Python3标准库:copy复制对象
1. copy复制对象
copy模块包括两个函数copy()和deepcopy(),用于复制现有的对象。
1.1 浅副本
copy()创建的浅副本(shallow copy)是一个新容器,其中填充了原对象内容的引用。建立list对象的一个浅副本时,会构造一个新的list,并将原对象的元素追加到这个list。
import copy
import functools @functools.total_ordering
class MyClass: def __init__(self, name):
self.name = name def __eq__(self, other):
return self.name == other.name def __gt__(self, other):
return self.name > other.name a = MyClass('a')
my_list = [a]
dup = copy.copy(my_list) print(' my_list:', my_list)
print(' dup:', dup)
print(' dup is my_list:', (dup is my_list))
print(' dup == my_list:', (dup == my_list))
print('dup[0] is my_list[0]:', (dup[0] is my_list[0]))
print('dup[0] == my_list[0]:', (dup[0] == my_list[0]))
作为一个浅副本,并不会复制MyClass实例,所以dup列表中的引用会指向my_list中相同的对象。

1.2 深副本
deepcopy()创建的深副本是一个新容器,其中填充了原对象内容的副本。要建立一个list的深副本,会构造一个新的list,复制原列表的元素,然后将这些副本追加到新列表。
将前例中的copy()调用替换为deepcopy(),可以清楚地看出输出的不同。
import copy
import functools @functools.total_ordering
class MyClass: def __init__(self, name):
self.name = name def __eq__(self, other):
return self.name == other.name def __gt__(self, other):
return self.name > other.name a = MyClass('a')
my_list = [a]
dup = copy.deepcopy(my_list) print(' my_list:', my_list)
print(' dup:', dup)
print(' dup is my_list:', (dup is my_list))
print(' dup == my_list:', (dup == my_list))
print('dup[0] is my_list[0]:', (dup[0] is my_list[0]))
print('dup[0] == my_list[0]:', (dup[0] == my_list[0]))
列表的第一个元素不再是相同的对象引用,不过比较这两个对象时,仍认为它们是相等的。

1.3 定制复制行为
可以使用特殊方法__copy__()和__deepcopy__()来控制如何建立副本。
调用__copy__()而不提供任何参数,这会返回对象的一个浅副本。
调用__deepcopy__(),并提供一个备忘字典,这会返回对象的一个深副本。所有需要深复制的成员属性都要连同备忘字典传递到copy.deepcopy()以控制递归(备忘字典将在后面更详细地解释)。
import copy
import functools @functools.total_ordering
class MyClass: def __init__(self, name):
self.name = name def __eq__(self, other):
return self.name == other.name def __gt__(self, other):
return self.name > other.name def __copy__(self):
print('__copy__()')
return MyClass(self.name) def __deepcopy__(self, memo):
print('__deepcopy__({})'.format(memo))
return MyClass(copy.deepcopy(self.name, memo)) a = MyClass('a') sc = copy.copy(a)
dc = copy.deepcopy(a)
备忘字典用于跟踪已复制的值,以避免无限递归。
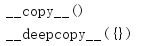
1.4 深副本中的递归
为了避免复制递归数据结构可能带来的问题,deepcopy()使用了一个字典来跟踪已复制的对象。将这个字典传入__deepcopy__()方法,这样在该方法中也可以检查这个字典。
import copy
class Graph:
def __init__(self, name, connections):
self.name = name
self.connections = connections
def add_connection(self, other):
self.connections.append(other)
def __repr__(self):
return 'Graph(name={}, id={})'.format(
self.name, id(self))
def __deepcopy__(self, memo):
print('\nCalling __deepcopy__ for {!r}'.format(self))
if self in memo:
existing = memo.get(self)
print(' Already copied to {!r}'.format(existing))
return existing
print(' Memo dictionary:')
if memo:
for k, v in memo.items():
print(' {}: {}'.format(k, v))
else:
print(' (empty)')
dup = Graph(copy.deepcopy(self.name, memo), [])
print(' Copying to new object {}'.format(dup))
memo[self] = dup
for c in self.connections:
dup.add_connection(copy.deepcopy(c, memo))
return dup
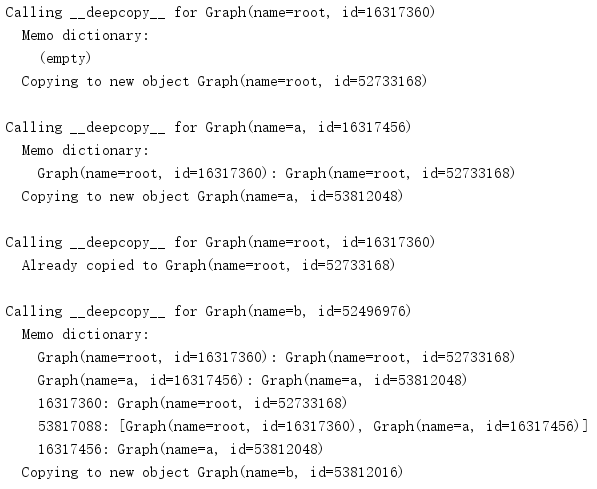
root = Graph('root', [])
a = Graph('a', [root])
b = Graph('b', [a, root])
root.add_connection(a)
root.add_connection(b)
dup = copy.deepcopy(root)
Graph类包含一些基本的有向图方法。可以利用一个名和一个列表(包含已连接的现有节点)初始化一个graph实例。add_connection()方法用于建立双向连接。深复制操作符也用到了这个方法。
__deepcopy__()方法将打印消息来显示这个方法是如何调用的,并根据需要管理备忘字典内容。它不是复制整个连接列表,而是创建一个新列表,再把各个连接的副本追加到这个列表。这样可以确保复制各个新节点时会更新备忘字典,而避免递归问题或多于的节点副本。与前面一页,完成时会返回复制的对象。
Python3标准库:copy复制对象的更多相关文章
- Python3标准库:weakref对象的非永久引用
1. weakref对象的非永久引用 weakref模块支持对象的弱引用.正常的引用会增加对象的引用数,并避免它被垃圾回收.但结果并不总是如期望中的那样,比如有时可能会出现一个循环引用,或者有时需要内 ...
- 7.Python3标准库--文件系统
''' Python的标准库中包含大量工具,可以处理文件系统中的文件,构造和解析文件名,还可以检查文件内容. 处理文件的第一步是要确定处理的文件的名字.Python将文件名表示为简单的字符串,另外还提 ...
- Python3 标准库
Python3标准库 更详尽:http://blog.csdn.net/jurbo/article/details/52334345 文本 string:通用字符串操作 re:正则表达式操作 diff ...
- 8.Python3标准库--数据持久存储与交换
''' 持久存储数据以便长期使用包括两个方面:在对象的内存中表示和存储格式之间来回转换数据,以及处理转换后数据的存储区. 标准库包含很多模块可以处理不同情况下的这两个方面 有两个模块可以将对象转换为一 ...
- 比较两个文件的异同Python3 标准库difflib 实现
比较两个文件的异同Python3 标准库difflib 实现 对于要比较两个文件特别是配置文件的差异,这种需求很常见,如果用眼睛看,真是眼睛疼. 可以使用linux命令行工具diff a_file b ...
- 1.Python3标准库--前戏
Python有一个很大的优势便是在于其拥有丰富的第三方库,可以解决很多很多问题.其实Python的标准库也是非常丰富的,今后我将介绍一下Python的标准库. 这个教程使用的书籍就叫做<Pyth ...
- python023 Python3 标准库概览
Python3 标准库概览 操作系统接口 os模块提供了不少与操作系统相关联的函数. >>> import os >>> os.getcwd() # 返回当前的工作 ...
- python3标准库总结
Python3标准库 操作系统接口 os模块提供了不少与操作系统相关联的函数. ? 1 2 3 4 5 6 >>> import os >>> os.getcwd( ...
- 3.Python3标准库--数据结构
(一)enum:枚举类型 import enum ''' enum模块定义了一个提供迭代和比较功能的枚举类型.可以用这个为值创建明确定义的符号,而不是使用字面量整数或字符串 ''' 1.创建枚举 im ...
随机推荐
- 【实战】使用 Kettle 工具将 mysql 数据增量导入到 MongoDB 中
最近有一个将 mysql 数据导入到 MongoDB 中的需求,打算使用 Kettle 工具实现.本文章记录了数据导入从0到1的过程,最终实现了每秒钟快速导入约 1200 条数据.一起来看吧~ 一.K ...
- 美食家App开发日记5
今天将ListView控件用更强大的Recyclerview控件取代,最后调试了程序. 感觉Android编程难度实在是远远高于javaweb,初次接触,感觉有很多东西想实现,想得很容易,但是实现起来 ...
- 第二阶段冲刺个人任务——seven
今日任务: 整体运行测试上传到公网上的程序. 昨日成果: 搭建网络服务器,上传数据库及程序.
- c语言秋季作业3
本周作业头 这个作业属于那个课程 C语言程序设计II 这个作业要求在哪里 作业链接 我在这个课程的目标是 运用C语言编程解决一些简单的数学问题 这个作业在那个具体方面帮助我实现目标 学习if else ...
- Spring AOP源码分析--代理方式的选择
能坚持别人不能坚持的,才能拥有别人未曾拥有的.关注编程大道公众号,让我们一同坚持心中所想,一起成长!! 年前写了一个面试突击系列的文章,目前只有redis相关的.在这个系列里,我整理了一些面试题与大家 ...
- 暑假第四周总结(HDFS编程实践,安装HBASE)
本周根据书上以及教程的提示,对HDFS进行了编程实践,将教程所给的代码(判断文件是否存在,创建文件,读取文件)进行了应用,根据视频的讲解,对一些简单的语句有了一定的了解,但还是比较生疏.另外还根据提示 ...
- selenium8中元素定位方式
Selenium对网页的控制是基于各种前端元素的,在使用过程中,对于元素的定位是基础,只有准去抓取到对应元素才能进行后续的自动化控制,我在这里将对各种元素定位方式进行总结归纳一下. 这里将统一使用百度 ...
- nginx命令行及演示:重载、热部署、日志切割
重载配置文件 nginx -s reload 热部署(升级nginx) 首先备份二进制文件 cp nginx nginx.old 拷贝新版本的nginx替换以前的nginx二进制文件 cp ngi ...
- 用tensorflow搭建RNN(LSTM)进行MNIST 手写数字辨识
用tensorflow搭建RNN(LSTM)进行MNIST 手写数字辨识 循环神经网络RNN相比传统的神经网络在处理序列化数据时更有优势,因为RNN能够将加入上(下)文信息进行考虑.一个简单的RNN如 ...
- DD boost你值得拥有
也不知道什么时候就被赶到这条路上来了,只听领导的一声令下,备份啊能不能在异地也存一份呀?? 啊?? 领导语重心长的说你看啊,我们这个备份是这个样子的 现在的南京的两个工厂备份要在对方留一份备份的存档, ...