python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
2,
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""";
soup = BeautifulSoup(html_doc);
print(soup.prettify())
1)soup.prettify()的作用是把html格式化输出
2)在输出是会发出警告:No parser was explicitly specified, so I'm using the best available HTML parser for this system。这是因为没有解析器。所以需要安装解析器。如下图:
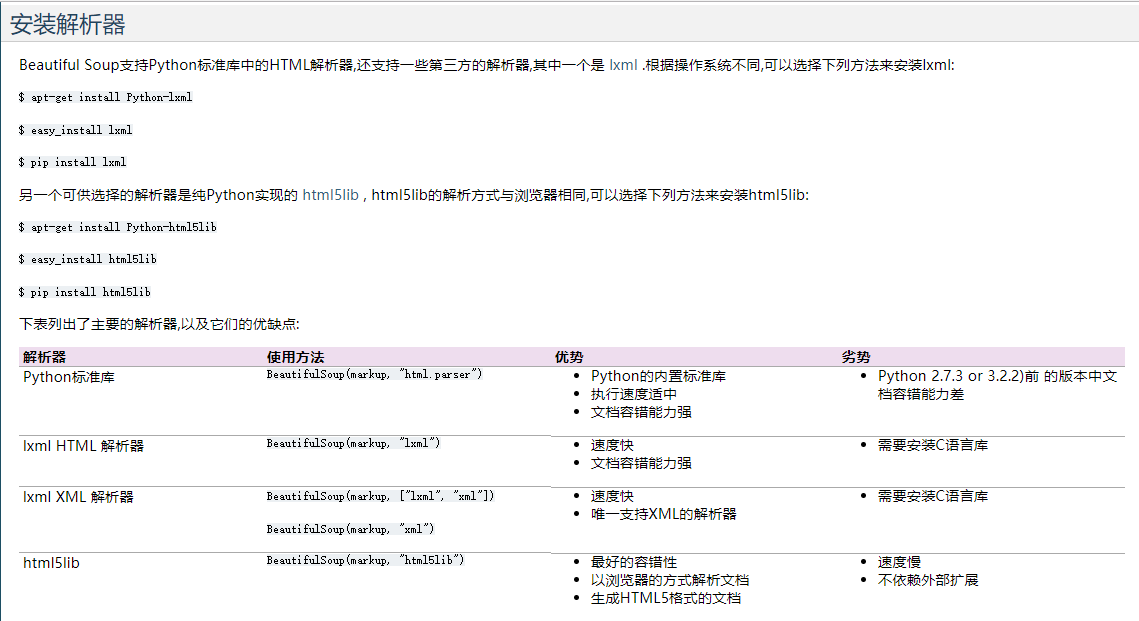
3)soup = BeautifulSoup(html_doc,"html.parser");//这个就可以加入解析器
print(soup.prettify())
4)soup.title #获取title内容<title>The Dormouse's story</title>
soup.标签名 #获取对应的标签。(系统当前第一个)
soup.find_all('a') #打印出所有‘a’标签 返回的是一个数组
soup.find(id="link3") #打印出对应id页面
for link in soup.find_all('a'): #这个用来遍历
print(link.get('id'))
#在遍历class时候返回的是一个数组
print(link.get('class'))
#['sister1']
#['sister2']
#['sister3']
soup.get_text() #这个是用来获取所有的文字
soup.find('p',{'class':'story'})) #这个里面是获取p标签下的class=story所有信息 注:这里因为class是关键字所以不能使用find('class':'story')
soup.find('p',{'class':'story'}).string) # 结果为none
5)可以通过政策表达式来 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和<b>标签都应该被找到:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
(5.1),python的正则表达式
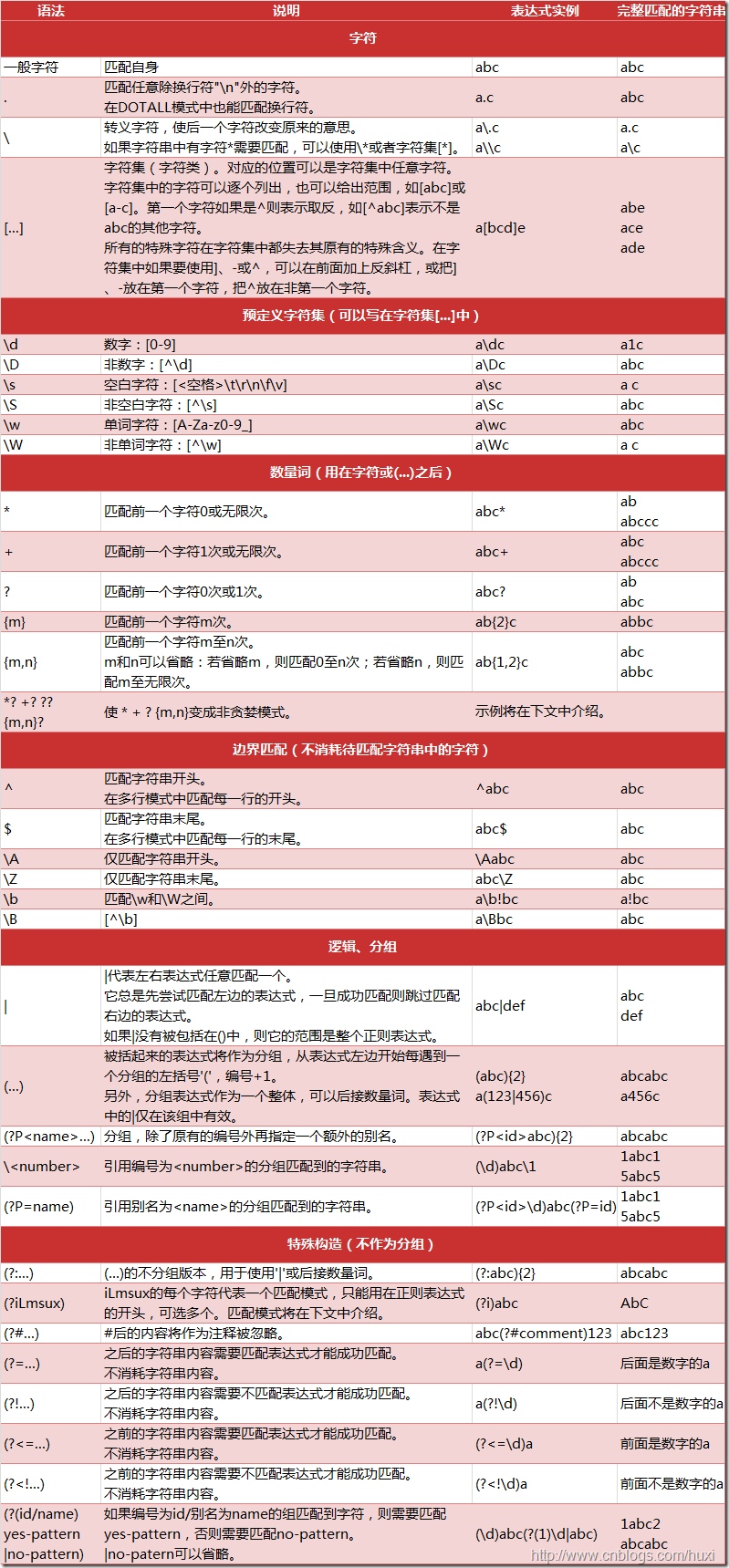
(注:图片来源https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html)
python爬虫入门--beautifulsoup的更多相关文章
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫入门-开发环境与小例子
python爬虫入门 开发环境 ubuntu 16.04 sublime pycharm requests库 requests库安装: sudo pip install requests 第一个例子 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- V6厂最新V4版本卡地亚蓝气球大号42mm男表|价格报价|
大家好!为大家带来一款贵族气质的V6厂卡地亚蓝气球大号42mm男表!众所周知卡地亚品牌给人的印象是非常尊贵.奢华的,而且卡地亚蓝气球系列的表款都有着极高的识别度,而且每一款都是极受欢迎的热门腕表,接下 ...
- js 两个日期比较相差多少天
var day1 = new Date("2017-9-17"); var day2 = new Date("2017-10-18"); console.log ...
- 深入理解JavaScript中的继承:原型链篇
一.何为原型链 原型是一个对象,当我调用一个对象的方法时,如果该方法没有在对象里面,就会从对象的原型去寻找.JavaScript就是通过层层的原型,形成原型链. 二.谁拥有原型 任何对象都可以有原型, ...
- 【经验分享】Trachtenberg system(特拉亨伯格速算系统)
二战期间,俄国的数学家Jakow Trachtenberg(1888-1953)被关进纳粹集中营,在狱中,他开发出了一套心算算法,这套算法后来被命名为Trachtenberg(特拉亨伯格)速算系统. ...
- Windows系统下python3中安装pyMysql
python2和python3是不兼容的,在py2中,链接数据库使用的是mysqldb,但在py3中是不能用的. 解决办法就是在py3中数据库使用的模块是pyMysql. 在dos窗口中安装第三方库会 ...
- windows系统扩展C盘的工具推荐(解决了C盘和压缩卷不相邻无法扩展C盘问题)
1.下载分区工具 “分区助手3.0中文版” 下载地址:http://www.33lc.com/soft/14880.html 2.下载下来是一个压缩包,解压后运行安装程序. 3.安装完成后按以下步骤执 ...
- Maven 浅谈一
一.Maven的作用 在开发中,为了保证编译通过,我们会到处去寻找jar包,当编译通过了,运行的时候,却发现"ClassNotFoundException",我们想到的是,难道还差 ...
- python 小白(无编程基础,无计算机基础)的开发之路 day1
本节内容 Python介绍 发展史 Python 2 or 3? 安装 Hello World程序 变量 用户输入 模块初识 .pyc是个什么鬼? 数据类型初识 数据运算 表达式if ...else语 ...
- Velocity(1)——初步入门
1.变量 (1)变量的定义: 1 #set($name = "hello") 说明:velocity中变量是弱类型的. 2 3 当使用#set 指令时,括在双引号中的字面字符串将解 ...
- Django总结
Django 中提供了开发网站经常用到的模块,常见的代码都为你写好了,通过减少重复的代码,Django 使你能够专注于 web 应用上有 趣的关键性的东西.为了达到这个目标,Django 提供了通用W ...