Flink架构(一)- 系统架构
1. 系统架构
Flink是一个分布式系统,用于有状态的并行数据流处理。也就是说,Flink会分布式地运行在多个机器上。在分布式系统中,常见的挑战有:如何对集群中的资源进行分配与管理、协调进程、数据存储的高可用、以及异常恢复。
Flink自身并未实现这些功能,而仅关注在它自身的核心功能 - 分布式数据流处理。对于分布式集群的管理,由运行在它之下的集群完成,并提供基础设施与服务。Flink与常见集群资源管理器契合度良好,例如Apache Mesos,YARN,以及Kubernetes。当然它也可以配置为stand-alone集群。Flink并不提供可靠的分布式存储。它直接使用其他分布式文件系统如HDFS、S3等。对于在HA设置下的leader选举,它依赖于ZooKeeper。
在这章我们会介绍Flink的各个组件,以及它们如何相互作用,以运行一个application。我也也会讨论Flink 应用的两种部署模式,以及它们如何分发、执行任务。最后,介绍在HA模式下Flink如何工作。
Flink组件
在Flink中有四个不同的组件,它们共同协作运行流程序。这些组件为:一个JobManager,一个ResourceManager,一个TaskManager,以及一个Dispatcher。Flink是由Java和Scala实现,所以这些组件全部运行在JVM中。每个组件的职责为:
·JobManager:主(master)进程,用于管理单个application的执行。每个application都由一个不同的JobManager管理。JobManager会接收application并执行。一个application包含:一个JobGraph,一个逻辑数据流图(logical dataflow graph),以及一个Jar文件(包含了所有需要的类、lib库以及其他资源)。JobManager将JobGraph转化为一个物理数据流图(physical dataflow graph),称为ExecutionGraph。ExecutionGraph由一些可以并行执行的任务(tasks)组成。JobManager向ResourceManager申请必须的计算资源(称为TaskManager slots)用于执行任务。一旦JobManager收到足够的TaskManager slots,它将ExecutionGraph中的task分发到TaskManager,然后执行。在执行过程中,JobManager负责任何需要中心协调(central coordination)的操作,例如检查点(checkpoints)的协调
·ResourceManager:Flink 可以整合多个ResourceManager,例如YARN,Mesos,Kubernetes以及standalone 部署。ResourceManager负责管理TaskManager slots,也就是Flink的一个资源处理单元。当JobManager 申请TaskManager slots时,ResourceManager 会分配空闲slot给它。如果RM并没有足够的slots满足JobManager的请求,则RM can talk to a resource provider to provision containers in which TaskManager processes are started。RM也负责关闭空闲的TaskManagers,以释放计算资源。
·TaskManagers:是Flink的worker 进程。一般来说,会有多个TaskManagers运行在一个配置好的Flink 集群中。每个TaskManager提供了具体数量的 slots。Slots的数量限制了TaskManager可以运行的task数量。在TaskManager启动后,它会向ResourceManager注册它的slots。在接受到RM的指令后,TaskManager会向JobManager提供它的slots。JobManager即可分配任务到这些slots,并开始执行这些任务。在执行过程中,对于同一个application的不同taks,运行在它们之下的TaskManager 之间会互相交换数据。
·Dispatcher 提供了一个REST 接口,用于提交application执行。当一个application被提交,Dispatcher会启动一个JobManager并将application交给它。REST接口使得Dispatcher可以作为一个(位于防火墙之后的)HTTP 入口服务提供给外部。Dispathcher也运行了一个web控制面板,用于提供job执行的信息。取决于一个application如何提交执行,dispathcher可能并不是必须的。
下图展示的是:在提交一个application后,Flink的组件之间如何协作运行此应用:

上图是一个较为High-Level的角度。取决于部署的集群不同(例如YARN,standalone等),一些步骤可以被省略,亦或是有些组件会运行在同一个JVM进程中。
应用部署
Flink application 可以使用以下两种不同的方式部署:
1. 框架方式
·在这个模式下,Flink应用被打包成一个Jar文件,并由客户端提交到一个运行的服务(running service)。这个服务可以是一个Flink Dispatcher,一个FlinkJobManager,或是Yarn ResourceManager。如果application被提交给一个JobManager,则它会立即开始执行这个application。如果application被提交给了一个Dispatcher,或是Yarn RM,则它会启动一个JobManager,然后将application交给它,JobManager开始执行此应用。
2. 库(Library)模式
·在这个模式下,Flink Application 会被打包在一个container 镜像,例如一个Docker 镜像。此镜像包含了运行JobManager和ResourceManager的代码。当一个容器从镜像启动后,它会自动启动ResourceManager和JobManager,并提交打包好的应用。另一种方法是:将应用打包到镜像后,用于部署TaskManager容器。从此镜像启动的容器会自动启动一个TaskManager,它会连接ResourceManager并注册它的slots。一般来说,这些镜像的启动以及失败重启由一个外部的资源管理器管理(如Kubernetes)。
框架模式遵循了传统的提交任务到集群的方式。在库模式下,没有运行的Flink服务。它是将Flink作为一个库,与application一同打包到了一个容器镜像。这个部署模式在微服务架构中较为常见
任务执行
一个TaskManager可以同时执行多个任务。这些task可以是同一个operator(也就是数据并行)的、或是不同的operator(也就是task并行)的,亦或是另一个不同application的(job并行)一组tasks的子集。TaskManager提供了明确个数的processing slots,用于控制可以并行执行的任务数。一个slot可以执行application的一个分片(一个operator的一个并行task)。下图展示了TaskManager,slots,tasks以及operators之间的关系:
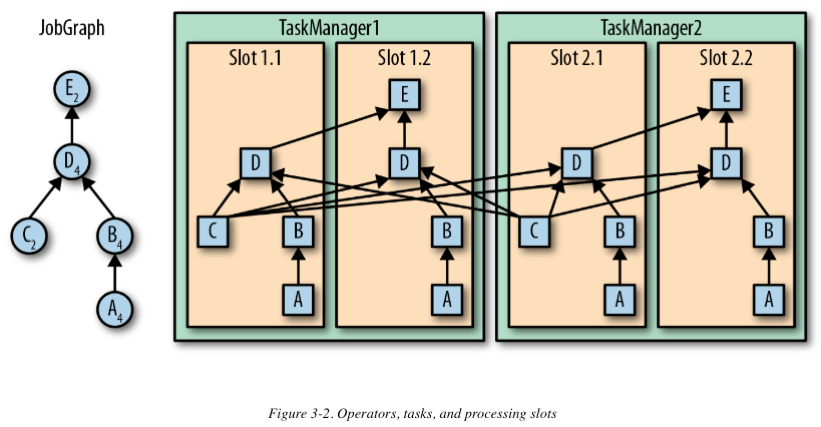
最左边是一个JobGraph – application的非并行表示,包含了5个operator。A和C是数据源,E是输出端(sink)。C和E有2个并行,其他的有4个并行。因为最高的并行度是4,所以应用需要至少四个slot执行任务。给定两个TaskManager,每个各有两个slot,这种情况下需求是满足的。JobManager将JobGraph转化为ExecutionGraph,并将任务分配到四个可用的slot上。对于有4个并行任务的operator,它的task会分配到每个slot上。对于有2个并行任务的operator C和E,它们的任务被分配到slot 1.1、2.1 以及 slot 1.2、2.2。将tasks调度到slots上,可以让多个tasks跑在同一个TaskManager内,也就可以是的tasks之间的数据交换更高效。然而将太多任务调度到同一个TaskManager上会导致TaskManager过载,继而影响效率。之后我们会讨论如何控制任务的调度。
TaskManager在同一个JVM中以多线程的方式执行任务。线程较进程会更轻量级,但是线程之间并没有非常严格的将任务互相隔离。所以,单个误操作的任务可能会kill掉整个TaskManager进程,以及运行在此进程上的所有任务。通过为每个TaskManager配置单独的slot,可以将application相互隔离。依赖于TaskManager内部的多线程,以及在一台实例上配置部署多个TaskManager,Flink可以为性能与资源隔离提供更灵活的权衡。
高可用设置
流应用一般设计为7 x 24 小时运行。所以很重要的一点是:即使在出现了进程挂掉的情况,应用仍需要继续保持执行。为了从故障恢复,系统需要重启进程、重启应用并恢复它的状态。接下来我们会介绍Flink如何重启失败的进程。
1. TaskManager 失败
正如前文提到,Flink需要足够数目的slot,以执行一个应用的所有任务。假设一个Flink配置有4个TaskManager,每个TM提供2个slot,则一个流程序最高可以以8个并行单位执行。如果其中一个TaskManager失败,可用的slots会降到6。在这种情况下,JobManager会要求ResourceManager提供更多的slots。如果此要求无法完成 - 例如应用跑在一个standalone集群 – JobManager在有足够的slots之前,无法重启此application。应用的重启逻辑决定了JobManager的重启频率,以及两次尝试之间的时间间隔。
2. JobManager失败
比TaskManager失败更严重的问题是JobManager失败。JM控制整个流应用的执行,并维护执行中的元数据,例如指向已完成的检查点的指针。若是对应的JobManager消失,则流程序无法继续运行。也就是说JobManager在Flink应用中是单点故障。为了克服这个问题,Flink支持高可用模式,在源JM消失后,可以将一个job的状态与元数据迁移到另一个JobManager,并继续执行。
Flink的高可用模式基于ZooKeeper。若是在HA模式下运行,则JobManager将JobGraph以及所有必须的metadata(例如应用的jar文件)写入到一个远程持久性存储系统中。此外,JM会写一个指针信息(指向存储位置)到Zookeeper的数据存储中。在执行一个application的过程中,JM接收每个独立task检查点的state句柄(也就是存储位置)。根据一个检查点的完成情况(当所有任务已经成功地将它们的state写入到远程存储), JobManager写入state句柄到远程存储,以及写入指针(指向远程存储的指针)到ZooKeeper。所以,所有需要(在一个JM失败后)被还原的信息被存储在远程存储,而ZooKeeper持有指向此存储位置的指针。下图描述了此设计:
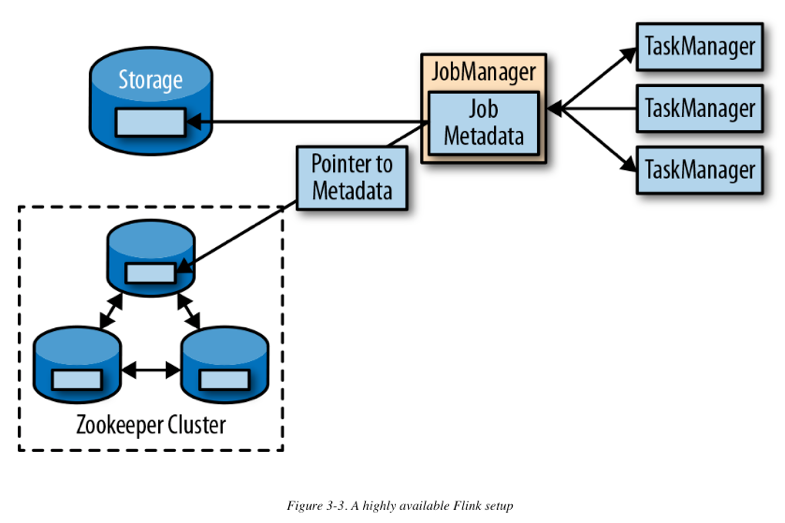
当一个JM失败,所有属于这个application的任务会自动取消。一个新的JM接管失败JM的工作,并执行以下操作:
1.从ZooKeeper请求存储位置(storage location),从远端存储获取JobGraph,Jar文件,以及application上次checkpoint的状态句柄(state handles)
2.从ResourceManager请求slots,以继续执行application
3.重启application并重制它所有的tasks到上一个完成了的checkpoint
当一个application是以库部署的形式运行(如Kubernetes),失败的JobManager或TaskManager 容器会由容器服务自动重启。当运行在YARN或Mesos之上时,JobManager或TaskManager进程会由Flink自动触发重启。在standalone模式下,Flink并未提供为失败进程重启的工具。所以次模式下可以运行一个standby JM和TM,用于接管失败的进程。
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019
Flink架构(一)- 系统架构的更多相关文章
- 【已转移】【Java架构:系统架构理论】一篇文章搞掂:RESTful
一.定义 1.起源 来源:Roy Fielding的博士论文. 目的:理解和评估以网络为基础的应用软件的架构设计,得到一个功能强.性能好.适宜通信的架构. 定义:一种实现软件通信的架构风格.设计风格, ...
- Android系统架构与系统源码目录
前言 技术博客终于可以恢复正常的更新速度了,原因是我编写的进阶书籍的初稿已经完成,窃以为它将会是Android应用书籍中最有深度的一本,可以说是<Android开发艺术探索>的姊妹篇.在这 ...
- Android之系统架构
Android 是Google开发的基于Linux平台的开源手机操作系统.它包括操作系统.用户界面和应用程序 —— 移动电话工作所需的全部软件,而且不存在任何以往阻碍移动产业创新的专有权障碍.Andr ...
- 【PaPaPa】系统架构搭建浅析 - 人人可以搭架构
声明 [PaPaPa]这个项目是以技术分享与研究为目的而做的,并非商业项目,所以更多的是提供一种思路,请勿直接在项目中使用. 上一篇隐藏开源项目地址实属无奈,为了寻找一起做这件事的同伴不得已刷了一天推 ...
- Android 笔记之 Android 系统架构
Android笔记之Android系统架构 h2{ color: #4abcde; } a{ color: blue; text-decoration: none; } a:hover{ color: ...
- Dubbo入门到精通学习笔记(七):基于Dubbo的分布式系统架构介绍(以第三方支付系统架构为例)、消息中间件的作用介绍
文章目录 架构简单介绍 消息中间件在分布式系统中的作用介绍 消息中间件的定义 消息中间件的作用 应用场景 JMS(Java Message Service) JMS消息模型 实现了JMS规范的消息中间 ...
- [开发笔记usbTOcan]系统架构设计
SYS.3 | 系统架构设计 系统架构设计过程的目的是建立一个系统体系结构设计,并确定哪些系统需求分配给系统的哪些元素,并根据确定的标准评估系统架构. 系统结构设计需要做一下工作: 开发系统架构设计. ...
- 汇总java生态圈常用技术框架、开源中间件,系统架构及经典案例等
转自:http://www.51testing.com/html/83/n-3718883.html 有人认为编程是一门技术活,要有一定的天赋,非天资聪慧者不能及也.非也,这是近几年,对于技术这碗饭有 ...
- 【Java进阶面试系列之一】哥们,你们的系统架构中为什么要引入消息中间件?
转: [Java进阶面试系列之一]哥们,你们的系统架构中为什么要引入消息中间件? **这篇文章开始,我们把消息中间件这块高频的面试题给大家说一下,也会涵盖一些MQ中间件常见的技术问题. 这里大家可以关 ...
随机推荐
- 使用_slots_变量限制class实例能添加的属性
如果我们想要限制实例的属性怎么办?比如,只允许对Student实例添加name和age属性. 那么我们在Student类里面增添_slots_变量 例如: class Student(object): ...
- AI 数学基础:概率分布,幂,对数
1.概率分布 参考: https://blog.csdn.net/ZZh1301051836/article/details/89371412 p 2.幂次的意义 物理理解:幂次描述的是指数型的变化 ...
- 使用git将本地项目上传至git仓库
个人博客 地址:https://www.wenhaofan.com/article/20190508220440 介绍 一般来说开发过程中都是先在git创建远程仓库,然后fetch到本地仓库,再进行c ...
- RHEL 8 安装 Oracle 19c 注意问题
RedHat Enterprise Linux 8 版本静默安装 Oracle 数据库软件时,需注意的问题 来自博客园AskScuti 1. 提示缺少库文件 libnsl.so.1 2. 因着OS版本 ...
- 南昌邀请赛B题(拉格朗日插值)
题目链接:https://nanti.jisuanke.com/t/40254 #include<iostream> #include<cstdio> #include< ...
- 优化公式排版和Beamer相关知识
做优化的同学可能会碰到排列形如 max ******* s.t. ***** = * ***** > *** ... 的格式 既要要求 max 和 s ...
- Unknown CMake command "check_symbol_exists".
- Using these message generators: gencpp;geneus;genlisp;gennodejs;genpyCMake Error at CMakeLists.txt ...
- Jenkins +Ant +Jmeter(apache-jmeter-5.1.1)自动化性能测试平台
1.安装配置好Jdk, 下载网址:https://www.cr173.com/soft/33894.html 2.Jmeter下载地址:http://jmeter.apache.org/downloa ...
- [CF1304C] Air Conditioner
维护一区间 \([l,r]\) 人按照时间升序 考虑 \((l_i, h_i, t_i)\),当前的所有区间与这个区间取交 推到 \(t_{i+1}\) 时,所有区间的端点向两边扩张即可 注意把空掉的 ...
- JFinal获取多个model
个人博客 地址:http://www.wenhaofan.com/article/20180930112646 由于jfinal框架自身没有实现获取多个同一类型的Model的方法,导致获取ModelL ...