深入理解计算机系统_3e 第六章家庭作业 CS:APP3e chapter 6 homework
**6.22**
假设磁道沿半径均匀分布,即总磁道数和(1-x)r成正比,设磁道数为(1-x)rk;
由题单个磁道的位数和周长成正比,即和半径xr成正比,设单个磁道的位数为xrz;
其中r、k、z均为常数。
所以C = (1-x)rk * xrz = (-x^2 + x) * r^2 * kz,即需要-x^2 + x最大,得到x = 0.5。
6.23
seek time : 4 ms
average rotational latency : 0.5 * 60 / 15000 * 1000 = 2 ms
transfer time : 60 / 15000 / 800 * 1000= 0.005 ms
4 + 2 + 0.005 = 6.005 ms
6.24
A.
2MB = 512 bytes * 4096,即需要读取4096个扇区。
定位时间为:4 + 0.5*60/15000*1000 = 6 ms
最理想的情况下,这4096个扇区都在一个柱面上(一个磁道读完后继续读下一个,磁头不用移动),也就是4096/1000 = 5个磁道。
即transfer time = 4096 / 1000 * 60 / 15000 * 1000 = 16.384 ms
所以理想时间为:6 + 16.384 = 22.384 ms
B.
2MB = 512 bytes * 4096,即需要读取4096个扇区。
定位时间为:4 + 0.5*60/15000*1000 = 6 ms
在完全随机的情况下,这4096个扇区分布在不同的磁道上,每一个扇区读完以后磁头都要再次去定位。
所以总的时间为:6 * 4096 + transfer time = 24592.384 ms (这里书上有一个类似的题目,但是没有加上transfer time ,我觉得还是要加上)
6.25
S t s b
1. 64 24 6 2
2. 1 30 0 2
3. 128 22 7 3
4. 1 29 0 3
5. 32 22 5 5
6. 8 24 3 5
6.26
m C B E S t s b
1. 2048 256
2. 4 4
3. 25 6
4. 32 5
6.27
A.
0x08A4 0x08A5 0x08A6 0x08A7
0x0704 0x0705 0x0706 0x0707
B.
0x1238 0x1239 0x123A 0x123B
6.28
A.
None
B.
0x18F0 0x18F1 0x18F2 0x18F3
0x00B0 0x00B1 0x00B2 0x00B3
C.
0x0E34 0x0E35 0x0E36 0x0E37
D.
0x1BDC 0x1BDD 0x1BDE 0x1BDF
6.29
A.
CTCTCTCTCTCTCTCT, CICI, COCO
B.
Hit? Read value(or unknown)
N -
Y unknown
Y 0xC0
6.30
A.
C = S * E * B = 128 Bytes
B.
CTCTCTCTCTCTCTCT, CICICI, COCO
6.31
A.
00111000, 110, 10
B.
CO 0x2
CI 0x6
CT 0x38
Cache hit? Y
Cache byte returned 0xEB
6.32
A.
10110111, 010, 00
B.
CO 0x0
CI 0x2
CT 0xB7
Cache hit? N
Cache byte returned -
6.33
0x1788 0x1789 0x178A 0x178B
0x16C8 0x16C9 0x16CA 0x16CB
6.34
cache共有两个block,分别位于两个set中,设他们为b1和b2。每个block可以放下4个int类型的变量,也就是数组中的一行。在这一题中,源数组和目的数组是相邻排列的。所以内存和cache的映射情况是这样的:
b1 : src[0][] src[2][] dst[0][] dst[2][]
b2 : src[1][] src[3][] dst[1][] dst[3][]
dst array src array
Col.0 Col.1 Col.2 Col.3 Col.0 Col.1 Col.2 Col.3
Row0 m m h m m m m m
Row1 m h m h m m m m
Row2 m m h m m m m m
Row3 m h m h m m m m
6.35
cache共有八个block,分别位于八个set中,设他们为b1、b2、b3、b4、b5、b6、b7、b8。每个block可以放下4个int类型的变量,也就是数组中的一行。在这一题中,源数组和目的数组是相邻排列的。所以内存和cache的映射情况是这样的:(这时不会有冲突)
b1 : src[0][]
b2 : src[1][]
b3 : src[2][]
b4 : src[3][]
b5 : dst[0][]
b6 : dst[1][]
b7 : dst[2][]
b8 : dst[3][]
dst array src array
Col.0 Col.1 Col.2 Col.3 Col.0 Col.1 Col.2 Col.3
Row0 m h h h m h h h
Row1 m h h h m h h h
Row2 m h h h m h h h
Row3 m h h h m h h h
6.36
A.
cache共有32个block,分别位于32个set中,每个block可以放下4个int类型的变量,所以所有的block可以放下x数组中的一行。由映射关系,x[0][i]和x[1][i]对应的set是一样的。所以每一次的运算都会发生miss的情况,所以miss rate = 100%。
B.
cache共有64个block,分别位于64个set中,每个block可以放下4个int类型的变量,所以所有的block可以放下x数组中的两行,即全部放入。每四次读取中的第一次会发生miss,所以miss rate = 25%。
C.
cache共有32个block,分别位于16个set中,每个block可以放下4个int类型的变量,每个set可以放下8个int类型的变量,所有的block可以放下x数组中的一行。由映射关系,x[0][i]和x[1][i]对应的set是一样的,x[y][i]和x[y][i+64]对应的set也是一样的。
对于x[0][0] * x[1][0] ~ x[0][63] * x[1][63] ,每四次运算会有第一次miss。
对于x[0][64] * x[1][64] ~ x[0][127] * x[1][127] ,每四次运算会有第一次miss(擦去前面warm up的cache)。
综上,miss rate = 25%。
D.
不会,因为此时block大小是限制因素(每四次读取第一次miss)。
E.
会,更大的block会降低miss rate,因为miss只发生在第一次读入block的时候,所以更大的block会使得miss占总读取的比例降低。
6.37
cache共有256个block,分别位于256个set中,每个block可以放下4个int类型的变量,所有的block可以放下1024个int类型的变量。
当N = 64:
映射关系:a[0][0] ~ a[15][63]、a[16][0] ~ a[31][63]、a[32][0] ~ a[47][63]、a[48][0] ~ a[63][63] 互相重叠。
sumA按照行来读取,所以每四次读取第一次都会miss,即miss rate = 25%。
sumB按照列来读取,所以每一次读取都会发生miss(读取后的block又会被覆盖),即miss rate = 100%。
sumC按照列来读取,但是每次读取后都会按照行再读取一次,所以每四次读取会有两次miss,即miss rate = 50%。
当N = 60
映射关系:a[0][0] ~ a[17][3]、a[17][4] ~ a[34][7]、a[34][8] ~ a[51][11]、a[51][12] ~ a[59][59]互相重叠,其中最后的a[51][12] ~ a[59][59]没有到达cache的尾部。
sumA按照行来读取,所以每四次读取第一次都会miss,即miss rate = 25%。
sumB按照列来读取,这里的情况有些复杂,我写了一个程序来分析:
#include <stdio.h>
#define SIZEOFCACHE 256
#define SIZEOFBLOCK 4
#define N 60
int main()
{
int cache[SIZEOFCACHE];
for (int k = 0; k < SIZEOFCACHE; ++k)
{
cache[k] = -1;
}
int read = 0;
int miss = 0;
for (int j = 0; j < N; ++j)
{
for (int i = 0; i < N; ++i)
{
//read a[i][j]
++read;
int position = i * N + j;
int need_start = position/SIZEOFBLOCK;
if (cache[need_start%SIZEOFCACHE] != need_start)
{
++miss;
cache[need_start%SIZEOFCACHE] = need_start;
}
}
}
printf("%g\n", miss/(double)read);
return 0;
}
输出结果为25%。
C.
将上面程序的循环部分更改为:
for (int j = 0; j < N; j+=2)
{
for (int i = 0; i < N; i+=2)
{
//read a[i][j] a[i+1][j] a[i][j+1] a[i+1][j+1]
++read;
int position = i * N + j;
int need_start = position/SIZEOFBLOCK;
if (cache[need_start%SIZEOFCACHE] != need_start)
{
++miss;
cache[need_start%SIZEOFCACHE] = need_start;
}
++read;
position = (i+1) * N + j;
need_start = position/SIZEOFBLOCK;
if (cache[need_start%SIZEOFCACHE] != need_start)
{
++miss;
cache[need_start%SIZEOFCACHE] = need_start;
}
++read;
position = i * N + j + 1;
need_start = position/SIZEOFBLOCK;
if (cache[need_start%SIZEOFCACHE] != need_start)
{
++miss;
cache[need_start%SIZEOFCACHE] = need_start;
}
++read;
position = (i+1) * N + j + 1;
need_start = position/SIZEOFBLOCK;
if (cache[need_start%SIZEOFCACHE] != need_start)
{
++miss;
cache[need_start%SIZEOFCACHE] = need_start;
}
}
}
输出结果为25%。
6.38
这个cache有64个block,每个block可以放4个int类型的变量,也就是一个point_color的结构体,即cache总共可以放置64个结构体。
映射关系为:square[0][0] ~ square[3][15]、square[4][0] ~ square[7][15]、square[8][0] ~ square[11][15]、square[12][0] ~ square[15][15] 互相重叠。
A.
16 * 16 * 4 = 1024
B.
这个程序是按照行来写的,所以每四次写入只有第一次miss,即miss的次数为1024 / 4 = 256
C.
25%
6.39
这个cache有64个block,每个block可以放4个int类型的变量,也就是一个point_color的结构体,即cache总共可以放置64个结构体。
映射关系为:square[0][0] ~ square[3][15]、square[4][0] ~ square[7][15]、square[8][0] ~ square[11][15]、square[12][0] ~ square[15][15] 互相重叠。
A.
16 * 16 * 4 = 1024
B.
这个程序是按照列来写的,每四次写入只有第一次miss(每次都完整利用了一个block,没有读入block的浪费,此时miss rate只取决于block的大小),即miss的次数为1024 / 4 = 256
C.
25%
6.40
这个cache有64个block,每个block可以放4个int类型的变量,也就是一个point_color的结构体,即cache总共可以放置64个结构体。
映射关系为:square[0][0] ~ square[3][15]、square[4][0] ~ square[7][15]、square[8][0] ~ square[11][15]、square[12][0] ~ square[15][15] 互相重叠。
A.
16 * 16 + 3 * 16 * 16 = 1024
B.
对于第一个循环,每一次写入都会发生miss的情况,最后cache中保存的是square[12][0] ~ square[15][15],而第二个循环又从头开始写入,所以每三次写入的第一次都会发生miss。总的miss次数就是16 * 16 * 2 = 512。
C.
50%
6.41
这个cache有16K个block,每个block可以放4个char类型的变量,也就是一个pixel的结构体,即cache总共可以放置16K个结构体。buffer里面一共有480 * 640 = 300K个结构体,所以映射时会有18个完全重叠的,最后一次重叠3/4.
这个程序按照列来写,每四次写入只有第一次miss(每次都完整利用了一个block,没有读入block的浪费,此时miss rate只取决于block的大小),所以miss rate = 25%。
6.42
这个cache有16K个block,每个block可以放4个char类型的变量,也就是一个pixel的结构体,即cache总共可以放置16K个结构体。buffer里面一共有480 * 640 = 300K个结构体,所以映射时会有18个完全重叠的,最后一次重叠3/4.
这个程序实际上就是按照行来写的指针版本,每四次写入只有第一次miss,miss rate = 25%。
6.43
这个cache有16K个block,每个block可以放4个char类型的变量,也就是一个pixel的结构体,即cache总共可以放置16K个结构体。buffer里面一共有480 * 640 = 300K个结构体,所以映射时会有18个完全重叠的,最后一次重叠3/4.
这个程序实际上还是按照行来写的指针版本,但是只写了buffer数组的1/4。每四次写入只有第一次miss,miss rate = 25%。
6.44
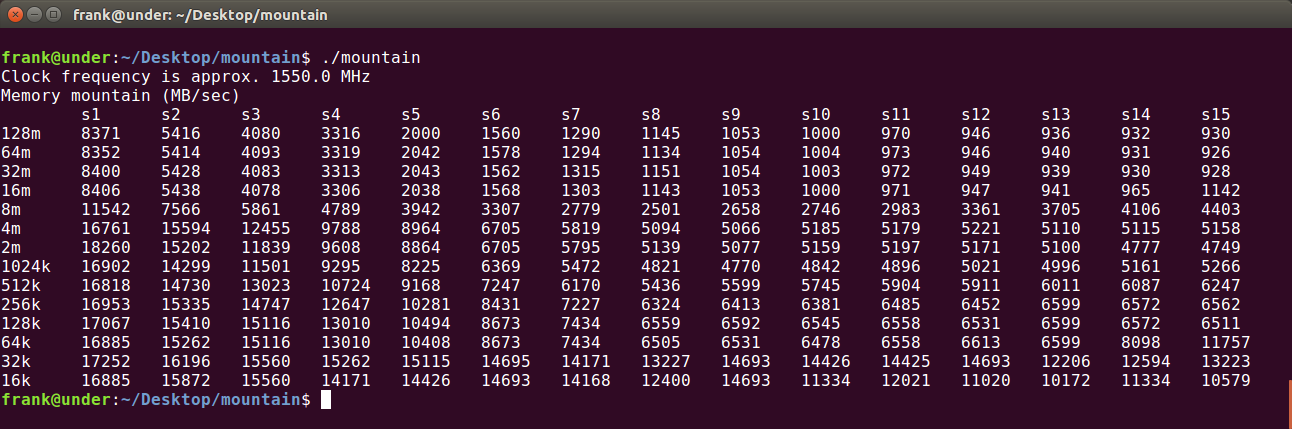
为了辨识缓存的大小,选取中间的列(例如S8)来判断——避免CPU的prefetching带来干扰。可以看出,在32K和512K以及8M的地方有明显的落差,所以判断L1:32k、L2:512k、L3:8M。
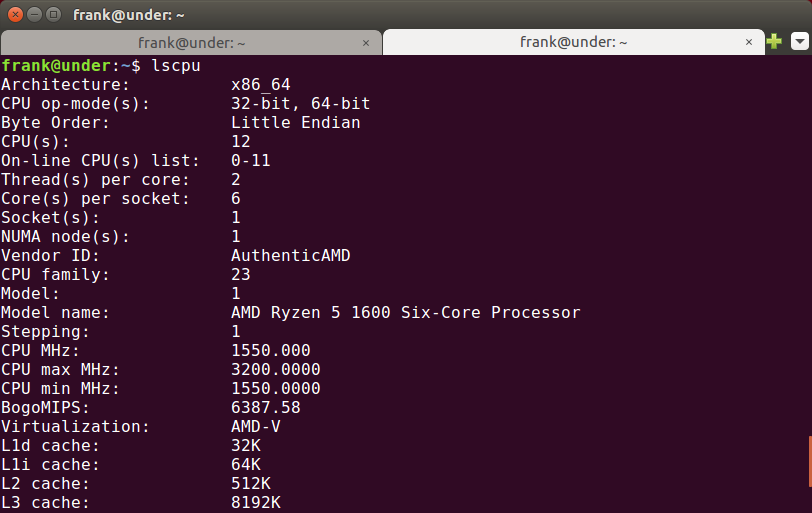
用lscpu验证分析正确:
6.45
这个题要求我们利用第5章和第6章中学到的优化知识。对于第5章,就是减少循环的数据依赖,从而利用流水线并行执行;对于第6章,则是从两个方面(temporary、spatial)利用数据的“本地性”。
void transpose(int *dst, int *src, int dim)
{
int i, j;
for (i = 0; i < dim; ++i)
{
for (j = 0; j < dim; ++j)
{
dst[j*dim + i] = src[i*dim +j] /* ! */
}
}
}
以上的关键语句中的乘法和加法已经实现了循环之间独立,src也是按照行读入的,但是dst却是按照列读入的,这样没有充分利用每一次读入的block。于是我们想到可不可以每一次读入dst[j*dim + i]所在的block之后继续写入例如dst[j*dim + i + 1] dst[j*dim + i + 2]这样的变量,但是这样有需要src的部分变为src[(i+1)*dim +j]等等,所以我们现在不仅要“横向”扩展dst,还要“纵向”扩展src,其实这是一种叫做blocking的技术,即每次读入一块数据,对此块数据完全利用后抛弃,然后读取下一个块。可以参考csapp网上给的注解:MEM:BLOCKING — Using blocking to increase temporal locality
设我们的数据块的宽度是B,由于我们要对两个数组进行读写操作,所以2B^2 < C(其中C是cache的容量),在此限制下B尽可能取大。
#define B chunkdatas_length_of_side
void faster_transpose(int *dst, int *src, int dim)
{
long limit = dim * dim;
for (int i = 0; i < dim; i += B)
{
for (int j = 0; j < dim; j += B)
{
/* Using blocking to improve temporal locality */
for (int k = i; k < i+B; ++k)
{
for (int l = j; l < j+B; ++l)
{
/* independent calculations */
int d = l*dim + k;
int s = k*dim + l;
if (s < limit && d < limit)
{
dst[d] = src[s]
}
}
}
}
}
}
6.46
这个题仅仅是6.45的一个实践版。但这个题有一个小技巧,就是G[d] || G[s]这个运算对于G[d]和G[s]都是一样的,所以只用计算一次,从而我们只用计算对角线的上半部分的内容,也就是第二外层循环的j不用从0而是从最外层循环的i开始。
#define B chunkdatas_length_of_side
void faster_col_convert(int *G, int dim)
{
long limit = dim * dim;
for (int i = 0; i < dim; i += B)
{
for (int j = i; j < dim; j += B)
{
/* Using blocking to improve temporal locality */
for (int k = i; k < i+B; ++k)
{
for (int l = j; l < j+B; ++l)
{
/* independent calculations */
int d = l*dim + k;
int s = k*dim + l;
if (s < limit && d < limit)
{
_Bool temp = G[d] || G[s];
G[d] = temp;
G[s] = temp;
}
}
}
}
}
}
深入理解计算机系统_3e 第六章家庭作业 CS:APP3e chapter 6 homework的更多相关文章
- 深入理解计算机系统_3e 第十一章家庭作业 CS:APP3e chapter 11 homework
注:tiny.c csapp.c csapp.h等示例代码均可在Code Examples获取 11.6 A. 书上写的示例代码已经完成了大部分工作:doit函数中的printf("%s&q ...
- 深入理解计算机系统_3e 第七章家庭作业 CS:APP3e chapter 7 homework
7.6 +-----------------------------------------------------------------------+ |Symbol entry? Symbol ...
- 深入理解计算机系统_3e 第五章家庭作业 CS:APP3e chapter 5 homework
5.13 A. B. 由浮点数加法的延迟,CPE的下界应该是3. C. 由整数加法的延迟,CPE的下界应该是1. D. 由A中的数据流图,虽然浮点数乘法需要5个周期,但是它没有"数据依赖&q ...
- 深入理解计算机系统_3e 第三章家庭作业 CS:APP3e chapter 3 homework
3.58 long decode2(long x, long y, long z) { int result = x * (y - z); if((y - z) & 1) result = ~ ...
- 深入理解计算机系统_3e 第九章家庭作业 CS:APP3e chapter 9 homework
9.11 A. 00001001 111100 B. +----------------------------+ | Parameter Value | +--------------------- ...
- 深入理解计算机系统_3e 第二章家庭作业 CS:APP3e chapter 2 homework
初始完成日期:2017.9.26 许可:除2.55对应代码外(如需使用请联系 randy.bryant@cs.cmu.edu),任何人可以自由的使用,修改,分发本文档的代码. 本机环境: (有一些需要 ...
- 深入理解计算机系统_3e 第四章家庭作业(部分) CS:APP3e chapter 4 homework
4.52以后的题目中的代码大多是书上的,如需使用请联系 randy.bryant@cs.cmu.edu 更新:关于编译Y86-64中遇到的问题,可以参考一下CS:APP3e 深入理解计算机系统_3e ...
- 深入理解计算机系统_3e 第八章家庭作业 CS:APP3e chapter 8 homework
8.9 关于并行的定义我之前写过一篇文章,参考: 并发与并行的区别 The differences between Concurrency and Parallel +---------------- ...
- 深入理解计算机系统_3e 第十章家庭作业 CS:APP3e chapter 10 homework
10.6 1.若成功打开"foo.txt": -->1.1若成功打开"baz.txt": 输出"4\n" -->1.2若未能成功 ...
随机推荐
- 【转】使用PowerDesigner的建模创建升级管理数据库
使用PowerDesigner的建模创建升级管理数据库 PowerDesigner是一种著名的CASE建摸工具,最开始为数据库建模设计,即物理模型(Physical Data Model)用于生成数据 ...
- 单例模式/ThreadLocal/线程内共享数据
import java.util.Random; public class ThreadDemo3 { public static void main(String[] args) { for(int ...
- TIJ学习总结(1)- Java基础语法
TIJ(Thinking in Java)作为Java学习书籍里的"圣经",之前花两个月系统的捋了一遍,很多东西有种豁然开朗的感觉,入门之后读一遍TIJ,相信会有很多意外收获哦- ...
- set 利用lower_bound实现key索引
set中数据类型为结构体T,T中有两个成员key和val定义如下: struct T{ int key,val; T(int k,int v):key(k),val(v){} bool operato ...
- Heap Sorting 总结 (C++)
各位读者,大家好. 因为算法和数据结构相关的知识都是在国外学的,所以有些词汇翻译的可能不准确,然后一些源代码的注释可能是英文的,如有给大家带来什么不方便,请见谅.今天我想写一下Heap相关的知识,从基 ...
- 乐呵乐呵得了 golang入坑系列
开场就有料,今天返回去看了看以前的文章,轻松指数有点下降趋势.一琢磨,这不是我的风格呀.一反思,合着是这段时间,脑子里杂七杂八的杂事有点多,事情一多,就忘了快乐.古话说得好:愁也一天,乐也一天,只要还 ...
- CATransition
CATransition *transition = [CATransition animation]; transition.duration = 1.0f; /* 间隔时间* ...
- 通过邮箱发送html报表
前言 需求是发送邮件时, 可以将报表正文贴到邮件里, 可以正常复制选中报表内容. 目前的做法是简单粗暴的转成了一张图片, 这样效果显然是很糟糕的. 今天看到邮箱里可以预览Word, Excel, F1 ...
- Scala入门系列(十一):模式匹配
引言 模式匹配是Scala中非常有特色,非常强大的一种功能. 类似于Java中的switch case语法,但是模式匹配的功能要比它强大得多,switch只能对值进行匹配,但是Scala的模式匹配除了 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...