Paper慢慢读 - AB实验人群定向 Double Machine Learning
Hetergeneous Treatment Effect旨在量化实验对不同人群的差异影响,进而通过人群定向/数值策略的方式进行差异化实验,或者对实验进行调整。Double Machine Learning把Treatment作为特征,通过估计特征对目标的影响来计算实验的差异效果。
Machine Learning擅长给出精准的预测,而经济学更注重特征对目标影响的无偏估计。DML把经济学的方法和机器学习相结合,在经济学框架下用任意的ML模型给出特征对目标影响的无偏估计
HTE其他方法流派详见因果推理的春天-实用HTE论文GitHub收藏
核心论文
V. Chernozhukov, D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, and a. W. Newey. Double Machine Learning for Treatment and Causal Parameters. ArXiv e-prints 文章链接
背景
HTE问题可以用以下的notation进行简单的抽象
- Y是实验影响的核心指标
- T是treatment,通常是0/1变量,代表样本进入实验组还是对照组,对随机AB实验\(T \perp X\)
- X是Confounder,可以简单理解为未被实验干预过的用户特征,通常是高维向量
- DML最终估计的是\(\theta(x)\),也就是实验对不同用户核心指标的不同影响
\[
\begin{align}
Y &= \theta(x) T + g(X) + \epsilon &\text{where }E(\epsilon |T,X) = 0 \\
T &= f(X) + \eta &\text{where } E(\eta|X) = 0 \\
\end{align}
\]
最直接的方法就是用X和T一起对Y建模,直接估计\(\theta(x)\)。但这样估计出的\(\theta(x)\)往往是有偏的,偏差部分来自于对样本的过拟合,部分来自于\(\hat{g(X)}\)估计的偏差,假定\(\theta_0\)是参数的真实值,则偏差如下
\[
\sqrt{n}(\hat{\theta}-\theta_0) = (\frac{1}{n}\sum{T_i^2})^{-1}\frac{1}{\sqrt{n}}\sum{T_iU_i} +(\frac{1}{n}\sum{T_i^2})^{-1}(\frac{1}{\sqrt{n}}\sum{T_i(g(x_i) -\hat{g(x_i)})})
\]
DML模型
DML模型分为以下三个步骤
步骤一. 用任意ML模型拟合Y和T得到残差\(\tilde{Y},\tilde{T}\)
\[
\begin{align}
\tilde{Y} &= Y - l(x) &\text{ where } l(x) = E(Y|x)\\
\tilde{T} &= T - m(x) &\text{ where } m(x) = E(T|x)\\
\end{align}
\]
步骤二. 对\(\tilde{Y},\tilde{T}\)用任意ML模型拟合\(\hat{\theta}\)
\(\theta(X)\)的拟合可以是参数模型也可以是非参数模型,参数模型可以直接拟合。而非参数模型因为只接受输入和输出所以需要再做如下变换,模型Target变为\(\frac{\tilde{Y}}{\tilde{T}}\), 样本权重为\(\tilde{T}^2\)
\[
\begin{align}
& \tilde{Y} = \theta(x)\tilde{T} + \epsilon \\
& argmin E[(\tilde{Y} - \theta(x) \cdot \tilde{T} )^2]\\
&E[(\tilde{Y} - \theta(x) \cdot \tilde{T} )^2] = E(\tilde{T}^2(\frac{\tilde{Y}}{\tilde{T}} - \theta(x))^2)
\end{align}
\]
步骤三. Cross-fitting
DML保证估计无偏很重要的一步就是Cross-fitting,用来降低overfitting带来的估计偏差。先把总样本分成两份:样本1,样本2。先用样本1估计残差,样本2估计\(\hat{\theta}^1\),再用样本2估计残差,样本1估计$ \hat{\theta}^2$,取平均得到最终的估计。当然也可以进一步使用K-Fold来增加估计的稳健性。
\[
\begin{align}
sample_1, sample_2 &= \text{sample_split} \\
\theta &= \hat{\theta}^1 + \hat{\theta}^2 \\
\end{align}
\]
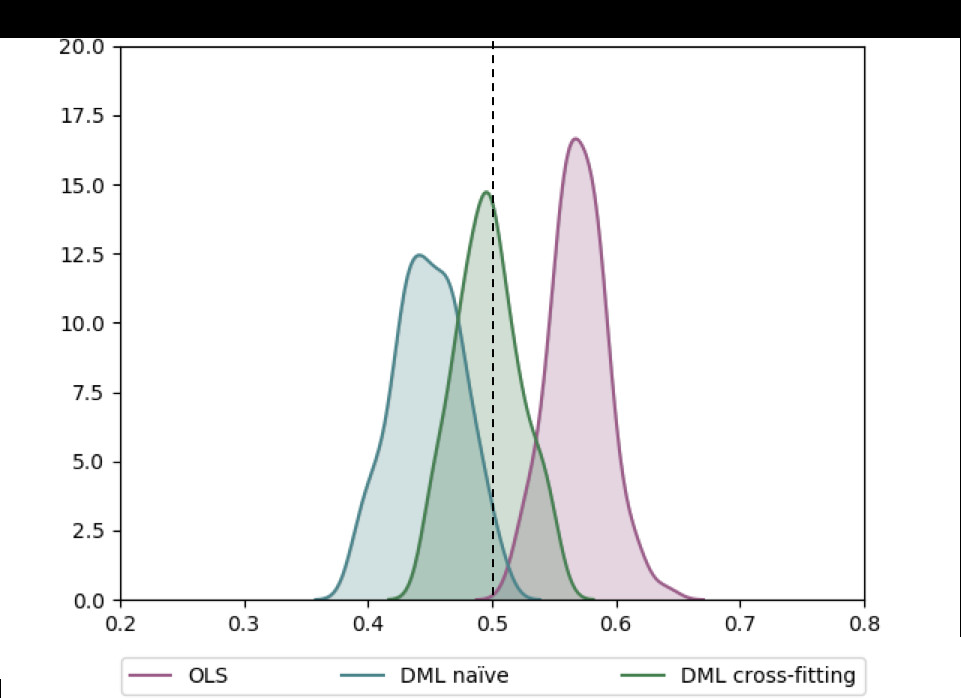
Jonas在他的博客里比较了不使用DML,使用DML但是不用Cross-fitting,以及使用Cross-fitting的估计效果如下
从GMM的角度来理解
Generalized Method of Moments广义矩估计 (GMM)在经济学领域用的更多,在论文里乍一看到moment condition琢磨半天也没想起来,索性在这里简单的回顾下GMM的内容。
啥是矩估计呢?可以简单理解是用样本的分布特征来估计总计分布,分布特征由\(E((x-a)^K)\),样本的K阶矩来抽象,一阶矩就是均值,二阶原点矩就是方差。举几个例子吧~
例如,总体样本服从\(N(\mu, \sigma^2)\)就有两个参数需要估计,那么就需要两个方程来解两个未知数,既一阶矩条件\(\sum{x_i}-\mu=0\)和二阶矩条件\(\sum{x_i^2} - \mu^2 - \sigma^2=0\)。
再例如OLS,\(Y=\beta X\)可以用最小二乘法来求解\(argmin (Y-\beta X)^2\),但同样可以用矩估计来求解\(E(X(Y-\beta X))=0\)。实则最小二乘只是GMM的一个特例。
那针对HTE问题,我们应该选择什么样的矩条件来估计\(\theta\)呢?
直接估计\(\theta\)的矩条件如下
\(E(T(Y-T\theta_0-\hat{g_0(x)}))=0\)
DML基于残差估计的矩条件如下
\(E([(Y-E(Y|X))-(T-E(T|X))\theta_0](T-E(T|X)))=0\)
作者指出DML的矩条件服从Neyman orthogonality条件,因此即便\(g(x)\)估计有偏,依旧可以得到无偏的\(\theta\)的估计。
参考材料&开源代码
- V. Chernozhukov, M. Goldman, V. Semenova, and M. Taddy. Orthogonal Machine Learning for Demand Estimation: High Dimensional Causal Inference in Dynamic Panels. ArXiv e-prints, December 2017.
- V. Chernozhukov, D. Nekipelov, V. Semenova, and V. Syrgkanis. Two-Stage Estimation with a High-Dimensional Second Stage. 2018.
- Microsoft 因果推理开源代码 EconML
- Double Machine Learning 开源代码 MLInference
- https://www.linkedin.com/pulse/double-machine-learning-approximately-unbiased-jonas-vetterle/
- https://www.zhihu.com/question/41312883
Paper慢慢读 - AB实验人群定向 Double Machine Learning的更多相关文章
- Paper慢慢读 - AB实验人群定向 Recursive Partitioning for Heterogeneous Casual Effects
这篇是treatment effect估计相关的论文系列第一篇所以会啰嗦一点多给出点背景. 论文 Athey, S., and Imbens, G. 2016. Recursive partition ...
- Paper慢慢读 - AB实验人群定向 Learning Triggers for Heterogeneous Treatment Effects
这篇论文是在 Recursive Partitioning for Heterogeneous Casual Effects 的基础上加入了两个新元素: Trigger:对不同群体的treatment ...
- AB实验人群定向HTE模型5 - Meta Learner
Meta Learner和之前介绍的Casual Tree直接估计模型不同,属于间接估计模型的一种.它并不直接对treatment effect进行建模,而是通过对response effect(ta ...
- AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
- AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!
背景 AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器.但人们对AB实验的应用往往只停留在开实验算P值,然后let it go...let it go ... 让我们把AB实验的结果简单的拆解 ...
- AB实验的高端玩法系列3 - AB组不随机?观测试验?Propensity Score
背景 都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE) \[ ATE = E(Y_t(1) - Y_c(0)) \] 那究竟随 ...
- 滴滴数据驱动利器:AB实验之分组提效
桔妹导读:在各大互联网公司都提倡数据驱动的今天,AB实验是我们进行决策分析的一个重要利器.一次实验过程会包含多个环节,今天主要给大家分享滴滴实验平台在分组环节推出的一种提升分组均匀性的新方法.本文首先 ...
- 为什么在数据驱动的路上,AB 实验值得信赖?
在线AB实验成为当今互联网公司中必不可少的数据驱动的工具,很多公司把自己的应用来做一次AB实验作为数据驱动的试金石. 文 | 松宝 来自 字节跳动数据平台团队增长平台 在线AB实验成为当今互联网公司中 ...
- Machine Learning 方向读博的一些重要期刊及会议 && 读博第一次组会时博导的交代
读博从报道那天算起到现在已经3个多月了,这段时间以来和博导总共见过两次面,寥寥数语的见面要我对剩下的几年读书生活没有了太多的期盼,有些事情一直想去做却总是打不起来精神,最后挣扎一下还是决定把和博导开学 ...
随机推荐
- 009 Ceph RBD增量备份与恢复
一.RBD的导入导出介绍 Ceph存储可以利用快照做数据恢复,但是快照依赖于底层的存储系统没有被破坏 可以利用rbd的导入导出功能将快照导出备份 RBD导出功能可以基于快照实现增量导出 二.RBD导出 ...
- k8s集群———etcd-ssl自签名证书
etcd集群master节点安装 ,自签名SSL证书 ##安装工具cfssl $ cat cfssl.sh curl -L https://pkg.cfssl.org/R1.2/cfssl_linux ...
- 从头学pytorch(十一):自定义层
自定义layer https://www.cnblogs.com/sdu20112013/p/12132786.html一文里说了怎么写自定义的模型.本篇说怎么自定义层. 分两种: 不含模型参数的la ...
- 浅谈Redis的基本原理和数据类型结构的特性和应用开发场景
一.Redis介绍 1,redis介绍(Redis安装在磁盘:Redis数据存储在内存) redis是一种基于键值对(key-value)数据库,其中value可以为string.hash.list. ...
- 【THE LAST TIME】深入浅出 JavaScript 模块化
前言 The last time, I have learned [THE LAST TIME]一直是我想写的一个系列,旨在厚积薄发,重温前端. 也是对自己的查缺补漏和技术分享. 欢迎大家多多评论指点 ...
- java socket通讯
本来是打算验证java socket是不是单线程操作,也就是一次只能处理一个请求,处理完之后才能继续处理下一个请求.但是在其中又发现了许多问题,在编程的时候需要十分注意,今天就拿出来跟大家分享一下. ...
- MakeDown效果
这是一级标题 这是二级标题 这是三级标题 这是四级标题 这是五级标题 这是六级标题 这是加粗的文字 这是倾斜的文字 这是斜体加粗的文字 这是加删除线的文字 这是引用的内容 这是引用的内容 这是引用的内 ...
- STM32串口遇到的一个问题
做HLW8032电能表项目中关于USART使用DMA接收定长数据的问题 1:由于HLW8032芯片一上电,芯片就会通过串口每隔50ms向STM32发送24字节的数据,且我不能通过STM32控制HLW8 ...
- JDK 和JRE区别
JDK,开发java程序用的开发包,JDK里面有java的运行环境(JRE),包括client和server端的.需要配置环境变量.... JRE,运行java程序的环境,JVM,JRE里面只有cli ...
- gradle 不用打开项目直接编译
gradlew :api-client:install 编辑完后点击