时序数据库 Apache-IoTDB 源码解析之前言(一)
IoTDB 是一款时序数据库,相关竞品有 Kairosdb,InfluxDB,TimescaleDB等,主要使用场景是在物联网相关行业,如:车联网、风力发电、地铁、飞机监控等等,具体应用案例及公司详情可以查看:IoTDB在实际公司中的使用信息收集
IoTDB 模块主要分为Client,JDBC,Server,TsFile,Grafana,Distribution 以及各种生态的连接器。整个系列的文章会从行业背景开始讲起,了解一个行业具体的使用场景,然后介绍 TsFile 是以什么样的格式来保存数据的,再介绍 Server 里怎样完成一次查询,最后在介绍一条完 整的 SQL是怎样从 Client 使用 JDBC 到 Server 直至返回具体结果。如果有能力的话再介绍一下集群的一些内容和工作方式。
打一波广告本人专注车联网领域多年,现任四维智联架构师。目前正在参与 IoTDB 社区,有志同道合的同伴欢迎加微信:liutaohua001
欢迎大家访问 IoTDB 仓库,求一波 Star 。
这一章主要想聊一聊:
- 为什么重复造轮子,从物联网行业的数据特点到
IoTDB的发展过程 - 这个轮子造的怎么样,
IoTDB和竞品测试对比
时序数据
我个人理解时序数据是基于时间维度的同一个物体或概念的值构成的一个序列数据。在传统关系型数据库中,例如 MySQL,我们通常会放置一个自增的 Id 列作为主键标识,如下:
| Id | 人名 | 体温 | 测量时间 |
|---|---|---|---|
| 1 | 张三 | 36.5 | 2020-02-06 9:00:00 |
| 2 | 李四 | 36.9 | 2020-02-06 9:00:00 |
| 3 | 王五 | 36.7 | 2020-02-06 9:00:00 |
| 4 | 张三 | 36.3 | 2020-02-06 9:30:00 |
| 5 | 张三 | 36.9 | 2020-02-06 11:00:00 |
上面的表结构就是一个时序数据,将表结构做个变形更容易理解:
| 时间戳 | 人名 | 体温 |
|---|---|---|
| 1580950800 | 张三 | 36.5 |
| 1580950800 | 李四 | 36.9 |
| 1580950800 | 王五 | 36.7 |
| 1580952600 | 张三 | 36.3 |
| 1580958000 | 张三 | 36.9 |
如果把时间作为一个唯一键对齐展示,能够更像时序数据一些,这也是 IoTDB 中查询结果的展示方式:
| 时间戳 | 张三 | 李四 | 王五 |
|---|---|---|---|
| 1580950800 | 36.5 | 36.9 | 36.7 |
| 1580952600 | 36.3 | NULL | NULL |
| 1580958000 | 36.9 | NULL | NULL |
这里可能会存在疑问就是假如人数是逐渐增加的,那么是动态创建列呢?还是提前创建足够多的列?这个问题等后面文章有机会继续介绍
物联网
物联网的特点是都会存在一个或多个设备,他们以各种各样的形式组织到一起,用来观测或记录同一时间里相同环境所产生的数据。下面的介绍中,使用由简单到复杂的数据逐步介绍在物联网行业中,通用的一些问题和方向。
1.基本存储
假如我是一个公司,对外播报北京、天津、上海三地的温度数据,从而实现盈利。
| 时间戳 | 北京 | 天津 | 上海 |
|---|---|---|---|
| 1580950800 | 20.5 | 22.9 | 21.7 |
| 1580952600 | 20.5 | NULL | 22.9 |
| 1580958000 | 20.5 | 21.7 | 22.9 |
2.保证数据质量
数据保证的质量是多方面的,一步一步介绍。
2.1 更多设备
首先可以看到上面数据是存在 NULL 值的,这个 NULL 值有可能是因为当时设备所在的区域停电了,所以并没有办法上报当时的情况,这样客户如果想获取1580952600 这个时间戳对应的天津的数据的时候,肯定是拿不到了,所以传统思维上,我们应该增加一个容灾设备,保证一个设备在坏掉、停电、人为损坏等等的情况的时候,依然能够有数据上报回来。
基于这样的思想,以上的表结构就会变成:
| 时间戳 | 北京 1 | 北京 2 | 天津1 | 天津2 | 上海1 | 上海2 |
|---|---|---|---|---|---|---|
| 1580950800 | 20.5 | 20.9 | 21.7 | 20.9 | 20.7 | 21.7 |
| 1580952600 | 21.5 | 21.0 | NULL | 21.7 | 21.7 | 21.7 |
| 1580958000 | 22.5 | 22.7 | 22.9 | 22.7 | NULL | NULL |
2.2 更高采样频率
这时候依然存在问题, 1580958000 这一刻两个设备都没有数据,有可能是放置设备的区域同时出现了断网或者断电,这种情况下,我们可以采用提高采集数据的频率或者补传数据来解决(补传暂不讨论)。
我们将每天数据分为3组,每组采样3次,间隔为1个小时,假如时间分布为:上午(7、8、9)、中午(12、13、14)、下午(18、19、20)。当增加了采样频率之后,即便某一刻出现了 NULL 数据,我们也可以采用临近时间做为补充。为了方便对应,下表数据中增加时间点列辅助查看。
| 时间点 | 时间戳 | 北京 1 | 北京 2 | 天津1 | 天津2 | 上海1 | 上海2 |
|---|---|---|---|---|---|---|---|
| 7点 | 1580943600 | 20.5 | 20.9 | 21.7 | 20.9 | 20.7 | 21.7 |
| 8点 | 1580947200 | 21.5 | 21.0 | NULL | 21.7 | 21.7 | 21.7 |
| 9点 | 1580950800 | 22.5 | 22.7 | 22.9 | 22.7 | NULL | NULL |
| 12点 | 1580961600 | 20.5 | 20.9 | 21.7 | 20.9 | 20.7 | 21.7 |
| 13点 | 1580965200 | 21.5 | 21.0 | NULL | 21.7 | 21.7 | 21.7 |
| 14点 | 1580968800 | 22.5 | 22.7 | 22.9 | 22.7 | NULL | NULL |
| 18点 | 1580983200 | 20.5 | 20.9 | 21.7 | 20.9 | 20.7 | 21.7 |
| 19点 | 1580986800 | 21.5 | 21.0 | NULL | 21.7 | 21.7 | 21.7 |
| 20点 | 1580990400 | 22.5 | 22.7 | 22.9 | 22.7 | NULL | NULL |
可以看到经过各种各样的需求之后,上传的数据是成倍增长的,不难想象如果这个温度数据希望精准的获取到每个县城的温度,那么中国有 2854 个县城 * 2 个温度设备 * 9 条数据 = 1 天产生的数据总量 = 51372 条,那么一个月就是 1541160 条。
数据实时性及总量
假如上面的数据我们继续提高频率到每1分钟每个设备上报一次,那么数据量就会成为 2854 * 2 * 60 * 24 = 246585600 条/天。
在这样的数据量下,实时插入实时做一些聚合计算,应该传统数据库就有些处理不过来了。
IoTDB 的前身
某公司在实际业务中,20 万设备保存了 3 年的数据,TB级别的数据使得 Oracle 被拖的根本吃不消。关键的问题点还不仅仅是存量数据大,新增数据依然以非常快的速度在增长。后来公司联系到了 IoTDB 的第一批开发者,但是当时的方案还是基于 Cassandra 来做设计,当时规划了 5 台机器的集群,性能刚满足,但随着时间推移设备总量在增加,业务系统的查询请求量在增加。Cassandra 在经过大量的努力之后,最后发现如果再改可能就需要大面积的重构 Cassandra 数据的代码了,最终决定重新设计一个存储方式,来解决物联网场景下的时序数据高效写入、低延迟读取、高压缩比持久化。
PS: 以上都是黄向东 (IoTDB PPMC) ,在 meetup 中讲到的,我只是在脑中存留了一部分,具体的细节大家可以到 IoTDB 社区交流。
性能对比
测试工具使用的是由清华大学大数据实验室开发的iotdb-benchmark
1.写入性能对比
| 数据集2 | 客户端 | 存储组 | 设备 | 变量 | batchsize | LOOP | 数据量 | 写入速度(point/s) | 硬盘数据大小 |
|---|---|---|---|---|---|---|---|---|---|
| IoTDB | 10 | 10 | 10 | 10 | 1000 | 1000000 | 1E+11 | 24750321.93 | 38306092 |
| InfluxDB | 10 | 10 | 10 | 10 | 1000 | 1000000 | 1E+11 | 304682932 | |
| TimescaleDB | 10 | 10 | 10 | 10 | 1000 | 1000000 | 1E+11 | 737689.22 | 1610219064 |
| 数据集1 | 客户端 | 存储组 | 设备 | 变量 | batchsize | LOOP | 数据量 | 写入速度(point/s) | 硬盘数据大小 |
|---|---|---|---|---|---|---|---|---|---|
| IoTDB | 10 | 10 | 10 | 10 | 1000 | 100000 | 10000000000 | 20706345.15 | 3599732 |
| InfluxDB | 10 | 10 | 10 | 10 | 1000 | 100000 | 10000000000 | 1729907.81 | 30546560 |
| TimescaleDB | 10 | 10 | 10 | 10 | 1000 | 100000 | 10000000000 | 715857 | 161026468 |
| KairosDB | 10 | 10 | 10 | 10 | 10000 | 10000 | 10000000000 | 24924.97 | 76263380 |
上面一组数据可以看出写入性能高于同款数据库10倍有余,单机写入速度高达到每秒2千万。且硬盘占用是最小的,这在数据比较大的线上业务中,可能每个月会差出来 1 到 2 块硬盘。
2. 查询性能对比
原始数据查询
| 客户端 | 存储组 | 设备 | 序列-数据量 | 变量 | 查询点数 | LOOP | 速度(point/s) | AVG | MIN | |
|---|---|---|---|---|---|---|---|---|---|---|
| IoTDB | 10 | 10 | 10 | 1.00E+09 | 1 | 1000000 | 100 | 12942984.85 | 740.27 | 457.04 |
| InfluxDB | 10 | 10 | 10 | 1.00E+09 | 1 | 1000000 | 100 | 1779606.4 | 5591 | 4666.39 |
| TimescaleDB | 10 | 10 | 10 | 1.00E+09 | 1 | 1000000 | 100 | 3781467.52 | 2345.69 | 1193.78 |
聚合数据查询
| 客户端 | 存储组 | 设备 | 序列-数据量 | 变量 | LOOP | 范围 | 速度(point/s) | AVG | MIN | |
|---|---|---|---|---|---|---|---|---|---|---|
| IoTDB-1 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.0001 | 49.75 | 27.87 | 18.03 |
| IoTDB-2 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.001 | 49.75 | 49.14 | 19.87 |
| IoTDB-3 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.01 | 49.76 | 48.69 | 22.32 |
| IoTDB-4 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.1 | 48.68 | 99.14 | 25.56 |
| IoTDB-5 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 1 | 14 | 595.61 | 45.54 |
| InfluxDB-1 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.0001 | 234.32 | 40.28 | 21.63 |
| InfluxDB-2 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.001 | 28.88 | 341.9 | 238.1 |
| InfluxDB-3 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.01 | 3.07 | 3226.87 | 2664.86 |
| TimescaleDB-1 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.0001 | 42.39 | 220.57 | 120.5 |
| TimescaleDB-2 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.001 | 5.8 | 1502.9 | 754.15 |
| TimescaleDB-3 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.01 | 1.02 | 9711.55 | 7148.69 |
3. 对比图
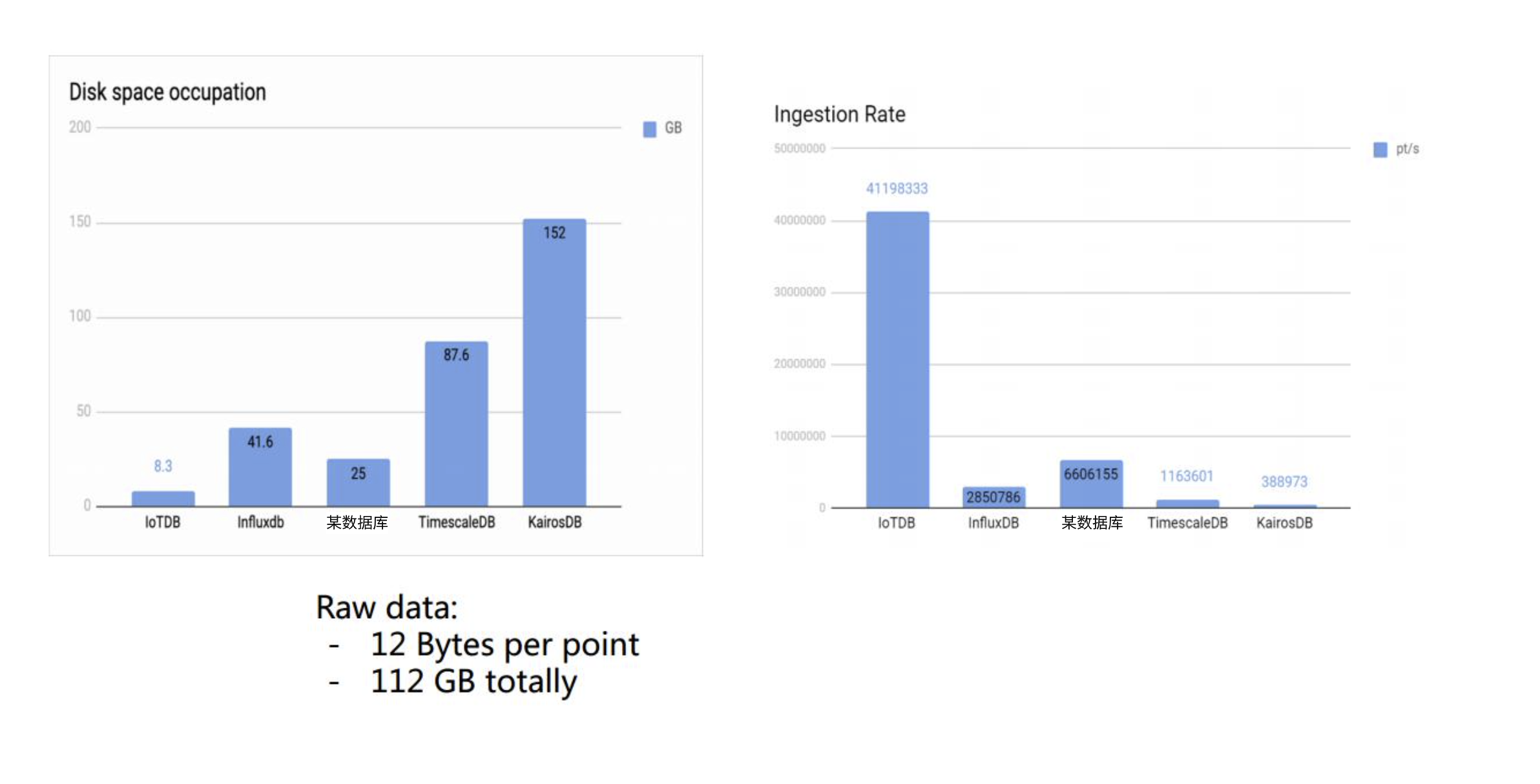
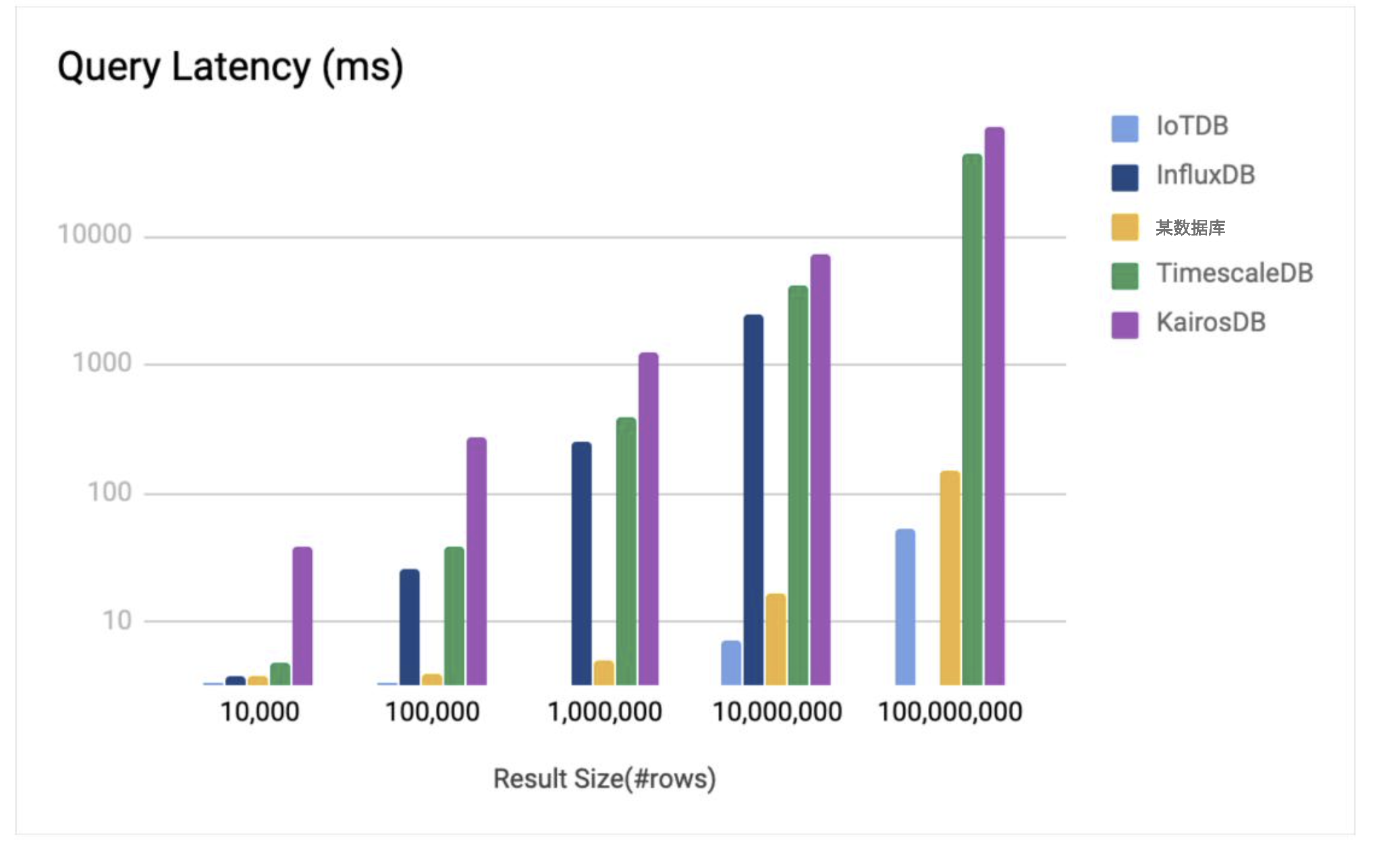
整体来看 IoTDB 无论在写入、原始数据查询还是聚合查询,都几乎是10倍的性能于竞品数据库,而且硬盘占用又小于同款数据库10倍,那么 IoTDB 是怎样完成如此高的压缩比、如此恐怖的写入速度、如此高效的查询呢?欢迎继续关注。。。
时序数据库 Apache-IoTDB 源码解析之前言(一)的更多相关文章
- Ocelot简易教程(七)之配置文件数据库存储插件源码解析
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9852711.html 上篇文章给大家分享了如何集成我写的一个Ocelot扩展插件把Ocelot的配置存储 ...
- 时序数据库 Apache-IoTDB 源码解析之系统架构(二)
上一章聊到时序数据是什么样,物联网行业中的时序数据的特点:存量数据大.新增数据多(采集频率高.设备量多).详情请见: 时序数据库 Apache-IoTDB 源码解析之前言(一) 打一波广告,欢迎大家访 ...
- Mybatis源码解析(四) —— SqlSession是如何实现数据库操作的?
Mybatis源码解析(四) -- SqlSession是如何实现数据库操作的? 如果拿一次数据库请求操作做比喻,那么前面3篇文章就是在做请求准备,真正执行操作的是本篇文章要讲述的内容.正如标题一 ...
- [源码解析] 从TimeoutException看Flink的心跳机制
[源码解析] 从TimeoutException看Flink的心跳机制 目录 [源码解析] 从TimeoutException看Flink的心跳机制 0x00 摘要 0x01 缘由 0x02 背景概念 ...
- [源码解析] Flink的Slot究竟是什么?(1)
[源码解析] Flink的Slot究竟是什么?(1) 目录 [源码解析] Flink的Slot究竟是什么?(1) 0x00 摘要 0x01 概述 & 问题 1.1 Fllink工作原理 1.2 ...
- [源码解析] Flink的Slot究竟是什么?(2)
[源码解析] Flink 的slot究竟是什么?(2) 目录 [源码解析] Flink 的slot究竟是什么?(2) 0x00 摘要 0x01 前文回顾 0x02 注册/更新Slot 2.1 Task ...
- [Java源码解析] -- String类的compareTo(String otherString)方法的源码解析
String类下的compareTo(String otherString)方法的源码解析 一. 前言 近日研究了一下String类的一些方法, 通过查看源码, 对一些常用的方法也有了更透彻的认识, ...
- RxJava2源码解析(二)
title: RxJava2源码解析(二) categories: 源码解析 tags: 源码解析 rxJava2 前言 本篇主要解析RxJava的线程切换的原理实现 subscribeOn 首先, ...
- 时序数据库 Apache-IoTDB 源码解析之文件数据块(四)
上一章聊到行式存储.列式存储的基本概念,并介绍了 TsFile 是如何存储数据以及基本概念.详情请见: 时序数据库 Apache-IoTDB 源码解析之文件格式简介(三) 打一波广告,欢迎大家访问Io ...
随机推荐
- Python+appium+unittest UI自动化测试
什么是UI自动化 自动化分层 单元自动化测试,指对软件中最小可测试单元进行检查和验证,一般需要借助单元测试框架,如java的JUnit,python的unittest等 接口自动化测试,主要检查验证模 ...
- sql函数实用——字符函数(sqlserver与mysql对比)
1.获取长度 sqlserver写法:关键字:len() 获取参数的字符数量 select Len('aksjdhh') 输出结果 7 select len('张无忌ooo') 输出 ...
- 1040 有几个PAT (25 分)C语言
字符串 APPAPT 中包含了两个单词 PAT,其中第一个 PAT 是第 2 位§,第 4 位(A),第 6 位(T):第二个 PAT 是第 3 位§,第 4 位(A),第 6 位(T). 现给定字符 ...
- ruby 输出彩色内容到控制台
程序输出控制台时,为了区分输出信息的严重程度,可以使用颜色.符号等来做标识. ruby 也支持设置输出内容的颜色,比如运行以下代码: 以下内容是百度到的,因发现很多博客都是同样的写法,所以出处反而没法 ...
- Magicodes.IE编写多框架版本支持和执行单元测试
背景 很多情况下,我们编写了一些工具库之后,往往在某些框架版本中会出现一些问题,比如本人最近写的一个导入导出的工具库Magicodes.IE(GitHub:https://github.com/xin ...
- 实现antd下拉框动态添加内容(与数据库交互)
antd下拉控件的动态内容添加(与数据库交互) antd这个框架给开发带来了极大的方便,但同时,我认为还有一些不方便的地方:常用的逻辑在文档中没有体现.需要前端开发经验的人才能快速上手,而我刚刚接触这 ...
- doc_values VS stored field
doc_values 按列存储,按docId排序,在query阶段使用,直接根据docId获取具体field的value,用来排序,聚合等. stored field按文档存储,按docId排序,一条 ...
- 拥有 GitHub 开源项目的小伙伴,免费申请 JetBrains 全家桶的全流程详解
工欲善其事,必先利其器.如果您想要学习 Java.PHP.Ruby.Python.JavaScript.Objective-C..NET 中的任何一种开发技术,国际知名且屡获殊荣的 JetBrains ...
- linux下解压缩文件中文乱码问题的解决
在windows上压缩的文件,是以系统默认编码中文来压缩文件.由于zip文件中没有声明其编码,所以linux上的unzip一般以默认编码解压,中文文件名会出现乱码. 虽然2005年就有人把这报告为bu ...
- .Net Core 导出Html到PDF
前言 最近由于项目的需求问题,涉及到了在.Net Core中导出PDF的一个问题,最后选择方式是后端拼接到Html页面然后再通过Html导出到PDF.中间也尝试了许多的NuGet包.但是并不如意,可用 ...