一次对象过大引起的gc性能问题的分析与定位
现象:一个接口在4C的机器上跑最大只有7TPS,CPU使用率就已经90%多。
定位:
1、 使用top命令查看CPU使用情况,找到进程号
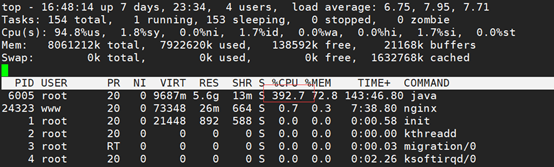
2、 使用top -H -pid命令,查看进程信息,看到有四个进程CPU占用很高,加一起已经超过100%:
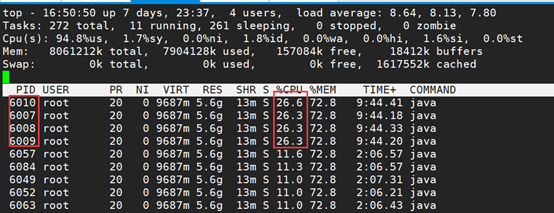
3、 查看具体的线程信息,先使用printf "%x\n" 6007,将线程ip转换成16进制,结果为1777。
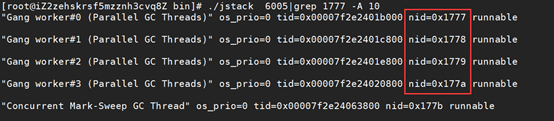
4、使用jstack pid |grep pid 命令,查看具体的线程信息,打印结果发现是GC线程,对四个占用CPU高的线程逐一分析,发现刚好都是下面的四个线程,至此,初步定位性能问题是有GC引起的。
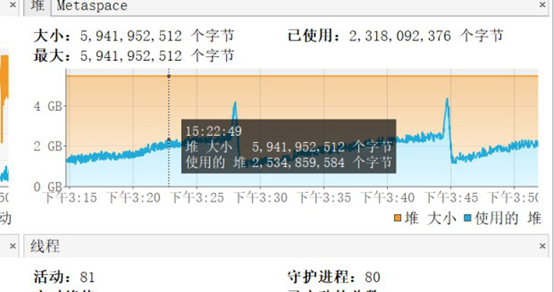
5、 配置好java visualvm ,查看GC情况,结果如下,FULL GC不存在问题,不存在内存泄漏问题,把问题缩小到年轻代。
6、 使用jstat -gcutil pid命令,查看具体gc信息,发现Eden区大概5s会满一次。
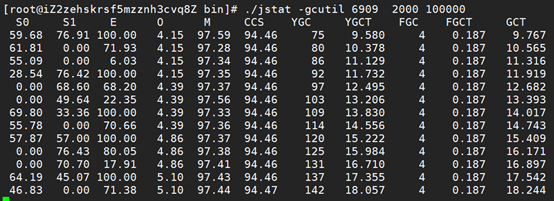
7、 查看gc日志,看到minor gc频率跟高,关键是一次minor gc的时间很长,用户耗时达到了500多ms,一般几毫米,最高几十毫秒正常,至此,基本把问题定位到是有minor gc,性能问题是由于minor gc太频繁且耗时长造成的,初步猜测两个原因,一是由于Eden区过小,另一个是由于对象过大,先从简单的排查,加大Eden区看看:

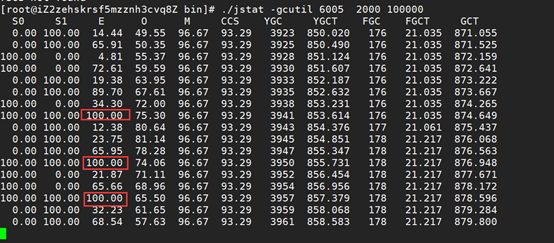
8、查看JVM配置,关系到年轻代的信息基本上就是这几个参数,发现Eden配置的确实小,而且垃圾的时间有点长,感觉开发配置的不太合理,所以去掉了后面三JVM参数,使用默认设置,重启服务,使配置生效:

9、重启完后,再次使用jstat命令,发现gc频率降低了一半,但悲剧的是,gc的时间翻了一倍,TPS依然没变,至此确实和JVM配置无关,需要关注对象大小。

10、查看线程信息,找到部署相关的项目,定位到具体的方法:

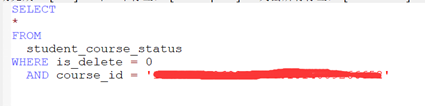
11、找到代码,是一个select操作,返回的是select的结果:

12、继续定位到具体的SQL:
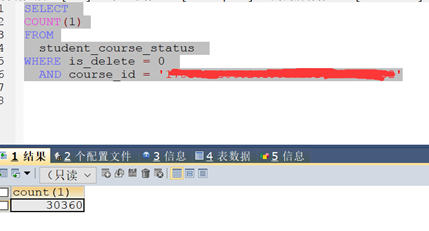
13、查看这个SQL返回的结果,有三万多条,至此基本确定问题所在,返回的list过大,导致Eden区很快就满,而且回收缓慢,造成垃圾回收出现问题,同时FC占用大量CPU,导致CPU使用过高,最终就出现了看见的TPS只有7,CPU就满了的问题。
总结:因为性能测试数据是我们自己造的,第一反应是我们造的数据有问题,再次确认后,发现我们数据没问题,这个查询的where条件传的是课次信息,一个课次有几万学生属于正常数据。正常情况下查这个表时会同时带上学生id,这样的结果不会超过十条,不会存在问题。但是开发为了方便,调用了之前的方法,结果就出现了这样的问题。
一次对象过大引起的gc性能问题的分析与定位的更多相关文章
- [翻译] 编写高性能 .NET 代码--第二章 GC -- 将长生命周期对象和大对象池化
将长生命周期对象和大对象池化 请记住最开始说的原则:对象要么立即回收要么一直存在.它们要么在0代被回收,要么在2代里一直存在.有些对象本质是静态的,生命周期从它们被创建开始,到程序停止才会结束.其它对 ...
- android app性能优化大汇总(内存性能优化)
转载请注明本文出自大苞米的博客(http://blog.csdn.net/a396901990),谢谢支持! 写在最前: 本文的思路主要借鉴了2014年AnDevCon开发者大会的一个演讲PPT,加上 ...
- JAVA GC垃圾收集器的分析
本篇文章主要介绍了"JAVA GC垃圾收集器的分析",主要涉及到JAVA GC垃圾收集器的分析方面的内容,对于JAVA GC垃圾收集器的分析感兴趣的同学可以参考一下. ...
- Java GC性能优化实战
GC优化是必要的吗? 或者更准确地说,GC优化对Java基础服务来说是必要的吗?答案是否定的,事实上GC优化对Java基础服务来说在有些场合是可以省去的,但前提是这些正在运行的Java系统,必须包含以 ...
- 【大数据】Spark性能优化和故障处理
第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的, ...
- Java 虚拟机 - GC 垃圾回收机制分析
Java 垃圾回收(Garbage Collection,GC) Java支持内存动态分配.垃圾自动回收,而 C++ 不支持.我想这可能也是 为什么 Java 脱胎于 C++ 的一个原因吧. GC 的 ...
- java读大文件最快性能【转】
java读大文件最快性能 完全引用自: 几种读大文件方法的效率对比测试 据说1.88g只要5秒左右,未亲测. /** * 读大文件 * BufferedReader + char[] * @throw ...
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师.架构师粟迪夫的案例分享. 编辑:Cynthia 粟迪夫:WalmartLabs实验室广告平台首席工程师 ...
- EF大数据批量添加性能问题(续)
昨天在园子里发了一篇如题的文章EF大数据批量添加性能问题,就引来一大堆的吐槽,我认为知识就应该这样分享出来,不然总以为自己很了不起:再说说昨天那篇文章,很多自认为很牛逼的人都评论说把SaveChang ...
随机推荐
- 使用JavaMail发送带附件的邮件
所需jar包 链接:http://pan.baidu.com/s/1dFo4cDz 密码:akap 工具类: package com.javamail.utils; import java.util. ...
- Maven3 快速入门
Maven3 快速入门 Maven 是目前大型项目构建的必备知识.本章会通过介绍 Maven 的作用,Maven 的基本语法,以及搭建企业级项目架构来快速入门 Maven .前两部分是理论知识只需要了 ...
- Database differential backup差异备份和还原
完整备份: 备份全部选中的文件和文件夹,并不依赖文件的存档属性来确定备份哪些文件.(在备份过程中,任何现有的标记都被清除,每个文件都被标记为已备份,换言之,清除存档属性),完全备份也叫完整备份. 差异 ...
- npoi导入导出
NPOI是指构建在POI 3.x版本之上的一个程序,NPOI可以在没有安装Office的情况下对Word或Excel文档进行读写操作. NPOI是一个开源的Java读写Excel.WORD等微软OLE ...
- PHP时间戳和日期互转换
在php中我们要把时间戳转换日期可以直接使用date函数来实现,如果要把日期转换成时间戳可以使用strtotime()函数实现,下面我来给大家举例说明. 1.php中时间转换函数 strtotime ...
- mysql插入测试数据
使用php生成sql文件,然后再倒入mysql. 1.编写php代码 <?php set_time_limit(0); ini_set("memory_limit", &qu ...
- 认识 Less
CSS(层叠样式表)是一项出色的技术,它使得网页的表现与内容完全分离,使网站维护工作变得更容易,不会因为内容的改变而影响表现,也不会因为表现的改变而影响内容. 作为一门标记性语言,CSS 的先天性优点 ...
- Android截屏的几种实现
Android截屏的几种实现 微信公众号:CodingAndroid CSDN:http://blog.csdn.net/xinpengfei521 最近我们的APP要求需要截屏功能,网上看了看大致有 ...
- vue+echarts 动态绘制图表以及异步加载数据
前言 背景:vue写的后台管理,需要将表格数据绘制成图表(折线图,柱状图),图表数据都是通过接口请求回来的. 安装 cnpm install echarts --s (我这里用了淘宝镜像,不知道同学自 ...
- Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十一)redis密码设置、安全设置
警惕 前一篇文章<Spring+SpringMVC+MyBatis+easyUI整合进阶篇(九)Linux下安装redis及redis的常用命令和操作>主要是一个简单的介绍,针对redis ...