python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
2,
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""";
soup = BeautifulSoup(html_doc);
print(soup.prettify())
1)soup.prettify()的作用是把html格式化输出
2)在输出是会发出警告:No parser was explicitly specified, so I'm using the best available HTML parser for this system。这是因为没有解析器。所以需要安装解析器。如下图:
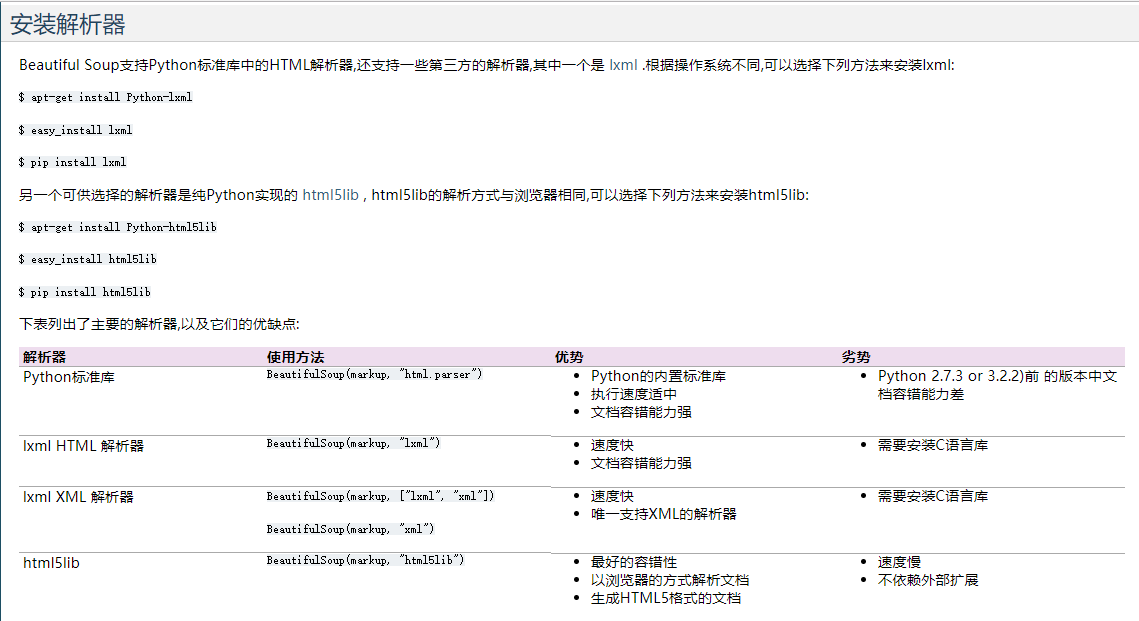
3)soup = BeautifulSoup(html_doc,"html.parser");//这个就可以加入解析器
print(soup.prettify())
4)soup.title #获取title内容<title>The Dormouse's story</title>
soup.标签名 #获取对应的标签。(系统当前第一个)
soup.find_all('a') #打印出所有‘a’标签 返回的是一个数组
soup.find(id="link3") #打印出对应id页面
for link in soup.find_all('a'): #这个用来遍历
print(link.get('id'))
#在遍历class时候返回的是一个数组
print(link.get('class'))
#['sister1']
#['sister2']
#['sister3']
soup.get_text() #这个是用来获取所有的文字
soup.find('p',{'class':'story'})) #这个里面是获取p标签下的class=story所有信息 注:这里因为class是关键字所以不能使用find('class':'story')
soup.find('p',{'class':'story'}).string) # 结果为none
5)可以通过政策表达式来 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和<b>标签都应该被找到:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
(5.1),python的正则表达式
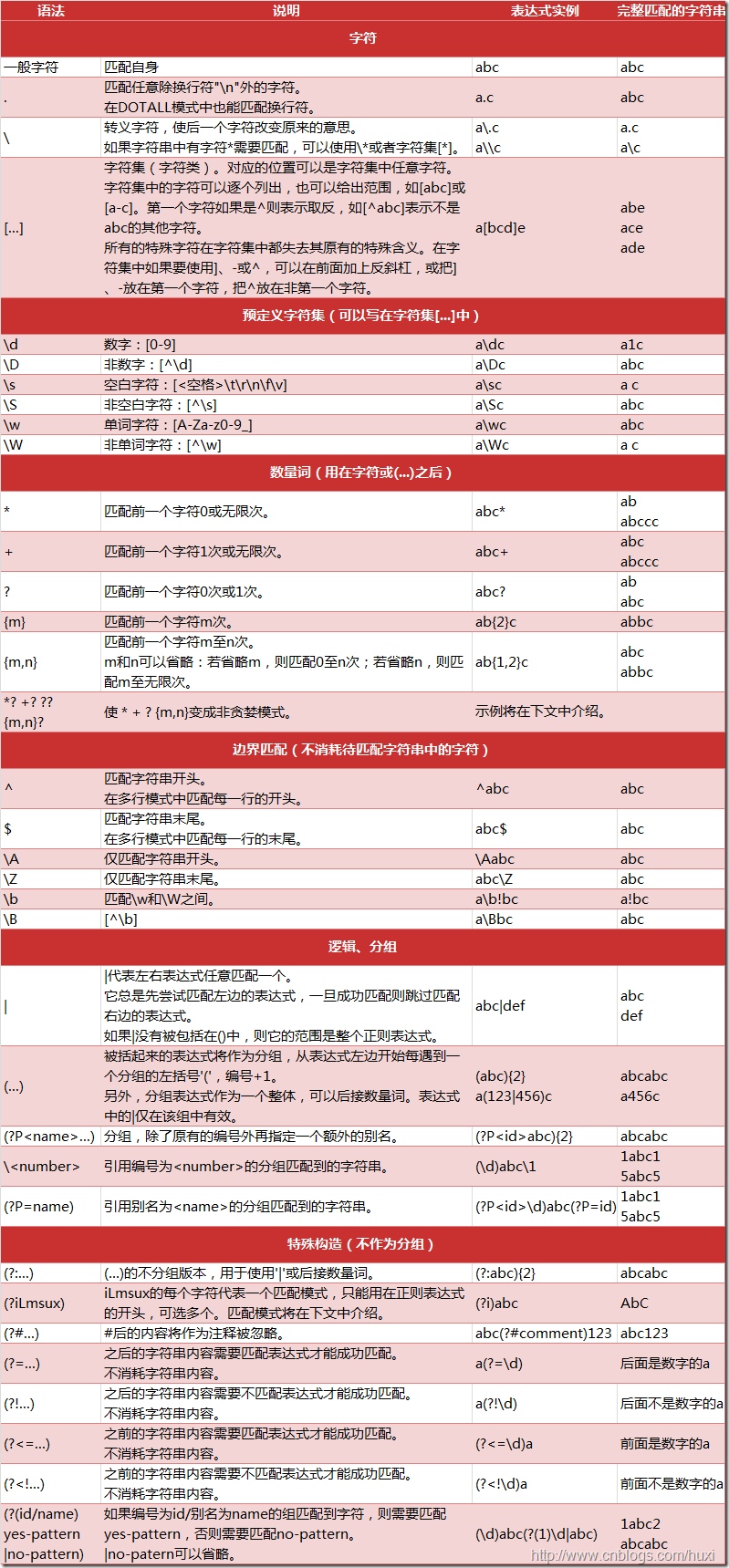
(注:图片来源https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html)
python爬虫入门--beautifulsoup的更多相关文章
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫入门-开发环境与小例子
python爬虫入门 开发环境 ubuntu 16.04 sublime pycharm requests库 requests库安装: sudo pip install requests 第一个例子 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- LeetCode 104. Maximum Depth of Binary Tree (二叉树的最大深度)
Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the long ...
- AI翻译离无障碍交流有多远
AI翻译服务通过硬件.软件连接千千万万个应用场景,会打破语言不通的尴尬局面吗?会是人工翻译的终结者吗? 世界这么大,我想去看看!十一长假临近,梦想中的你背起行囊,自由行走在异国的大街小巷.然而现实的画 ...
- 关于在Python下安装布隆过滤器(bloomfilter)的方法
由于在爬虫代码中需要实现信息的去重功能,所以需借助bloomfilter,在看完各种博客后发现没有安装,这就尴尬了,不会连门都找不到吧.那就安装呗,各种错误,查看官方文档:http://axiak.g ...
- HDU1150 Machine Schedule(二分图最大匹配、最小点覆盖)
As we all know, machine scheduling is a very classical problem in computer science and has been stud ...
- python字典学习笔记
字典是一种可变容器模型,且可存储任意类型对象.键是不可变类型(且是唯一的),值可以是任意类型(不可变类型:整型,字符串,元组:可变类型:列表,字典).字典是无序的,没有顺序关系,访问字典中的键值是通过 ...
- $.grep()函数
定义和用法 $.grep() 函数使用指定的函数过滤数组中的元素,并返回过滤后的数组. 提示:源数组不会受到影响,过滤结果只反映在返回的结果数组中. 语法 $.grep( array, functio ...
- .NET项目从CI到CD-Jenkins_Pipeline的应用
一.罗里吧嗦 最近迁移了服务器,顺道完善下服役了一两年的Jenkins服务,主要是把Slave搭建起来,还有等等.本文只是我对Jenkins Pipeline的一些自己的理解与应用,欢迎指出错误,欢迎 ...
- [转]移动前端开发之viewport的深入理解
今天去面试,被问到一个用了一万次的东西,然而我并不了解具体是个毛毛,看这一篇豁然开朗. DevicePixelRatio 以及这句话:移动设备上的viewport分为layout viewport ...
- JavaScript系列----AJAX机制详解以及跨域通信
1.Ajax 1.1.Ajax简介 Ajax简介这一部分我们主要是谈一下ajax的起源,ajax是什么?因为这些是跟技术无关的.所以,大多细节都是一笔带过. Ajax的起源? Ajax一词源于2005 ...
- Hibernate开发文档
hibernate配置 映射约束文件 <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3. ...