tensorflow函数介绍(2)
参考:tensorflow书
1、模型的导出:
import tensorflow as tf
v1=tf.Variable(tf.constant(2.0),name="v1")
v2=tf.Variable(tf.constant(3.0),name="v2")
init_op=tf.global_variables_initializer()
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
saver_path=saver.save(sess,"model.ckpt")
print("model saved in file:",saver_path)
2、模型的导入:
import tensorflow as tf
saver = tf.train.import_meta_graph("model.ckpt.meta")
with tf.Session() as sess:
saver.restore(sess, "model.ckpt")
print (sess.run(tf.get_default_graph().get_tensor_by_name("add:0")))
例1:模型的导入、导出的应用
import tensorflow as tf
var_1=tf.Variable(tf.constant([1,2],shape=[1,2]),name='var_1',dtype=tf.int32)
var_2=tf.placeholder(shape=[2,1],name='var_2',dtype=tf.int32)
var_3=tf.matmul(var_1,var_2,name='var_3')
with tf.Session() as sess:
saver=tf.train.Saver()
init=tf.global_variables_initializer()
sess.run(init)
saver.save(sess,'data.chkp')
saver=tf.train.import_meta_graph('data.chkp.meta')
predict=tf.get_default_graph().get_tensor_by_name('var_3:0')
sess.run(init)
print(predict.eval(session=sess,feed_dict={var_2:[[2],[2]]}))
with tf.Session() as sess:
saver.restore(sess,'data.chkp')
print(sess.run(var_3,feed_dict={var_2:[[5],[5]]}))
接上(若对变量名字作了改变,则在tf.train.Saver()中引入字典来作调整):
import tensorflow as tf
var_1=tf.Variable(tf.constant([1,2],shape=[1,2]),name='other_var_1')
var_2=tf.Variable(tf.constant([1,2],shape=[2,1]),name='other_var_2') #将上面代码的placeholder换成Variable
var_3=tf.matmul(var_1,var_2,name='var_3')
saver=tf.train.Saver({'var_1':var_1,'var_2':var_2})
with tf.Session() as sess:
saver.restore(sess,'data.chkp')
print(sess.run(var_3))
3、迭代的计数表示:
参考:http://blog.csdn.net/shenxiaolu1984/article/details/52815641
global_step = tf.Variable(0, trainable=False)
increment_op = tf.assign_add(global_step, tf.constant(1))
lr = tf.train.exponential_decay(0.1, global_step, decay_steps=1, decay_rate=0.9, staircase=False) #创建计数器衰减的tensor
tf.summary.scalar('learning_rate', lr) #对标量数据汇总和记录,把tensor添加到观测中
sum_ops = tf.summary.merge_all() #获取所有的操作
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
summary_writer = tf.train.SummaryWriter('/tmp/log/', sess.graph) #将监测结果输出目录
for step in range(0, 10): #迭代写入文件
s_val = sess.run(sum_ops) # 获取serialized监测结果:bytes类型的字符串
summary_writer.add_summary(s_val, global_step=step) # 写入文件
sess.run(increment_op)
4、指数衰减法tf.train.exponential_decay()的使用
参考:http://blog.csdn.net/zsean/article/details/75196092
decayed_learning_rate=learining_rate*decay_rate^(global_step/decay_steps) #每轮迭代通过乘以decay_rate来调整学习率值
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase=True) #生成学习率,其中衰减率为0.96,每100轮巡检进行一次迭代,学习率乘以0.96
learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(....., global_step=global_step) #使用指数衰减学习率来进行梯度下降优化
注:Adam算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即alpha)更新所有的权重,学习率在训练过程中并不会改变。而Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
5、通过自己创建collection组织对象,来构建loss
import tensorflow as tf
x1=tf.constant(1.0)
l1=tf.nn.l2_loss(x1)
x2 = tf.constant([2.5, -0.3])
l2 = tf.nn.l2_loss(x2)
tf.add_to_collection('losses',l1) #通过手动指定一个collection来将创建的损失添加到集合
tf.add_to_collection("losses", l2)
losses=tf.get_collection('losses') #创建完成后统一获取所有损失,losses是一个tensor类型的list
loss_total=tf.add_n(losses) #把所有损失累加起来得到一个tensor
sess=tf.Session()
init=tf.global_variables_initializer()
sess.run(init)
sess.run(losses)
sess.run(loss_total)
6、tf.nn.embedding_lookup(embedding, self.input_x)的含义
该函数返回embedding中的第input_x行所对应的内容,并得到这些行所组成的tensor,如下图:
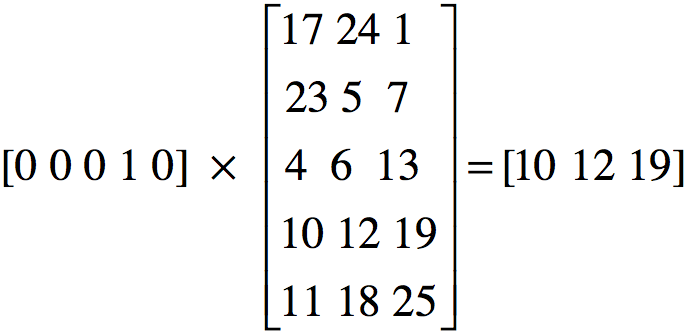
tensorflow函数介绍(2)的更多相关文章
- tensorflow函数介绍(4)
1.队列的实现: import tensorflow as tf q=tf.FIFOQueue(2,'int32') #创建一个先进先出队列,指定队列中最多可以保存两个元素,并指定类型为整数. #先进 ...
- tensorflow函数介绍(3)
tf.nn.softmax_cross_entropy_with_logits(logits,labels) #其中logits为神经网络最后一层输出,labels为实际的标签,该函数返回经过soft ...
- tensorflow函数介绍(1)
tensorflow中的tensor表示一种数据结构,而flow则表现为一种计算模型,两者合起来就是通过计算图的形式来进行计算表述,其每个计算都是计算图上的一个节点,节点间的边表示了计算之间的依赖关系 ...
- tensorflow函数介绍 (5)
1.tf.ConfigProto tf.ConfigProto一般用在创建session的时候,用来对session进行参数配置: with tf.Session(config=tf.ConfigPr ...
- Tensorflow | 基本函数介绍 简单详细的教程。 有用, 很棒
http://blog.csdn.net/xxzhangx/article/details/54606040 Tensorflow | 基本函数介绍 2017-01-18 23:04 1404人阅读 ...
- python strip()函数 介绍
python strip()函数 介绍,需要的朋友可以参考一下 函数原型 声明:s为字符串,rm为要删除的字符序列 s.strip(rm) 删除s字符串中开头.结尾处,位于 rm删除 ...
- PHP ob_start() 函数介绍
ob_start() 函数介绍: http://www.nowamagic.net/php/php_ObStart.php ob_start()作用: http://zhidao.baidu.com/ ...
- Python开发【第三章】:Python函数介绍
一. 函数介绍 1.函数是什么? 在学习函数之前,一直遵循面向过程编程,即根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复 ...
- row_number() OVER(PARTITION BY)函数介绍
OVER(PARTITION BY)函数介绍 开窗函数 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个 ...
随机推荐
- 浅谈关于SQL优化的思路
零.为什么要优化 系统的吞吐量瓶颈往往出现在数据库的访问速度上 随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢 数据是存放在磁盘上的,读写速度无法和内存相比 一.观察 MySQL优 ...
- 多行文本溢出隐藏处理,兼容ie,火狐
问题 多行文本溢出隐藏,webkit内核浏览器如谷歌支持如下写法: overflow: hidden; text-overflow: ellipsis; display: -webkit-box; - ...
- 北风设计模式课程---备忘录(Memento)模式
北风设计模式课程---备忘录(Memento)模式 一.总结 一句话总结: 备忘录模式也是一种比较常用的模式用来保存对象的部分用于恢复的信息,和原型模式有着本质的区别,广泛运用在快照功能之中.同样的使 ...
- Eclipse报内存溢出
(1)在配置tomcat的JDK里面设置.Window-->proference->Myeclipse-->servers-->Tomcat5-->JDK里面设置: -X ...
- Java thread(1)
这一部分主要讨论 java多线程的基本相关概念以及两种java线程的实现方式: 线程与进程: 这个操作系统书上介绍得很详细,这里就列出一些比较主要的: 线程: 线程本身有很少的资源,因为所拥有的资源较 ...
- DS-哈希表浅析
1.哈希表 2.哈希函数 3.哈希冲突 哈希表 哈希表是一种按key-value存储的数据结构,也称散列表. 之前的数组.树和图等等查找一个值时都要与结构中的值相比较,查找的效率取决于比较的次数. 而 ...
- BZOJ 4675(点分治)
题面 传送门 分析 由于期望的线性性,我们可以分别计算每个点对对答案的贡献 有三个人取数字,分开对每个人考虑 设每个人分别取了k个数,则一共有\(C_n^k\)种组合,选到每种组合的概率为\(\fra ...
- 8786:方格取数 (多线程dp)
[题目描述] 设有N*N的方格图(N<=10),我们将其中的某些方格中填入正整数,而其他的方格中则放入数字0.某人从图的左上角的A 点出发,可以向下行走,也可以向右走,直到到达右下角的B点.在走 ...
- Laya2.0的转变
之前一直用Laya1.x+TypeScript了,最近项目开始使用Laya2.0+AS3了 总结一下需要注意的一些事项,算是2种开发模式的区别与过渡吧 1.AS类的访问标识 必须是public,不写会 ...
- P4126 [AHOI2009]最小割(网络流+tarjan)
P4126 [AHOI2009]最小割 边$(x,y)$是可行流的条件: 1.满流:2.残量网络中$x,y$不连通 边$(x,y)$是必须流的条件: 1.满流:2.残量网络中$x,S$与$y,T$分别 ...