PC平台主要SIMD扩展发展简史
Single Instruction Multiple Data,简称SIMD。SIMD描述的是微处理器中单条指令能完成对数据的并行处理。SIMD所使用的是特殊的寄存器,一个寄存器上存储有多个数据,在进行SIMD运算时,这些数据会被分别进行处理,以此实现了数据的并行处理。
MMX
Intel的第一个SIMD指令集是MultiMedia eXtensions(MMX),在1997年推出。MMX指令主要使用的寄存器为 MM0 ~ MM7,大小为64-bit,这些寄存器是浮点寄存器ST0~ST7(80-bit)的一部分,因此MMX与浮点运算不能同时进行。
| Register | |
| 79- | 64 |
-->79 - 64
-->63 - 0
MMX指令能一次性地操作1个64-bit的数据、或者两个32-bit的数据、或者4个16-bit的数据、或者8个8-bit的数据。
| Register | Description | ||||||||||||||||
|
A Single 64-bit Quadword | ||||||||||||||||
|
2 32-bit Doublewords | ||||||||||||||||
|
4 16-bit Words | ||||||||||||||||
|
8 8-bit Bytes |
MMX的指令除了 emms , movd 以及 movq 之外,其余都以字母p开头,字母p代表packed,即表示操作多个数据。MMX指令处理的数据皆为整型,不能处理浮点数据。
SSE
Intel于1999年在Pentium III时对SIMD做了扩展,名为Streaming SIMD eXtensions(SSE),AMD则是在2001年发布的Athlon XP开始支持SSE。与MMX不同,SSE采用了独立的寄存器组 XMM0 ~ XMM7,64位模式下为 XMM0 ~ XMM15 ,并且这些寄存器的长度也增加到了128-bit。另外还增加了一个32-bit的控制寄存器 MXCSR ,这个寄存器主要用于对SSE寄存器/指令进行控制,也有flag功能。
| Register | Description | ||||||||
|
4 Single-Precisions |
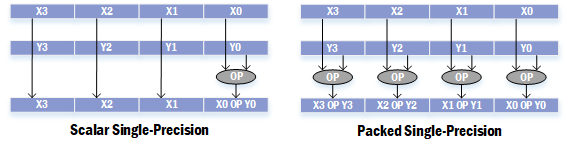
SSE对MMX处理整型数据的指令做了扩展,添加了几条用于处理整型数据的指令,同样以字母p开头。不过SSE新增指令大多是对浮点数据并行处理的指令,这类指令以两个字母ss或者ps为结尾。ss代表了scalar single-precision,ps代表了packed single-precision。single-precision就是一个32-bit的浮点数,也就是说一个XMM寄存器可以存储4个single-precision,scalar表示只处理最低位的那个浮点数,packed表示处理全部四个浮点数。
此外SSE也增加了几条内存操作相关的指令:MASKMOVQ, MOVNTQ, MOVNTPS(不经过cache直接写回内存),PREFETCHh(从内存读取数据到cache),SFENCE(用于保证位于SFENCE指令前的store指令先于SFENCE后的store指令完成)。
在SSE当中,MMX只能操作MMX寄存器,即以字母p开头的指令只能操作MMX寄存器。XMM寄存器专门用于浮点数据的并行处理。
SSE2
2000年,Intel从Pentium 4微处理器开始首次引入SSE2,AMD则是在2003年开始支持SSE2。SSE2相比前两代的SIMD扩展有两方面的大改进。
在SSE时加入的128-bit XMM寄存器组原本只能用于浮点数据的并行处理,而更常用的MMX指令集只能操作64-bit的MMX寄存器组,这样造成了资源的浪费。因此在SSE2中,允许128-bit的XMM寄存器组存储整型数据,MMX指令集可以对XMM寄存器组进行整型数据的操作,如此一来整型数据的并行处理能力增加了一倍。
MMX指令集中,原来并行处理的最大整型为32-bit的Doubleword,而XMM寄存器大小为128-bit,能同时处理两个64-bit的Quadword,所以SSE2增加了可以并行处理64-bit整型数据的指令,这些指令一般以q为结尾,意为 quadword。
| Register | Description | ||||||||||||||||||||||||||||||||
|
128-bit | ||||||||||||||||||||||||||||||||
|
A Double 64-bit Quadword | ||||||||||||||||||||||||||||||||
|
4 32-bit Doublewords | ||||||||||||||||||||||||||||||||
|
8 16-bit Words | ||||||||||||||||||||||||||||||||
|
16 8-bit Bytes |
另一方面,SSE2扩展了浮点类型数据的处理指令。SSE中只能处理长度为32-bit的Single-Precision,SSE2把浮点数据的长度扩展到了64-bit的Double-Precision。这类处理64-bit浮点数据类型的SIMD指令以sd或者pd结尾,分别代表scalar double-precision与packed double-precision。
| Register | Description | ||||
|
2 Double-Precisions |
此外,SSE2也增加了一些控制指令。
SSE3
2004年,在Intel发布的Pentium 4 Prescott微处理器上对SIMD扩展到了SSE3,AMD则是在2005年开始支持了SSE3。SSE3所做的扩展内容并不多,只是增加了13条新指令。不过这些都不是太常用的指令,其中包括浮点水平算术运算、水平复制移动等。
SSSE3
Intel Core 2微处理器时推出了Supplemental Streaming SIMD eXtensions (SSSE3)。增加的指令也不多,包括整型水平算术运算以及较为常用的绝对值运算等。
SSE4
SSE4指令集在2006年发布,并在2007年初实现在了Intel以及AMD的处理器上。SSE4包括三大类:
- SSE4.1 主要目的是用于提升音视频、图像、3D等方向的数据处理的性能。如MPSADBW在寻找两张图像的匹配块时能起到很大的作用。
- SSE4.2 主要目的是用于提升字符串、文本等(字符比对)方面的数据处理性能。
- SSE4a 是AMD专用的扩展。主要添加了一些位处理指令。
AVX
Advanced Vector eXtentions(AVX)在2008年由Intel与AMD提出,并于2011年分别在Sandy Bridge以及Bulldozer架构上提供支持。AVX的主要改进在于对寄存器长度的扩展以及提供了更灵活的指令集。
AVX对 XMM 寄存器做了扩展,从原来的128-bit扩展到了256-bit,256-bit的寄存器命名为 YMM 。YMM的低128-bit是与XMM混用的。
| Register | 255 - 128 | 127 - 0 |
| YMM | YMM_H | XMM |
AVX对SSE指令集做了扩展,对SSE指令添加了前缀v(VEX)。我传统的x86指令很多都是只有两个操作数:op dest, src,两个操作数在进行运算后得到的结果会把dest给覆盖,如果后续的操作需要原来的dest来执行某些操作,则必须多添加一条指令把dest中的数据提取到别的寄存器。AVX扩展为了处理这种情况,新增了一个操作数专门用于存储处理结果 vop dest,src1, src2 ,如此一来使得两条指令变成一条指令,减少了的数据的移动,并且这类指令也能进行micro-fusion。
VEX前缀的指令集可以操作大多数的XMM(VEX.128)以及YMM(VEX.256)。不过AVX的扩展指令集中并不包括整型数据的处理指令,VEX前缀只能加在浮点指令上。也就是说AVX只支持256-bit的SIMD浮点数据的并行处理。
AVX2
2013年Intel发布的Haswell处理器上开始支持AVX2,AMD则是2015年的Excavator处理器。
AVX2主要为处理整型数据的指令提供VEX前缀,为256-bit的SIMD整型数据的并行处理提供支持。
AVX-512
AVX-512由Intel在2013年提出,并在2016年推出首次支持了AVX-512的处理器Xeon Phi x200 (Knights Landing)。
如扩展名所示,AVX-512主要改进是把SIMD寄存器扩展到了512-bit。其主要新增的特性可以归纳如下:
- 把 YMM 扩展到了512-bit的 ZMM ,ZMM的低256-bit与YMM混用。
- YMM / ZMM 寄存器的数量增加到了32个,其中 YMM8 ~ YMM31 / ZMM8 ~ ZMM31 只有CPU工作在64位模式下才能使用。
- 支持opmask。SIMD指令一般都是操作寄存器上的多组数据,此处增加的opmask就是用于控制其中的各组数据是否需要执行,格式如:VADDPS zmm1 {k1}{z}, zmm2, zmm3,当中的k1就是opmask寄存器,z表示对不进行操作的那组数据,往目标寄存器写0。一共有7个opmask register(k0 ~ k7)。
- 操作512-bit的ZMM时使用的前缀为EVEX,实际上一些汇编器用的都是v作为指令前缀。
| Register | 511 - 256 | 255 - 128 | 127 - 0 |
| ZMM | ZMM_H | YMM_H | XMM |
AESNI & SHA Extensions
Advanced Encryption Standard New Instructions(AESNI)扩展在2008年由Intel与AMD提出,目的是用于AES的加密解密。在2010年Intel在其Westmere(32nm Nehalem)架构上首次支持该指令集,而AMD则是2011年在Bulldozer架构上首次支持。
Secure Hash Algorithm (SHA)扩展在2013年引入到Intel指令集中,主要用于SHA-1以及SHA-256的计算。2016年,Intel与AMD分别在他们的Goldmont以及Ryzen架构中支持SHA扩展指令集。
Reference:
Intel 64 and IA-32 Architectures Software Developer's Manual
New Instructions Supporting the Secure Hash Algorithm on Intel® Architecture Processors
PC平台主要SIMD扩展发展简史的更多相关文章
- PC平台的SIMD支持检测
如果我们希望在用SIMD来提升程序处理的性能,首先需要做的就是检测程序所运行的平台是否支持相应的SIMD扩展.平台对SIMD扩展分为两部分的支持: CPU对SIMD扩展的支持.SIMD扩展是随着CPU ...
- java 发展简史
[0]README 0.1) 本文转自 core java volume 1,仅供了解Java 的发展历史,它的前世今生,所谓知己知彼,百战不殆(just a joke) : [1]java 发展简史 ...
- Kubernetes 入门必备云原生发展简史
作者|张磊 阿里云容器平台高级技术专家,CNCF 官方大使 "未来的软件一定是生长于云上的"这是云原生理念的最核心假设.而所谓"云原生",实际上就是在定义一条能 ...
- Web前端发展简史
Web前端发展简史 有人说“前端开发”是IT界最容易被误解的岗位,这不是空穴来风.如果你还认为前端只是从美工那里拿到切图, JS和CSS一番乱炖,难搞的功能就去网上信手拈来,CtrlC + Ctrl ...
- 2018-2019-2 20165316 《网络对抗技术》Exp1 PC平台逆向破解
2018-2019-2 20165316 <网络对抗技术>Exp1 PC平台逆向破解 1 逆向及Bof基础实践说明 1.1 实践目标 本次实践的对象是一个名为pwn1的linux可执行文件 ...
- PC平台在Unity3D中播放硬盘ogg,mp3,wav文件
Unity3D PC平台本身是支持直接用www读取本地ogg,wav的,但是并不能读取byte[],字节数组格式,这对用习惯了bass,fmod的人来说有点不方便. 搜了一圈发现了一个C#的音频库叫N ...
- 发展简史jQuery时间轴特效
发展简史jQuery时间轴特效.这是一款鼠标滚动到一定的高度动画显示企业发展时间轴特效.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div class="wr ...
- AI技术说:人工智能相关概念与发展简史
作为近几年的一大热词,人工智能一直是科技圈不可忽视的一大风口.随着智能硬件的迭代,智能家居产品逐步走进千家万户,语音识别.图像识别等AI相关技术也经历了阶梯式发展.如何看待人工智能的本质?人工智能的飞 ...
- SIMD数据并行(二)——多媒体SIMD扩展指令集
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multip ...
随机推荐
- python调用数据返回字典dict数据的现象2
python调用数据返回字典dict数据的现象2 思考: 话题1连接:https://www.cnblogs.com/zwgbk/p/10248479.html在打印和添加时候加上内存地址id(),可 ...
- Google机器学习课程基于TensorFlow : https://developers.google.cn/machine-learning/crash-course
Google机器学习课程基于TensorFlow : https://developers.google.cn/machine-learning/crash-course https ...
- Vue-插槽学习
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 10分钟开发 GPS 应用,了解一下
1 前言 在导师公司实习了半个月,参加的是尾气遥测项目,我的任务是开发GPS 的相关事情,从零到有的开发出了 GPS 的 Winform 应用,在这里记录一下开发过程和简要的描述一下将 GPS 数据提 ...
- 翻转一个数组(c++实现)
反转一个数组: 其实STL中的vector有一个reverse函数便可以使用. #include<iostream> using namespace std; int* ReverseAr ...
- Contest1692 - 2019寒假集训第三十一场 UPC 11075 Problem D 小P的国际象棋
非常简单的单点修改+区间加+区间查询.我用的是最近刚学的区间修改版本树状数组. 直接维护即可,注意修改后的单点值已经不是a[i],或者b[i],要通过区间查询求单点.不然是错的. 区间修改版本树状数 ...
- hdu3790 dijkstra+堆优化
题目来源:http://acm.hdu.edu.cn/showproblem.php?pid=3790 分析:dijkstra没有优化的话,复杂度是n*n,优化后的复杂度是m*logm,n是顶点数,m ...
- python中map()函数用法
map函数的原型是map(function, iterable, …),它的返回结果是一个列表. 参数function传的是一个函数名,可以是python内置的,也可以是自定义的. 参数iterabl ...
- PS调出春夏外景婚纱照
效果图 先来看看原图和夏季的效果图 先看看原图 教程终于来咯 原图暗部太深,需要将暗部提亮.可以把暗部选区选出来.为了精确选择暗部选区,我利用计算命令如上图所示.最后得到暗部的选区. 上图得到了暗部选 ...
- 【学习总结】GirlsInAI ML-diary day-2-Python版本选取与Anaconda中环境配置与下载
[学习总结]GirlsInAI ML-diary 总 原博github链接-day2 Python版本选取与Anaconda中环境配置与下载 1-查看当前Jupyter的Python版本 开始菜单选J ...