HBase在HDFS上的目录介绍
总所周知,HBase 是天生就是架设在 HDFS 上,在这个分布式文件系统中,HBase 是怎么去构建自己的目录树的呢?
第一,介绍系统级别的目录树。
一、0.94-cdh4.2.1版本
系统级别的一级目录如下,用户自定义的均在这个/hbase 下的一级子目录下
/hbase/-ROOT-
/hbase/.META.
/hbase/.archive
/hbase/.corrupt
/hbase/.hbck
/hbase/.logs
/hbase/.oldlogs
/hbase/.snapshot
/hbase/.tmp
/hbase/hbase.id
/hbase/hbase.version
1、/hbase/-ROOT-
hbase读写数据的时候采用三级寻址方式,首先找到从 zk 中找到ROOT 表所在位置,通过 ROOT 表找到 META 表所在位置,然后再从 META 表定位到你要读写数据Region 所在的Regionserver。所以-ROOT-目录对应 HBase 中的系统表ROOT,就不多做解释了。
2、/hbase/.META.
就是存储1中介绍的 META 表的存储路径。
3、/hbase/.archive
HBase 在做 Split或者 compact 操作完成之后,会将 HFile 移到.archive 目录中,然后将之前的 hfile 删除掉,该目录由 HMaster 上的一个定时任务定期去清理。
4、/hbase/.corrupt
存储HBase做损坏的日志文件,一般都是为空的。
5、/hbase/.hbck
HBase 运维过程中偶尔会遇到元数据不一致的情况,这时候会用到提供的 hbck 工具去修复,修复过程中会使用该目录作为临时过度缓冲。
6、/hbase/.logs
大家都知道 HBase 是支持 WAL(Write Ahead Log) 的,HBase 会在第一次启动之初会给每一台 RegionServer 在.log 下创建一个目录,若客户端如果开启WAL 模式,会先将数据写入一份到.log 下,当 RegionServer crash 或者目录达到一定大小,会开启 replay 模式,类似 MySQL 的 binlog。
7、/hbase/.oldlogs
当.logs 文件夹中的 HLog 没用之后会 move 到.oldlogs 中,HMaster 会定期去清理。
8、/hbase/.snapshot
hbase若开启了 snapshot 功能之后,对某一个用户表建立一个 snapshot 之后,snapshot 都存储在该目录下,如对表test 做了一个 名为sp_test 的snapshot,就会在/hbase/.snapshot/目录下创建一个sp_test 文件夹,snapshot 之后的所有写入都是记录在这个 snapshot 之上。
9、/hbase/.tmp
当对表做创建或者删除操作的时候,会将表move 到该 tmp 目录下,然后再去做处理操作。
10、/hbase/hbase.id
它是一个文件,存储集群唯一的 cluster id 号,是一个 uuid。
11、/hbase/hbase.version
同样也是一个文件,存储集群的版本号,貌似是加密的,看不到,只能通过web-ui 才能正确显示出来。
二、0.98.8版本
自0.96版本之后,hbase 源码结构上做了很大的优化,目录结构也发生了变化,做了精简和优化,这里以0.98.8为例介绍,目录如下:
/hbase/.tmp
/hbase/WALs
/hbase/archive
/hbase/corrupt
/hbase/data
/hbase/hbase.id
/hbase/hbase.version
/hbase/oldWALs
1、/hbase/.tmp
这个目录不变还是原来的tmp目录,作用是一样的。
2、/hbase/WALs
这里对应0.94的.logs 目录,取名为 WALs 更加见名知意了,点个赞!
3、/hbase/archive
和0.94一样,只是去掉了.而已,估计是作者不想把它作为一个隐藏文件夹了吧
4、/hbase/corrupt
和0.94一样,去了.
5、/hbase/data
这个才是 hbase 的核心目录,0.98版本里支持 namespace 的概念模型,系统会预置两个 namespace 即:hbase和default
5.1 /hbase/data/default
这个默认的namespace即没有指定namespace 的表都将会flush 到该目录下面。
5.2 /hbase/data/hbase
这个namespace 下面存储了 HBase 的 namespace、meta 和acl 三个表,这里的 meta 表跟0.94版本的.META.是一样的,自0.96之后就已经将 ROOT 表去掉了,直接从Zookeeper 中找到meta 表的位置,然后通过 meta 表定位到 region。
如果自定义一些 namespace 的话,就会再/hbase/data 目录下新建一个 namespace 文件夹,该 namespace 下的表都将 flush 到该目录下。
6、/hbase/hbase.id
它是一个文件,存储集群唯一的 cluster id 号,是一个 uuid。
7、/hbase/hbase.version
同样也是一个文件,存储集群的版本号,貌似是加密的,看不到,只能通过web-ui 才能正确显示出来。
8、/hbase/oldWALs
这里对应0.94的.oldlogs 目录,取名为 oldWALs 是不是更好了呢!
第二,介绍用户级别的目录,也就是表数据存储目录结构。
进入上文提到的系统级目录/hbase/data/default下面,如下图所示,其中test就是一个hbase表名。
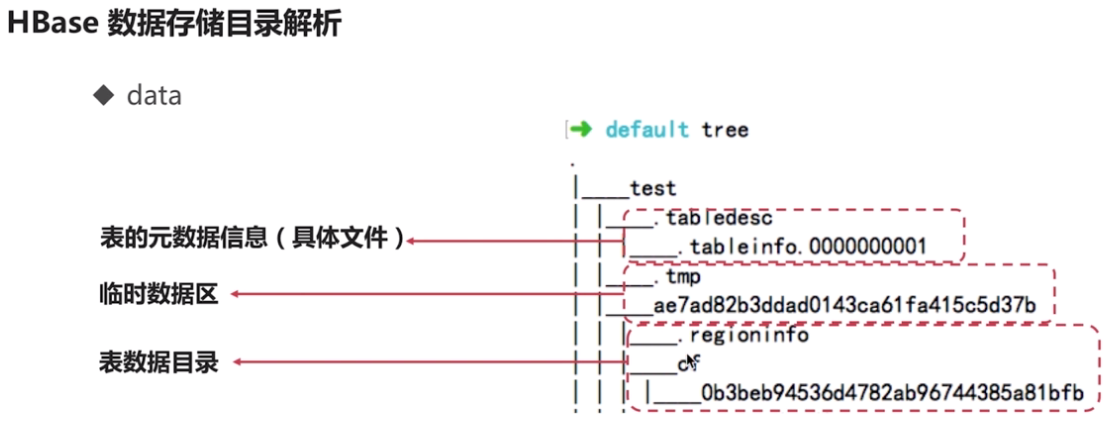
参考:https://www.cnblogs.com/nexiyi/p/hbase_on_hdfs_directory.html
HBase在HDFS上的目录介绍的更多相关文章
- HBase 在HDFS 上的目录树
总所周知,HBase 是天生就是架设在 HDFS 上,在这个分布式文件系统中,HBase 是怎么去构建自己的目录树的呢? 这里只介绍系统级别的目录树. 一.0.94-cdh4.2.1版本 系 ...
- HBase在HDFS上的目录树
众所周知,HBase 是天生就是架设在 HDFS 上,在这个分布式文件系统中,HBase 是怎么去构建自己的目录树的呢? 这里只介绍系统级别的目录树: 一.0.94-cdh4.2.1版本 系统级别的一 ...
- HBase 在HDFS上的物理目录结构
根目录 配置项 hbase.rootdir 默认 "/hbase" 根级文件 /hbase/WALs 被HLog实例管理的WAL文件. /hbase/WALs/data-hbase ...
- hbase 从hdfs上读取数据到hbase中
<dependencies> <dependency> <groupId>org.apache.hbase</groupId> <artifact ...
- 删除hdfs上的内容报错:rm: Cannot delete /wxcm/ Name node is in safe mode.
问题:在执行删除hdfs上的内容时(hdfs dfs -rm -f -r -skipTrash /wxcm)报错:rm: Cannot delete /wxcm/ Name node is in sa ...
- MapReduce读取hdfs上文件,建立词频的倒排索引到Hbase
Hdfs上的数据文件为T0,T1,T2(无后缀): T0: What has come into being in him was life, and the life was the light o ...
- hive的数据导入与数据导出:(本地,云hdfs,hbase),列分隔符的设置,以及hdfs上传给pig如何处理
hive表的数据源有四种: hbase hdfs 本地 其他hive表 而hive表本身有两种: 内部表和外部表. 而hbase的数据在hive中,可以建立对应的外部表(参看hive和hbase整合) ...
- hbase+hadoop+hdfs集群搭建 集成spring
序言 最近公司一个汽车项目想用hbase做存储,然后就有了这篇文字,来,来,来, 带你一起征服hbase,并推荐一本书<hbase权威指南> 这是一本极好的hbase入门书籍,我花了一个晚 ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
随机推荐
- ubuntu主题收集
ubuntu主题收集 一些cmd常用命令: 任务栏底部,进入Dash并打开终端,命令最后一个是参数可选 ( Left | Bottom ) gsettings set com.canonical.Un ...
- HanLP二元核心词典解析
HanLP二元核心词典解析 本文分析:HanLP版本1.5.3中二元核心词典的存储与查找.当词典文件没有被缓存时,会从文本文件CoreNatureDictionary.ngram.txt中解析出来存储 ...
- UDP客户/服务器程序所用的套接字函数
- UVAlive 6697 Homework Evaluation
借鉴了别人的博客啊,自己写写给以后的自己看吧 给出两个字符串,用第二个字符串去匹配第一个字符串,可以对第二个字符串进行删除或插入操作,一位匹配成功得8分失败-5分,如果插入或删除,对于连续插入或删除m ...
- 【Ubuntu】安装Java和Eclipse
1. 安装Java 1> sudo add-apt-repository ppa:webupd8team/java 2> sudo apt-get update 3> sudo ap ...
- 【python小练】0010
第 0010 题:使用 Python 生成类似于下图中的字母验证码图片 思路: 1. 随机生成字符串 2. 创建画布往上头写字符串 3. 干扰画面 code: # codeing: utf-8 fro ...
- Spring 快速开始 Profile 和 Bean
和maven profile类似,Spring bean definition profile 有两个组件:声明和激活. [栗子:开发测试环境使用HyperSQL 生产环境使用JNDI上下文根据配置查 ...
- luogu P4899 [IOI2018] werewolf 狼火
传送门 首先很显然,从人形起点出发能到的点和狼形能到终点的点都是一个联通块,如果能从起点到终点则说明这两个联通块有交 这个时候可以请出我们的克鲁斯卡尔重构树,即对原图分别建两棵重构树,一棵边权为两端点 ...
- webpack 配置全局 jQuery 对象
将 lodash 添加到当前模块的上下文中 import _ from 'lodash' 但是你想每个模块都引入的话就特别麻烦,这里有插件可以帮助到您,只需在 webpack.config.js 中配 ...
- Linux故障:linux中使用ifconfig命令查看网卡信息时显示为eth1,但是在network-scripts中只有ifcfg-eth0的配置文件,并且里面的NAME="eth0"。
linux中使用ifconfig命令查看网卡信息时显示为eth1,但是在network-scripts中只有ifcfg-eth0的配置文件,并且里面的NAME="eth0". ...