底部
reply() # 写入回复内容并提交
sleep(5) # 等待完成提交
ActionChains(browser).key_down(Keys.CONTROL).send_keys("w").key_up(Keys.CONTROL).perform() # 关闭网页 if __name__ == '__main__':
main()
Python实现百度贴吧自动顶贴机的更多相关文章
- Python 版百度站长平台链接主动推送脚本
如果自己的网站需要被百度收录,可以在搜索结果中找到,就需要将网站的链接提交给百度.依靠百度的爬虫可能无法检索到网站所有的内容,因此可以主动将链接提交给百度. 在百度的站长平台上介绍了链接提交方法,目前 ...
- Python获取百度浏览记录
Python模拟百度登录实例详解 http://www.jb51.net/article/78406.htm Python实战计划学习作业2-1 http://blog.csdn.net/python ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- 在Python命令行和VIM中自动补全
作者:gnuhpc 出处:http://www.cnblogs.com/gnuhpc/ 1. VIM下的配置: wget https://github.com/rkulla/pydiction/arc ...
- python版恶俗古风自动生成器.py
python版恶俗古风自动生成器.py """ python版恶俗古风自动生成器.py 模仿自: http://www.jianshu.com/p/f893291674c ...
- 百度移动搜索自动转码太坑爹,JS跳转地址会被抓取
这段时间碰到个很崩溃的问题,一个页面通过 script 加载请求服务端进行统计再输出js进行跳转,分为两个步骤分别统计, 打开页面通过script 请求远程服务器进行统计并输出要通过js使页面跳转的最 ...
- 解决网页在手机浏览器打开不停刷新的方案(百度的ua自动转向js问题)
一:发现问题 原有可能是网站内挂了一个百度的ua自动转向js,手机访问的话会被自动转到feiyujd.com,然后又被转到www点feiyujd点com,这样反复死循环.就形成了一直在刷新,网站一闪一 ...
- SEO -- WordPress怎设置百度站长链接自动提交
百度站长平站更新了主动推送(实时)推送的方式,受到了广大站长的好评,但是对于使用WordPress的网站来说怎么设置自动提交呢,在这里介绍一种比较简单且有效的方法.我们可以使用 WP BaiDu Su ...
- Python教程百度网盘哪里有?
Python为我们提供了非常完善的基础代码库,覆盖了网络.文件.GUI.数据库.文本等大量内容,被形象地称作"内置电池(batteries included)".带你快速入门的Py ...
随机推荐
- vue组件详解——使用slot分发内容
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 一.什么是slot 在使用组件时,我们常常要像这样组合它们: <app& ...
- Python:Day04
数学运算符: + 加 - 减 * 乘 ** 指数运算 / 除 // 整除 % 取余 比较运算符: > 大于 < 小于 >= 大于等于 <= 小于等于 == ...
- 为什么matlab激活完后还要激活(Matlab2012b license失效解决办法)
第一步:打开matlab安装路径中的license文件夹,删除其中的lic文件 第二步:更换新的license.lic文件 第三步:重新打开matlab 搞定! license.lic文件的内容是: ...
- sqlmap的简单使用
SQLmap基于Python编写,只要安装了Python的操作系统就可以使用它. 一.SQLMap判断是否存在注入 1. sqlmap -u "http://XXXXXXX?id=1&quo ...
- 【vue】vue-router路径无法正确跳转
具体描述:vue项目,npm run build时点击路由切换,第一次点击没问题,再点不会切换报错如下图 原因分析:vue-router配置路由,当代码分割和懒加载时,由于webpack配置不当,导致 ...
- PowerMock单元测试踩坑与总结
1.Mock是什么? 通过提供定制的类加载器以及一些字节码篡改技巧的应用,PowerMock 现了对静态方法.构造方法.私有方法以及 Final 方法的模拟支持,对静态初始化过程的移除等强大的功能. ...
- 企业IT架构转型之道,阿里巴巴中台战略思想与架构实战
前言: 晚上11点多闲来无事,打开QQ技术群,发现有关 '中心化与引擎化' 的话题,本着学习的心态向大佬咨询,大佬推荐一本书,我大概看了有四分之一的样子,对于我这种对架构迷茫的人来说,如鱼得水,于是特 ...
- Jmeter(三十五)_分布式
jmeter分布式简单步骤说明: 1:添加远程服务器IP到配置文件 在JMETER_HOME / bin / jmeter.properties中,找到名为“ remote_hosts ” 的属性,并 ...
- 程序员修仙之路- CXO让我做一个计算器!!
菜菜呀,个税最近改革了,我得重新计算你的工资呀,我需要个计算器,你开发一个吧 CEO,CTO,CFO于一身的CXO X总,咱不会买一个吗? 菜菜 那不得花钱吗,一块钱也是钱呀··这个计算器支持加减乘除 ...
- DOM操作 JS事件 节点增删改查
--------------------------习惯是社会的巨大的飞轮和最可贵的维护者.——威·詹姆斯 day 49 [value属性操作] <!DOCTYPE html><ht ...