OnlineJudge难度与正确度的相关性检验
本着做题的心态,上了东莞理工学院的 oj 网;在选择难度的时候发现有些题目通过率和难度可能存在着某些关系,于是决定爬下这些数据简单查看一下是否存在关系。
一、新建项目
我是用 Scrapy 框架爬取的(因为刚学没多久,顺便练练手)。首先,先新建 project (下载 Scarpy 部分已省略),在控制台输入 scrapy startproject onlineJudge(其中, onlineJudge为项目名称),敲击回车键新建项目完成。
二、明确目的
在动手写代码之前,先分析一下网页结构。网站是通过动态加载的,数据通过 json 文件加载。

1、明确要爬取的目标: http://oj.dgut.edu.cn/problems 网站里的题目,难度,提交量,通过率。在查找 json 的时候发现只有通过数,那么通过率就要自己计算。
2、打开 onlineJudge 目录下的 items.py 写下如下代码:
class OnlinejudgeItem(scrapy.Item):
id = scrapy.Field() # 题目编号
title = scrapy.Field() # 标题
difficulty = scrapy.Field() # 难度
submissionNo = scrapy.Field() # 提交量
acceptedNo = scrapy.Field() # 正确数
passingRate = scrapy.Field() # 正确率
三、制作爬虫
1、在当前目录下输入命令:scrapy genspider oj "oj.dgut.edu.cn" (其中 oj 是爬虫的名字,"oj.dgut.edu.cn"算是一个约束,规定一个域名)
2、打开 onlineJudge/spiders 下的 ojSpider.py ,增加或修改代码为:
import scrapy
import json
from onlineJudge.items import OnlinejudgeItem class OjSpider(scrapy.Spider):
name = 'oj' # 爬虫的名字
allowed_domains = ['oj.dgut.edu.cn'] # 域名范围
offset = 0
url = 'http://oj.dgut.edu.cn/api/xproblem/?limit=20&offset='
start_urls = [url + str(offset)] # 爬取的URL元祖/列表 def parse(self, response):
data = json.loads(response.text)['data']['results']
if len(data):
for i in range(len(data)):
submissionNo = data[i]['submission_number']
acceptedNo = data[i]['accepted_number']
try:
passingRate = round((int(acceptedNo)/int(submissionNo)) * 100, 2)
except ZeroDivisionError as e:
passingRate = 0 strPR = str(passingRate) + "%" item = OnlinejudgeItem() item['id'] = data[i]['_id']
item['title'] = data[i]['title']
item['difficulty'] = data[i]['difficulty']
item['submissionNo'] = submissionNo
item['acceptedNo'] = acceptedNo
item['passingRate'] = strPR yield item print(i)
self.offset += 20
yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
四、存储数据
1、打算将数据存储为 excel 文档,要先安装 openpyxl 模块,通过 pip install openpyxl 下载。
2、下载完成后,在 pipelines.py 中写入如下代码
from openpyxl import Workbook
class OnlinejudgePipeline(object):
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active # 激活工作簿
self.ws.append(['编号', '标题', '难度', '提交量', '正确数', '正确率']) # 设置表头
def process_item(self, item, spider):
line = [item['id'], item['title'], item['difficulty'],
item['submissionNo'], item['acceptedNo'], item['passingRate']]
self.ws.append(line)
self.wb.save('oj.xlsx')
return item
五、设置 settings.py
修改并增加代码:
LOG_FILE = "oj.log"
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'onlineJudge.pipelines.OnlinejudgePipeline': 300,
}
六、运行爬虫
在当前目录下新建一个 main.py 并写下如下代码
from scrapy import cmdline
cmdline.execute("scrapy crawl oj".split())
然后运行 main.py 文件。
于是,想要的数据就被爬下来了

七、分析数据
分析数据之前,先安装好 numpy,pandas,matplotlib,xlrd。
import pandas as pd
import xlrd data = pd.read_excel("../onlineJudge/onlineJudge/oj.xlsx") # 导入 excel 文件
data.describe()
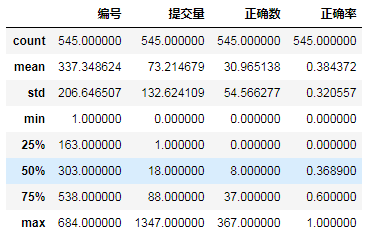
通过观察,数据没有异常值以及确实值,虽然提交量和正确数有为0的部分,但属于正常范围,不做处理。
data = data.set_index('编号') # 设置编号为索引
data.head() # 显示前五条信息

from matplotlib import pyplot as plt
import matplotlib.style as psl
%matplotlib inline psl.use('seaborn-colorblind') # 设置图表风格
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
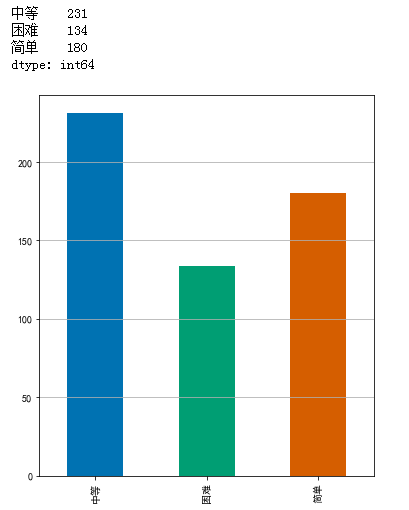
查看题目各难度的数目:
level_values = data['难度'].values
difficulties = {
'简单': 0,
'中等': 0,
'困难': 0
}
for value in level_values:
if value == '简单':
difficulties['简单'] += 1
elif value == '中等':
difficulties['中等'] += 1
else:
difficulties['困难'] += 1
level = pd.Series(difficulties)
print(level)
level.plot(kind = 'bar', figsize=(6, 7))
plt.grid(axis='y')
验证正确率与难度之间是否存在关系:
import numpy as np relation = data[['难度', '正确率']]
rate_values = relation['正确率'].values fig, axes = plt.subplots(figsize=(15, 6))
axes.scatter(rate_values, level_values)
plt.grid(axis='x')
plt.xticks(np.arange(0, 1, 0.05))
plt.xlabel('正确率')
plt.ylabel('难度')
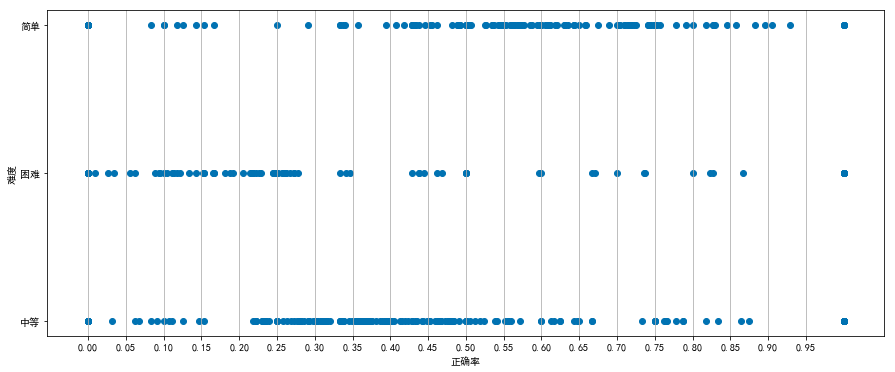
根据图像显示,题目难度跟正确率存在一定关系,困难的题目正确率相对集中于8%-28%,中等难度的题目比较集中在23%-55%,简单难度的题目正确率主要在40%以上。
OnlineJudge难度与正确度的相关性检验的更多相关文章
- python相关性分析与p值检验
## 最近两天的成果 ''' ########################################## # # # 不忘初心 砥砺前行. # # 418__yj # ########### ...
- 使用K-S检验一个数列是否服从正态分布、两个数列是否服从相同的分布
假设检验的基本思想: 若对总体的某个假设是真实的,那么不利于或者不能支持这一假设的事件A在一次试验中是几乎不可能发生的.如果事件A真的发生了,则有理由怀疑这一假设的真实性,从而拒绝该假设. 实质分析: ...
- 【应用】R--判断类别型属性之间是否有相关性(相互之间是否独立)
检验某学区所有在售房源中,小区与楼栋类别(低层:多层;小高层:高层)是否相关 导入数据: > house<- read.table("house_data.txt", ...
- Mahout的taste里的几种相似度计算方法
欧几里德相似度(Euclidean Distance) 最初用于计算欧几里德空间中两个点的距离,以两个用户x和y为例子,看成是n维空间的两个向量x和y, xi表示用户x对itemi的喜好值,yi表示 ...
- 2017高教杯数学建模B 题分析
B题原文 "拍照赚钱"是移动互联网下的一种自助式服务模式.用户下载APP,注册成为APP的会员,然后从APP上领取需要拍照的任务(比如上超市去检查某种商品的上架情况),赚取APP对 ...
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- 简单介绍一下R中的几种统计分布及常用模型
统计学上分布有很多,在R中基本都有描述.因能力有限,我们就挑选几个常用的.比较重要的简单介绍一下每种分布的定义,公式,以及在R中的展示. 统计分布每一种分布有四个函数:d――density(密度函数) ...
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
原文 http://dataunion.org/14072.html 主题 特征选择 scikit-learn 作者: Edwin Jarvis 特征选择(排序)对于数据科学家.机器学习从业者来说非 ...
- 结合Scikit-learn介绍几种常用的特征选择方法
特征选择(排序)对于数据科学家.机器学习从业者来说非常重要.好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点.底层结构,这对进一步改善模型.算法都有着重要作用. 特征选择主要有两个功能: 减 ...
随机推荐
- Nexus安装、使用说明、问题总结
Nexus安装.使用说明.问题总结 1 . 私服简介 私服是架设在局域网的一种特殊的远程仓库,目的是代理远程仓库及部署第三方构件.有了私服之后,当 Maven 需要下载构件时,直接请求私服,私服上存在 ...
- 摘录<小王子>——[法]安东·圣埃克苏佩里
四 大人们都喜欢数字.你要是向他们说起一个新朋友,他们提出的问题从来问不到点子上. 他们绝不会问:"他的嗓音怎么样?他喜欢什么游戏?比如,他喜欢搜集蝴蝶标本吗?" 他们总是问你:& ...
- 用mplayer从视频中按周期提取帧
使用方法:extract file time step folder time 设置时间长度 step 设置周期 均以秒(s)为单位 贡献:1. 从视频文件中周期性提取图片:2. Windows下批处 ...
- weblogic 控制台访问速度很慢的解决方案
实际是JVM在Linux下的bug 他想调用一个随机函数 但取不到 暂时的解决办法是 1)较好的解决办法: 在Weblogic启动参数里添加 “- Djava.security.egd=file:/d ...
- Spark Programming--- Shuffle operations
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- .Net Framework 4.x 程序到底运行在哪个 CLR 版本之上(ZT)
本文转载 https://walterlv.github.io/dotnet/2017/09/22/dotnet-version.html ,感谢 吕毅 (包含链接: https://walte ...
- Ubuntu 16.04下Samba服务器搭建和配置(配截图)
一.相关介绍 Samba是在Linux和UNIX系统上实现SMB协议的一个免费软件,由服务器及客户端程序构成.SMB(Server Messages Block,信息服务块)是一种在局域网上共享文件和 ...
- JAVAEE企业级应用开发浅谈之MVC 中的V-VIEW视图
Step1.情景概要 Hello,小伙伴们,好久不见,之前跟大家分享了三层架构与MVC思想,相信大家对于这两块内容有了相对清晰的个人认识了,既然我们讲到了MVC,这里我们接着这块内容继续往下深入,今天 ...
- Java开发微服务为什么一定要选spring cloud?
来自:网易乐得技术团队,作者:董添 李秉谦 现如今微服务架构十分流行,而采用微服务构建系统也会带来更清晰的业务划分和可扩展性.同时,支持微服务的技术栈也是多种多样的,本系列文章主要介绍这些技术中的翘楚 ...
- 一些能体现个人水平的SQL语句[总结篇]
作为一名小小的开发人员,刚入门的时候觉得很难,过了一段时间之后,发现很简单,很快就可以搞定很bug了.然而这并不能说明你就已经很牛掰了,只能说,你不了解其他太多的东西.应该说,数据库有几个共同的命令, ...