『Kaggle』分类任务_决策树&集成模型&DataFrame向量化操作
决策树这节中涉及到了很多pandas中的新的函数用法等,所以我单拿出来详细的理解一下这些pandas处理过程,进一步理解pandas背后的数据处理的手段原理。
决策树程序
数据载入
pd.read_csv()竟然可以直接请求URL... ...
DataFrame.head()可以查看前面几行的数据,默认是5行
DataFrame.info()可以查看数据的统计情报
'''数据载入'''
import pandas as pd titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
print(titanic.head(), '\n\n', '___*___'*15)
# DataFrame.head(n=5)
# Returns first n rows
print(titanic.info())
.info()方法会统计各列的信息,包含数据量(不足的表示有空缺需要进一步补全)和数据格式(一般数字的没问题,obj对象要进一步处理为数字才能处理)等。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1313 entries, 0 to 1312
Data columns (total 11 columns):
row.names 1313 non-null int64
pclass 1313 non-null object
survived 1313 non-null int64
name 1313 non-null object
age 633 non-null float64
embarked 821 non-null object
home.dest 754 non-null object
room 77 non-null object
ticket 69 non-null object
boat 347 non-null object
sex 1313 non-null object
dtypes: float64(1), int64(2), object(8)
memory usage: 112.9+ KB
None
数据预处理
对于特征太多的数据需要人为选择一下,这里是泰坦尼克号的乘客数据,因为认为'pclass', 'age', 'sex'几个特征可能更有代表性,所以选取了这几个特征。
DataFrame['列名'].fillna()用于填充空白
参数1表示填充值
参数2inplace表示就地填充,默认false,即不修改原df,返回一个修改过的新的df
使用时注意,一般各个列数据意义不同,所以需要各自填充,所以我加了个['列名']。
'''数据预处理'''
# 选择特征,实际上可选特征很多,但是这几个特征与幸存与否可能关联更大
X = titanic[['pclass', 'age', 'sex']]
# 选择标签
y = titanic['survived'] # 查看特征
print(X.info())
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 1313 entries, 0 to 1312
# Data columns (total 3 columns):
# pclass 1313 non-null object
# age 633 non-null float64
# sex 1313 non-null object
# dtypes: float64(1), object(2)
# memory usage: 30.9+ KB
# None
# 任务:
# 1.age数据明显缺失
# 2.pclass和sex数据类型不是数字,需要更改 X['age'].fillna(X['age'].mean(), inplace=True) # fillna返回一个新对象,inplace = True 可以就地填充
print(X.info())
数据集划分
'''数据集划分'''
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
特征提取器
'''特征提取器'''
from sklearn.feature_extraction import DictVectorizer vec = DictVectorizer(sparse=False)
print(X_train.to_dict(orient='record'))
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
print(X_train)
print(vec.feature_names_)
X_test = vec.transform(X_test.to_dict(orient='record'))
涉及两个操作,
- DataFrame字典化
- 字典向量化
1.DataFrame字典化

import numpy as np
import pandas as pd index = ['x', 'y']
columns = ['a','b','c'] dtype = [('a','int32'), ('b','float32'), ('c','float32')]
values = np.zeros(2, dtype=dtype)
df = pd.DataFrame(values, index=index)
df.to_dict(orient='record')
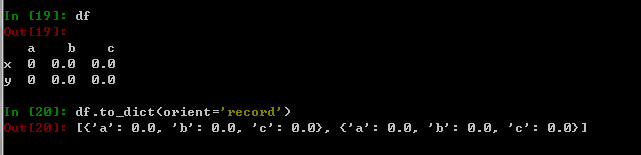
2.字典向量化
DictVectorizer: 将dict类型的list数据,转换成numpy array,具有属性vec.feature_names_,查看提取后的特征名。
具体效果如下,
>>> from sklearn.feature_extraction import DictVectorizer
>>> v = DictVectorizer(sparse=False)
>>> D = [{'foo': 1, 'bar': 2}, {'foo': 3, 'baz': 1}]
>>> X = v.fit_transform(D)
>>> X
array([[ 2., 0., 1.],
[ 0., 1., 3.]])
>>> v.transform({'foo': 4, 'unseen_feature': 3})
array([[ 0., 0., 4.]])
数字的特征不变,没有该特征的项给赋0,对于未参与训练的特征不予考虑。
对应到本程序,
print(X_train.to_dict(orient='record')):
[{'sex': 'male', 'pclass': '3rd', 'age': 31.19418104265403},
...... ....... ....... ......
{'sex': 'female', 'pclass': '1st', 'age': 31.19418104265403}]
提取特征,
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
print(X_train):[[ 31.19418104 0. 0. 1. 0. 1. ]
[ 31.19418104 1. 0. 0. 1. 0. ]
[ 31.19418104 0. 0. 1. 0. 1. ]
...,
[ 12. 0. 1. 0. 1. 0. ]
[ 18. 0. 1. 0. 0. 1. ]
[ 31.19418104 0. 0. 1. 1. 0. ]]
数字的年龄没有改变,其他obj特征变成了onehot编码的特征,各列意义可以查看的,
print(vec.feature_names_):
['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male']
决策树
'''决策树'''
from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
y_predict = dtc.predict(X_test) '''模型评估'''
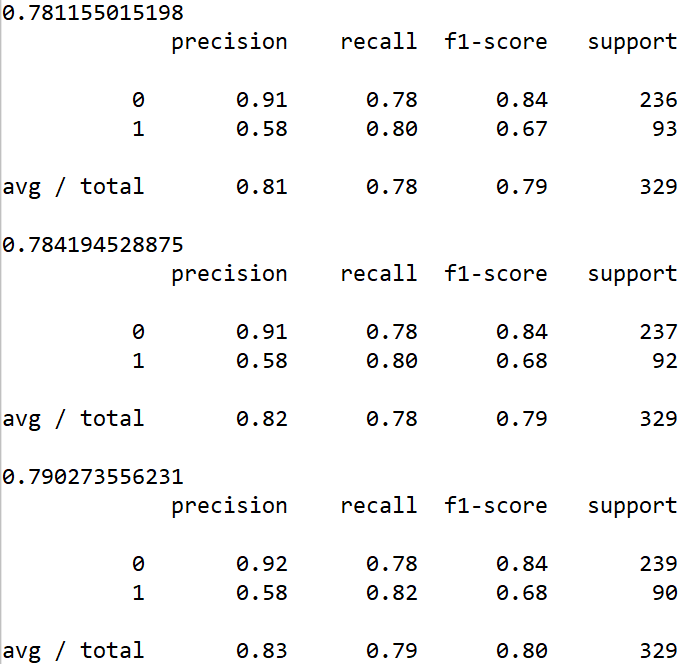
from sklearn.metrics import classification_report print(dtc.score(X_test ,y_test))
print(classification_report(y_predict, y_test, target_names=['died', 'suvived']))
0.781155015198
precision recall f1-score support
died 0.91 0.78 0.84 236
suvived 0.58 0.80 0.67 93
avg / total 0.81 0.78 0.79 329
python学习
Pandas
pd.read_csv()竟然可以直接请求URL... ...
DataFrame.head()可以查看前面几行的数据,默认是5行
DataFrame.info()可以查看数据的统计情报
DataFrame.to_dict()字典化DF,生成list[dict1,dict2... ...]这样的原生python数据结构,一个字典表示一个行
集成模型程序
本程序对上面的数据同时使用了决策树,随机森林,梯度提升决策树三种方法,程序以及结果对比如下,
'''集成模型'''
import pandas as pd
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
X = titanic[['pclass', 'age', 'sex']]
y = titanic['survived']
X['age'].fillna(X['age'].mean(), inplace=True)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
X_test = vec.transform(X_test.to_dict(orient='record'))
'''决策树'''
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
dtc_y_predict = dtc.predict(X_test)
'''随机森林'''
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
rfc_y_predict = rfc.predict(X_test)
'''梯度提升决策树'''
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier()
gbc.fit(X_train, y_train)
gbc_y_predict = gbc.predict(X_test)
'''模型评估'''
from sklearn.metrics import classification_report
print(dtc.score(X_test, y_test))
print(classification_report(dtc_y_predict, y_test))
print(rfc.score(X_test, y_test))
print(classification_report(rfc_y_predict, y_test))
print(gbc.score(X_test, y_test))
print(classification_report(gbc_y_predict, y_test))
集成模型中的随机森林经常做为用于对比的基准算法而存在。
由于分类器介绍的很多,之后会单拿出一篇来简要介绍一下各个分类器的优劣,以便更好的使用。
『Kaggle』分类任务_决策树&集成模型&DataFrame向量化操作的更多相关文章
- 『TensorFlow』分布式训练_其三_多机分布式
本节中的代码大量使用『TensorFlow』分布式训练_其一_逻辑梳理中介绍的概念,是成熟的多机分布式训练样例 一.基本概念 Cluster.Job.task概念:三者可以简单的看成是层次关系,tas ...
- 『Re』正则表达式模块_常用方法记录
『Re』知识工程作业_主体识别 一个比较完备的正则表达式介绍 几个基础函数 re.compile(pattern, flags=0) 将正则表达式模式编译成一个正则表达式对象,它可以用于匹配使用它的m ...
- 『TensorFlow』分布式训练_其二_单机多GPU并行&GPU模式设定
建议比对『MXNet』第七弹_多GPU并行程序设计 一.tensorflow GPU设置 GPU指定占用 gpu_options = tf.GPUOptions(per_process_gpu_mem ...
- 『PyTorch』第九弹_前馈网络简化写法
『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_下 在前面的例子中,基本上都是将每一层的输出直接作为下一层的 ...
- 『Numpy』内存分析_高级切片和内存数据解析
在计算机中,没有任何数据类型是固定的,完全取决于如何看待这片数据的内存区域. 在numpy.ndarray.view中,提供对内存区域不同的切割方式,来完成数据类型的转换,而无须要对数据进行额外的co ...
- 『TensorFlow』读书笔记_降噪自编码器
『TensorFlow』降噪自编码器设计 之前学习过的代码,又敲了一遍,新的收获也还是有的,因为这次注释写的比较详尽,所以再次记录一下,具体的相关知识查阅之前写的文章即可(见上面链接). # Aut ...
- 『TensorFlow』读书笔记_进阶卷积神经网络_分类cifar10_上
完整项目见:Github 完整项目中最终使用了ResNet进行分类,而卷积版本较本篇中结构为了提升训练效果也略有改动 本节主要介绍进阶的卷积神经网络设计相关,数据读入以及增强在下一节再与介绍 网络相关 ...
- 『TensorFlow』读书笔记_进阶卷积神经网络_分类cifar10_下
数据读取部分实现 文中采用了tensorflow的从文件直接读取数据的方式,逻辑流程如下, 实现如下, # Author : Hellcat # Time : 2017/12/9 import os ...
- 『TensorFlow』读书笔记_多层感知机
多层感知机 输入->线性变换->Relu激活->线性变换->Softmax分类 多层感知机将mnist的结果提升到了98%左右的水平 知识点 过拟合:采用dropout解决,本 ...
随机推荐
- 02: DOM 实例
1.1 Event 对象 <body> <a id="myAnchor" href="http://www.microsoft.com"> ...
- 20145213《网络对抗》逆向及Bof基础
实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包含另一个代码片段,getShe ...
- poj Meteor Shower - 搜索
Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 16313 Accepted: 4291 Description Bess ...
- SPI、CAN、I2C
SPI是串行外设接口(Serial Peripheral Interface)的缩写.SPI,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同时为PCB的布局 ...
- Package libvirt was not found in the pkg-config search path
关于pip安装libvirt-python的时候提示Package libvirt was not found in the pkg-config search path的问题解决方法 1.一开始以为 ...
- vi如何修改注释颜色
答:往~/.vimrc或/etc/vimrc的最后添加以下行: hi comment ctermfg=6
- babun安装,整合到cmder
babun Babun的特性: 预装了Cygwin以及许多的插件 默认的命令行安装工具,没有管理员权限要求. 预装了 pact工具,一个高级的包管理器,类似 apt-get或yum xTerm-256 ...
- 打印图形|2014年蓝桥杯B组题解析第五题-fishers
打印图形 小明在X星球的城堡中发现了如下图形和文字: rank=3 rank=5 rank = 6 小明开动脑筋,编写了如下的程序,实现该图形的打印. 答案:f(a, rank-1, row, col ...
- 【基础知识】ActiveMQ基本原理
“来,根据你的了解说下 ActiveMQ 是什么.” “这个简单,ActiveMQ 是一个 MOM,具体来说是一个实现了 JMS 规范的系统间远程通信的消息代理.它……” “等等,先解释下什么是 MO ...
- PTA第一次作业
5-5 #include <cstdio> #include <iostream> #include <cstdlib> using namespace std; ...