zookeeper服务发现实战及原理--spring-cloud-zookeeper源码分析
1.为什么要服务发现?
服务实例的网络位置都是动态分配的。由于扩展、失败和升级,服务实例会经常动态改变,因此,客户端代码需要使用更加复杂的服务发现机制。
2.常见的服务发现开源组件
etcd—用于共享配置和服务发现的高可用性、分布式、一致的键值存储。使用etcd的两个著名项目是Kubernetes和Cloud Foundry。
consul-发现和配置服务的工具。它提供了一个API,允许客户端注册和发现服务。领事可以执行健康检查,以确定服务的可用性。
Apache Zookeeper——一个广泛使用的分布式应用高性能协调服务。Apache Zookeeper最初是Hadoop的子项目,但现在是顶级项目。
3.zookeeper服务发现原理
3.1 zookeeper是什么?
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
3.2 为什么zookeeper?
大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等)
目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
ZooKeeper:提供通用的分布式锁服务,用以协调分布式应用(如为HBase提供服务)
3.3 Zookeeper在微服务框架中可以实现服务发现,该服务发现机制可作为云服务的注册中心。
通过Spring Cloud Zookeeper为应用程序提供一种Spring Boot集成,将Zookeeper通过自动配置和绑定 的方式集成到Spring环境中.
4.准备工作
安装zookeeper和zooinspector见
此次安装的zookeeper版本为最新版
zookeeper-3.5.4-beta 安装过程一样
下载ZooInspector,参照指南运行java -Dfile.encoding=UTF-8 -jar zookeeper-dev-ZooInspector.jar即可
5.实战
5.1 使用sts创建一个spring starter project名称为zk-discovery,如下图所示
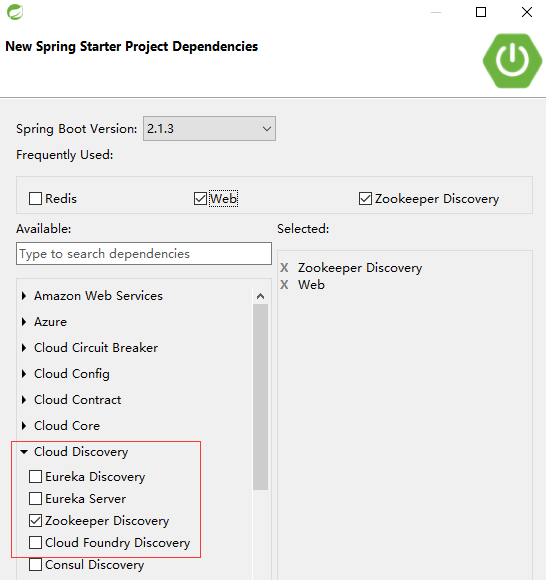
此时自动生成的pom.xml的配置文件如下所示
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>zk-discovery</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>zk-discovery</name>
<description>Demo project for Spring Boot</description> <properties>
<java.version>1.8</java.version>
<spring-cloud.version>Greenwich.SR1</spring-cloud.version>
</properties> <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies> <dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build> <repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories> </project>
5.2 ZkDiscoveryApplication增加服务发现注解@EnableDiscoveryClient
package com.example.demo; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient; @SpringBootApplication
@EnableDiscoveryClient
public class ZkDiscoveryApplication {
public static void main(String[] args) {
SpringApplication.run(ZkDiscoveryApplication.class, args);
} }
5.3 增加Rest服务HelloWorldController.java
package com.example.demo; import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController; @RestController
public class HelloWorldController {
@GetMapping("/helloworld")
public String HelloWorld() {
return "Hello World!";
}
}
5.4. 属性文件配置
spring:
application:
name: HelloWorld
cloud:
zookeeper:
connect-string: localhost:2181
discovery:
enabled: true
server:
port: 8081
logging:
level:
org.apache.zookeeper.ClientCnxn: WARN
6.源码分析
以spring-boot app项目启动时注册服务ZookeeperAutoServiceRegistrationAutoConfiguration.java为入口
@Bean
@ConditionalOnMissingBean(ZookeeperRegistration.class)
public ServiceInstanceRegistration serviceInstanceRegistration(
ApplicationContext context, ZookeeperDiscoveryProperties properties) {
String appName = context.getEnvironment().getProperty("spring.application.name",
"application");
String host = properties.getInstanceHost();
if (!StringUtils.hasText(host)) {
throw new IllegalStateException("instanceHost must not be empty");
} ZookeeperInstance zookeeperInstance = new ZookeeperInstance(context.getId(),
appName, properties.getMetadata());
RegistrationBuilder builder = ServiceInstanceRegistration.builder() //1
.address(host) //2
.name(appName) //3
.payload(zookeeperInstance) //4
.uriSpec(properties.getUriSpec()); //5 if (properties.getInstanceSslPort() != null) {
builder.sslPort(properties.getInstanceSslPort());
}
if (properties.getInstanceId() != null) {
builder.id(properties.getInstanceId());
} // TODO add customizer? return builder.build();
}
6.1 创建ServiceInstance的builder
/**
* Return a new builder. The {@link #address} is set to the ip of the first
* NIC in the system. The {@link #id} is set to a random UUID.
*
* @return builder
* @throws Exception errors getting the local IP
*/
public static<T> ServiceInstanceBuilder<T>builder() throws Exception
{
String address = null;
Collection<InetAddress> ips = ServiceInstanceBuilder.getAllLocalIPs();
if ( ips.size() > 0 )
{
address = ips.iterator().next().getHostAddress(); // default to the first address
} String id = UUID.randomUUID().toString(); return new ServiceInstanceBuilder<T>().address(address).id(id).registrationTimeUTC(System.currentTimeMillis());
}
6.2 ZookeeperAutoServiceRegistration.java
注册方法
@Override
protected void register() {
if (!this.properties.isRegister()) {
log.debug("Registration disabled.");
return;
}
if (this.registration.getPort() == 0) {
this.registration.setPort(getPort().get());
}
super.register();
}
调用父类AbstractAutoServiceRegistration的注册方法
/**
* Register the local service with the {@link ServiceRegistry}.
*/
protected void register() {
this.serviceRegistry.register(getRegistration());
}
调用ZookeeperServiceRegistry的注册方法
/**
* TODO: add when ZookeeperServiceDiscovery is removed One can override this method to
* provide custom way of registering {@link ServiceDiscovery}
*/
/*
* private void configureServiceDiscovery() {
* this.zookeeperServiceDiscovery.configureServiceDiscovery(this.
* zookeeperServiceDiscovery.getServiceDiscoveryRef(), this.curator, this.properties,
* this.instanceSerializer, this.zookeeperServiceDiscovery.getServiceInstanceRef()); }
*/ @Override
public void register(ZookeeperRegistration registration) {
try {
getServiceDiscovery().registerService(registration.getServiceInstance());
}
catch (Exception e) {
rethrowRuntimeException(e);
}
}
最终调用org.apache.curator.x.discovery.details.ServiceDiscoveryImpl
/**
* Register/re-register/update a service instance
*
* @param service service to add
* @throws Exception errors
*/
@Override
public void registerService(ServiceInstance<T> service) throws Exception
{
Entry<T> newEntry = new Entry<T>(service);
Entry<T> oldEntry = services.putIfAbsent(service.getId(), newEntry);
Entry<T> useEntry = (oldEntry != null) ? oldEntry : newEntry;
synchronized(useEntry)
{
if ( useEntry == newEntry ) // i.e. is new
{
useEntry.cache = makeNodeCache(service);
}
internalRegisterService(service);
}
} @VisibleForTesting
protected void internalRegisterService(ServiceInstance<T> service) throws Exception
{
byte[] bytes = serializer.serialize(service);
String path = pathForInstance(service.getName(), service.getId()); final int MAX_TRIES = 2;
boolean isDone = false;
for ( int i = 0; !isDone && (i < MAX_TRIES); ++i )
{
try
{
CreateMode mode;
switch (service.getServiceType()) {
case DYNAMIC:
mode = CreateMode.EPHEMERAL;
break;
case DYNAMIC_SEQUENTIAL:
mode = CreateMode.EPHEMERAL_SEQUENTIAL;
break;
default:
mode = CreateMode.PERSISTENT;
break;
}
client.create().creatingParentContainersIfNeeded().withMode(mode).forPath(path, bytes);
isDone = true;
}
catch ( KeeperException.NodeExistsException e )
{
client.delete().forPath(path); // must delete then re-create so that watchers fire
}
}
}
观察zookeeper的生成情况

生成的helloWorld的服务信息如下:
{
"name": "HelloWorld",
"id": "ef95204e-f5e8-4c69-96e4-3f7cec8dce33",
"address": "DESKTOP-405G2C8",
"port": 8081,
"sslPort": null,
"payload": {
"@class": "org.springframework.cloud.zookeeper.discovery.ZookeeperInstance",
"id": "application-1",
"name": "HelloWorld",
"metadata": {
}
},
"registrationTimeUTC": 1552453808924,
"serviceType": "DYNAMIC",
"uriSpec": {
"parts": [
{
"value": "scheme",
"variable": true
},
{
"value": "://",
"variable": false
},
{
"value": "address",
"variable": true
},
{
"value": ":",
"variable": false
},
{
"value": "port",
"variable": true
}
]
}
}
7.碰到的问题
Thrown "KeeperErrorCode = Unimplemented for /services" exception
原因:Curator 和zookeeper的版本不一致
解决方式:zookeeper升级到最新的版本后异常消失
8.Spring Cloud中的Eureka和Zookeeper的区别
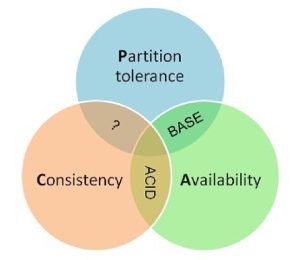
对于 zookeeper 来书,它是 CP 的。也就是说,zookeeper 是保证数据的一致性的。
Eureka 在设计时优先保证可用性,这就是 AP 原则。Eureka 各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。
9.总结
在微服务应用中,服务实例的运行环境会动态变化,实例网络地址也是如此。因此,客户端为了访问服务必须使用服务发现机制。
服务注册表是服务发现的关键部分。服务注册表是可用服务实例的数据库,提供管理 API 和查询 API。服务实例使用管理 API 来实现注册和注销,系统组件使用查询 API 来发现可用的服务实例。
服务发现有两种主要模式:客户端发现和服务端发现。在使用客户端服务发现的系统中,客户端查询服务注册表,选择可用的服务实例,然后发出请求。在使用服务端发现的系统中,客户端通过路由转发请求,路由器查询服务注册表并转发请求到可用的实例。
服务实例的注册和注销也有两种方式。一种是服务实例自己注册到服务注册表中,即自注册模式;另一种则是由其它系统组件处理注册和注销,也就是第三方注册模式。
在一些部署环境中,需要使用 Netflix Eureka、etcd、Apache Zookeeper 等服务发现来设置自己的服务发现基础设施。而另一些部署环境则内置了服务发现。例如,Kubernetes 和 Marathon 处理服务实例的注册和注销,它们也在每个集群主机上运行代理,这个代理具有服务端发现路由的功能。
HTTP 反向代理和 NGINX 这样的负载均衡器能够用做服务器端的服务发现均衡器。服务注册表能够将路由信息推送到 NGINX,激活配置更新,譬如使用 Cosul Template。NGINX Plus 支持额外的动态配置机制,能够通过 DNS 从注册表中获取服务实例的信息,并为远程配置提供 API。
参考文献
【1】https://cloud.spring.io/spring-cloud-zookeeper/1.2.x/multi/multi_spring-cloud-zookeeper-discovery.html
【2】https://cloud.spring.io/spring-cloud-zookeeper/1.2.x/multi/multi_spring-cloud-zookeeper-config.html
【3】http://www.enriquerecarte.com/2017-07-21/spring-cloud-config-series-introduction
【4】https://dzone.com/articles/spring-cloud-config-series-part-2-git-backend
【5】https://dzone.com/articles/spring-cloud-config-part-3-zookeeper-backend
【6】https://github.com/santteegt/spring-cloud-zookeeper-service-discovery-demo
【7】https://blog.csdn.net/peterwanghao/article/details/79722247
【8】https://www.cnblogs.com/EasonJim/p/7613734.html
【9】https://blog.csdn.net/eson_15/article/details/85561179
【10】https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
zookeeper服务发现实战及原理--spring-cloud-zookeeper源码分析的更多相关文章
- Spring Cloud Eureka源码分析之服务注册的流程与数据存储设计!
Spring Cloud是一个生态,它提供了一套标准,这套标准可以通过不同的组件来实现,其中就包含服务注册/发现.熔断.负载均衡等,在spring-cloud-common这个包中,org.sprin ...
- 【spring cloud】源码分析(一)
概述 从服务发现注解 @EnableDiscoveryClient入手,剖析整个服务发现与注册过程 一,spring-cloud-common包 针对服务发现,本jar包定义了 DiscoveryCl ...
- Spring Cloud Eureka源码分析 --- client 注册流程
Eureka Client 是一个Java 客户端,用于简化与Eureka Server的交互,客户端同时也具备一个内置的.使用轮询负载算法的负载均衡器. 在应用启动后,将会向Eureka Serve ...
- Spring Cloud Ribbon 源码分析---负载均衡算法
上一篇分析了Ribbon如何发送出去一个自带负载均衡效果的HTTP请求,本节就重点分析各个算法都是如何实现. 负载均衡整体是从IRule进去的: public interface IRule{ /* ...
- Spring Cloud Eureka源码分析---服务注册
本篇我们着重分析Eureka服务端的逻辑实现,主要涉及到服务的注册流程分析. 在Eureka的服务治理中,会涉及到下面一些概念: 服务注册:Eureka Client会通过发送REST请求的方式向Eu ...
- Spring Cloud Eureka源码分析之三级缓存的设计原理及源码分析
Eureka Server 为了提供响应效率,提供了两层的缓存结构,将 Eureka Client 所需要的注册信息,直接存储在缓存结构中,实现原理如下图所示. 第一层缓存:readOnlyCache ...
- Spring Cloud Ribbon源码分析---负载均衡实现
上一篇结合 Eureka 和 Ribbon 搭建了服务注册中心,利用Ribbon实现了可配置负载均衡的服务调用.这一篇我们来分析Ribbon实现负载均衡的过程. 从 @LoadBalanced入手 还 ...
- Spring Cloud Eureka源码分析之心跳续约及自我保护机制
Eureka-Server是如何判断一个服务不可用的? Eureka是通过心跳续约的方式来检查各个服务提供者的健康状态. 实际上,在判断服务不可用这个部分,会分为两块逻辑. Eureka-Server ...
- Feign 系列(05)Spring Cloud OpenFeign 源码解析
Feign 系列(05)Spring Cloud OpenFeign 源码解析 [TOC] Spring Cloud 系列目录(https://www.cnblogs.com/binarylei/p/ ...
随机推荐
- 无网 离线状态下pip3安装 django等软件
https://stackoverflow.com/questions/7300321/how-to-use-pythons-pip-to-download-and-keep-the-zipped-f ...
- gulp使用入门
介绍:Gulp 是基于node.js的一个前端自动化构建工具,可以使用它构建自动化工作流程(前端集成开发环境):不仅能对网站资源进行优化,而且在开发过程中很多重复的任务能够使用正确的工具自动完成,大大 ...
- Excel把数据存入共享字符串文件中并返回该字符串的下标
public static int InsertSharedStringItem(string text, pkg.SharedStringTablePart shareStringPart) { i ...
- 【adb】执行adb devices 设备offline
解决办法: 1.执行adb kill-server,在执行adb devices 2.重启手机 ---------------------------------------------------- ...
- 安装memcache遇到的坑
memcached 在make的时候出错,解决办法: # vim memcached.c 修改如下几行56 /* FreeBSD 4.x doesn't have IOV_MAX exposed. * ...
- 《HTTP权威指南》1-HTTP概要
Http HyperText Transfer Protocol,超文本协议通过此协议,我们可以将遍布全世界的Web服务器上的信息块快速,便捷,可靠的搬移到我们自己桌面上的Web浏览器上.这些信息块指 ...
- day_5字符串和列表的各种操作方法
字符串类型: 字符串的定义是可以有多种引号嵌套 定义字符串是以开头的引号然后匹配和第一个引号相同的引号,所以当字符串中间出现和第一个引号相同的引号就会出错,这个时候就可以选择别的引号进行创建字符串,或 ...
- codewars 题目笔记
原题: Description: Bob is preparing to pass IQ test. The most frequent task in this test is to find ou ...
- UITableViewCell上放UICollectionView ,UICollectionViewCell无法复用bug
如题: UITableViewCell上放UICollectionView ,UICollectionViewCell无法复用bug 如果UITableViewCell的size大于整个collect ...
- win10个人助理conrtana软件能否支持用户反馈、后续优化
上网查找了一下,win10的个人助理不支持用户反馈.这些反馈都是用户通过别的途径来发表反馈的信息,这个缺陷让用户不是特别满意,因为反馈信息不再那么简答,变得越来越繁琐.有些人还会担心自己反馈的问题会不 ...