scrapy的使用--Rcrapy-Redis
Scrapy-Redis分布式爬虫组件
Scrapy是一个框架,他本身是不支持分布式的。如果我们想要做分布式的爬虫。就需要借助一个组件叫做Scrapy-Redis。这个组件正式利用了Redis可以分布式的功能,继承到Scrapy框架中,使得爬虫可以进行分布式,可以充分的利用资源(多个ip,更多带宽,同步爬取)来提高爬虫的爬取效率。
-分布式爬虫组件的优点:
1.可以充分利用多台机器的带宽
2.可以充分利用多台机器的ip地址
3.多台机器工作,io频率提高,爬取效率更高
-分布式爬虫需要解决的问题:
1.分布式爬虫是好几个台式机器在同时运行,保证不同的机器爬取页面的时候不会出现重复爬取的问题。
2.同样,分布式爬虫在不同的机器上运行,在把数据爬取完后如何保存在同一个地方。
Scrapy 框架图
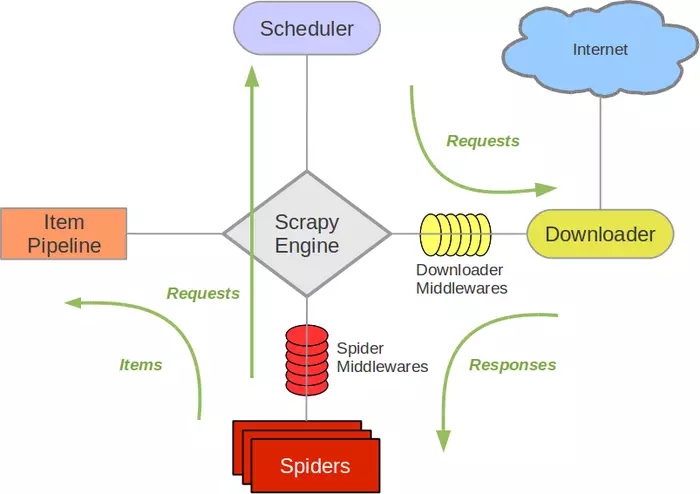
Scrapy-Redis
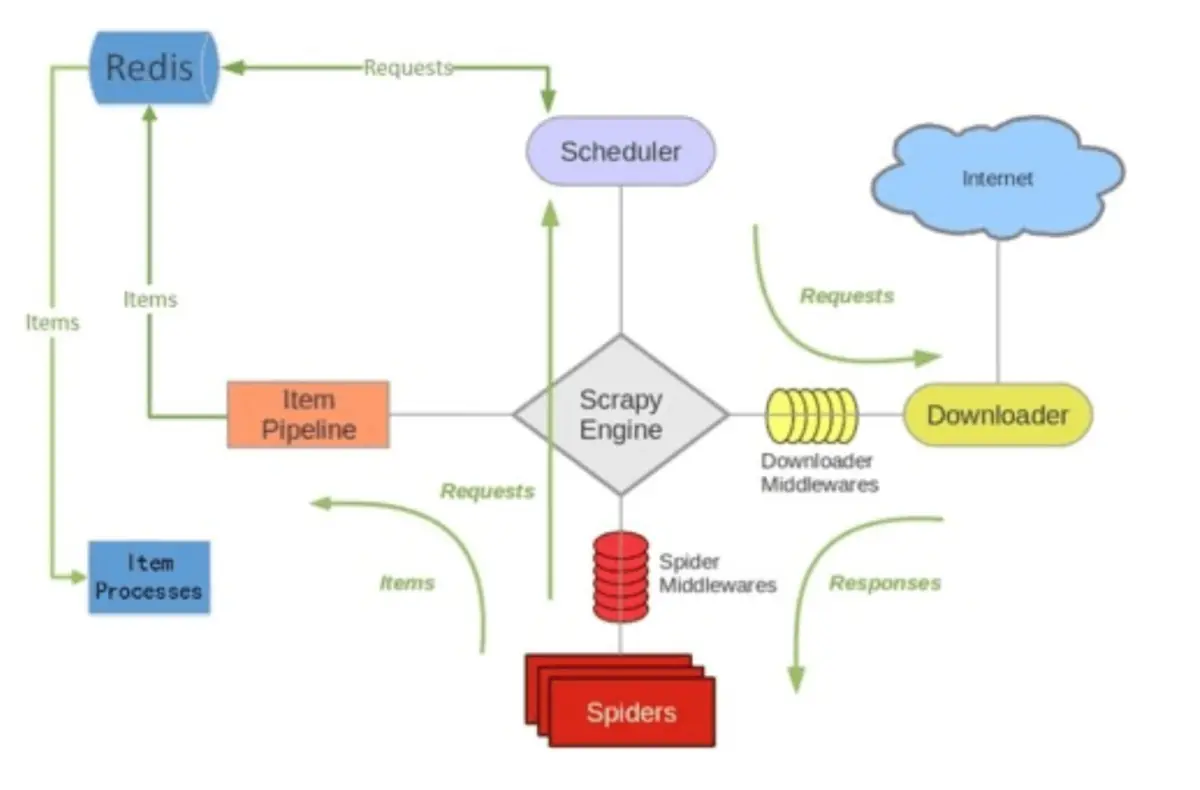
-分布式架构图:
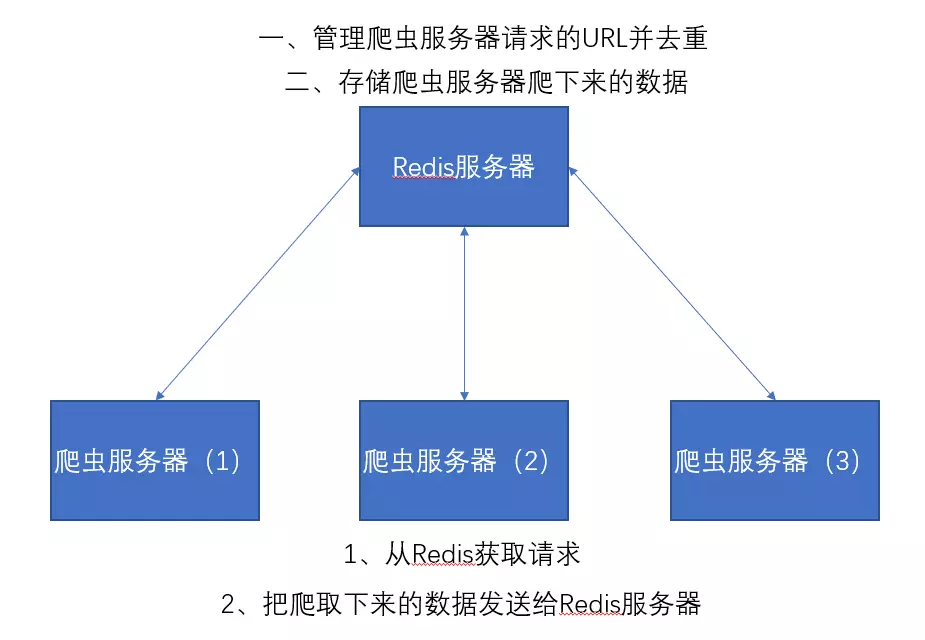
Redis教程:
概述
redis是一种支持分布式的nosql数据库,他的数据是深存在内存中,同时可以将数据持久化,并且他比memcached 支持更多的数据结构(string,list,set,sorted set(有序集合),hash(hash)
redis使用的场景:
1.登录会话存储在redis中。memcached(缓存)
2.作为消息队列,‘celary’使用redis作为中间人(消息队列)
3.排行版/计数器:比如一些秀场类的项目,经常会有一些钱多少名的主播排名,或者点赞数之类的(计数器)
4. 当前在线人数,会显示当前系统多少在线人数。
5.一些常用的数据缓存:一些论坛,模块不会经常变化。但是每次访问首页都要从MySQL中获取,可以在redis中缓存起来,不用每次请求数据库。
6.把前200篇文章缓存或者评论缓存;一般用户浏览网站,只会浏览前面一部分文章或者评论,那么可以把前面200篇文章和对应的评论缓存起来,用户访问超时的,就访问数据库,并且以后文章超过200篇,则把之前的文章删除。
7.好友关系,微博的好友关系使用redis实现。
8.发布和订阅功能,可以用来聊天软件
具体分布式区别:https://www.cnblogs.com/457248499-qq-com/p/7392653.html
scrapy的使用--Rcrapy-Redis的更多相关文章
- scrapy与redis分布式组件
Scrapy 和 scrapy-redis的区别 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础 ...
- Scrapy 和 scrapy-redis的区别
Scrapy 和 scrapy-redis的区别 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础 ...
- scrapy入门与进阶
Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非 ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- scrapy实战2分布式爬取lagou招聘(加入了免费的User-Agent随机动态获取库 fake-useragent 使用方法查看:https://github.com/hellysmile/fake-useragent)
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- scrapy基础知识之 Scrapy 和 scrapy-redis的区别:
Scrapy 和 scrapy-redis的区别 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础 ...
- 浅析scrapy与scrapy_redis区别
最近在工作中写了很多 scrapy_redis 分布式爬虫,但是回想 scrapy 与 scrapy_redis 两者区别的时候,竟然,思维只是局限在了应用方面,于是乎,搜索了很多相关文章介绍,这才搞 ...
- scrapy架构流程
1.爬虫spiders将请求通过引擎传递给调度器scheduler 2.scheduler有个请求队列,在请求队列中拿出请求给下载器,downloader 3.downloader从Internet的 ...
- 浅析scrapy与scrapy-redis的区别
首先,要了解两者的区别,就要清楚scrapy-redis是如何产生的,有需求才会有发展,社会在日新月异的飞速发展,大量相似网页框架的飞速产生,人们已经不满足于当前爬取网页的速度,因此有了分布式爬虫,让 ...
- Scrapy-redis 分布式
分布式:架构方式 多台真实机器+爬虫(如requests,scrapy等)+任务共享中心 多台虚拟机器(或者部分虚拟部分真实)+爬虫(如requests,scrapy等)+任务共享中心 多台容器级虚拟 ...
随机推荐
- struct and union example
1. StructHandler.c: /* * StructHandler.c * * Created on: Jul 6, 2013 * Author: wangle */#inclu ...
- 破解极验(geetest)验证码
破解极验(geetest)验证码 这是两年前的帖子: http://www.v2ex.com/t/138479 一个月前的破解程序,我没用过 asp.net ,不知道是不是真的破解了, demo ...
- 使用python发送163邮件 qq邮箱
使用python发送163邮件 def send_email(title, content): import smtplib from email.mime.multipart import MIME ...
- (15)centos7 系统服务
centos7 服务启动脚本在 /usr/lib/systemd目录下 1.服务基本操作指令 systemclt [command] [unit] #其中command包括: #start 立即启动 ...
- 【react】---Hooks的基本使用---【巷子】
一.react-hooks概念 React中一切皆为组件,React中组件分为类组件和函数组件,在React中如果需要记录一个组件的状态的时候,那么这个组件必须是类组件.那么能否让函数组件拥有类组件的 ...
- 第十五章 例行性工作(crontab)--循环执行的例行性工作调度 crontab(定时任务)
循环执行的例行性工作调度 crontab(定时任务) 15.1 例行性工作调度 不考虑硬件与服务器的链接状态,Linux帮助提醒很多任务. Linux例行性工作是如何进行调度的? Linux调度就是通 ...
- 牛客练习赛51 B 子串查询 https://ac.nowcoder.com/acm/contest/1083/B
题目描述 给出一个长度为n的字符串s和q个查询.对于每一个查询,会输入一个字符串t,你需要判断这个字符串t是不是s的子串.子串的定义就是存在任意下标a<b<c<d<e,那么”s ...
- Redis数据结构之快速列表-quicklist
链表 在Redis的早期版本中,存储list列表结构时,如果元素少则使用压缩列表ziplist,否则使用双向链表linkedlist // 链表节点 struct listNode<T> ...
- k小子串 SPOJ - SUBLEX 2
题意: 求字典序第K大的子串 题解: 先求出后缀自动机对应节点 // 该节点后面所形成的自字符串的总数 然后直接模拟即可 #include <set> #include <map&g ...
- MySQL日期格式化 利用Mysql的DATE_FORMAT()进行日期格式转换
碰到一个MYSQL的问题,表logstatb中moment字段的内容是"年-月-日 时:分:秒",需要查询匹配“年月日”或“时:分:秒”即可的数据条目,这个时候就可以通过下面的SQ ...