Hive学习路线图--张丹老师
前言
Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作。就是这一个点,解决了原数据分析人员对于大数据分析的瓶颈。
让我们把Hive的环境构建起来,帮助非开发人员也能更好地了解大数据。
目录
- Hive介绍
- Hive学习路线图
- 我的使用经历
- Hive的使用案例
1. Hive介绍
Hive起源于Facebook,它使得针对Hadoop进行SQL查询成为可能,从而非程序员也可以方便地使用。Hive是基于Hadoop的一 个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
详细地Hive的安装和使用介绍,请参考文章:Hive安装及使用攻略
2. Hive学习路线图
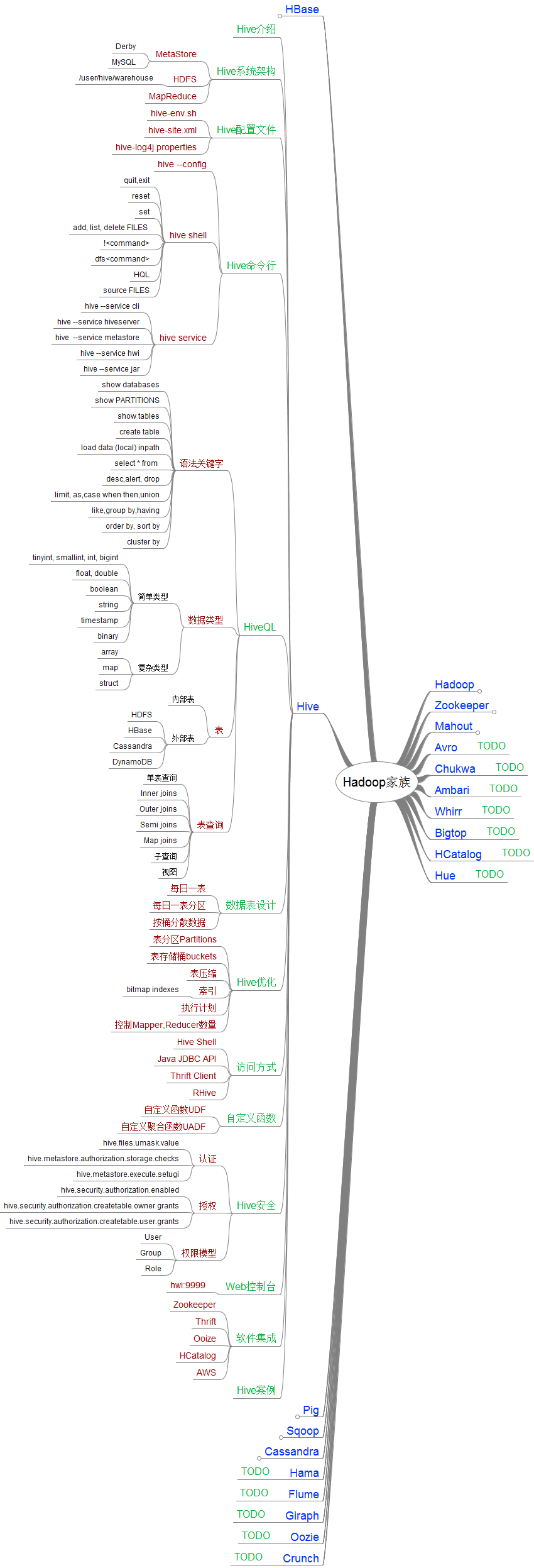
Hive的知识点,我已经列在图中,希望帮助其他人更好的了解Hive。
接下来,是我的使用经历,谁都没有捷径。把心踏实下来,就不那么难了。
3. 我的使用经历
我使用Hive有两个考虑:
- 1. 帮助无开发经验的数据分析人员,有能力处理大数据
- 2. 构建标准化的MapReduce开发过程
1). 帮助无开发经验的数据分析人员,有能力处理大数据
完全符合与Hive的设计理念,一直在强调,无需多言。
2). 构建标准化的MapReduce开发过程
这个方面是我们需要努力的方向。
首先,Hive已经用类SQL的语法封装了MapReduce过程,这个封装过程就是MapReduce的标准化的过程。
我们在做业务或者工具时,会针对场景用逻辑封装,这是第二层封装是在Hive之上的封装。在第二层封装时,我们要尽可能多的屏蔽Hive的细节,让接口单一化,低少灵活性,再次精简HQL的语法结构。只满足我们的系统要求,专用的接口。
在使用二次封装的接口时,我们已经可以不用知道Hive是什么, 更不用知道Hadoop是什么。我们只需要知道,SQL查询(SQL92标准),怎么写效率高,怎么写可以完成业务需要就可以了。
当我们完成了Hive的二次封装后,我们可以构建标准化的MapReduce开发过程。
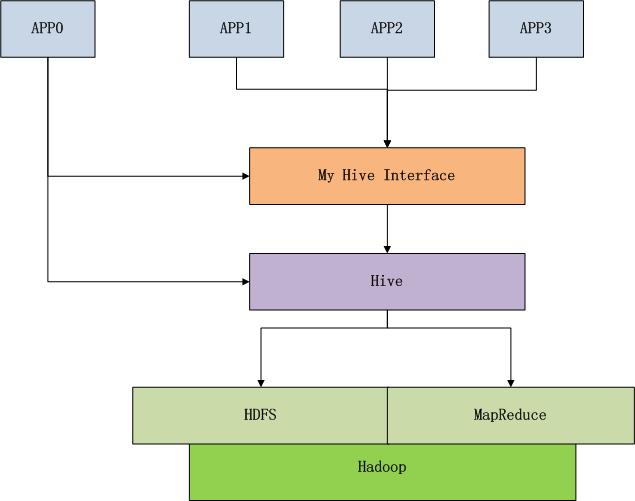
通过上图的思路,我们可以统一企业内部各种应用对于Hive的依赖,并且当人员素质升高后,有可以剥离Hive,用更优秀的底层解决方案来替换,如果封装的接口的不变,甚至替换Hive时业务使用都不知道,我们已经替换了Hive。
这个过程是需要经历的,也是有意义的。当我在考虑构建Hadoop分析工具时,以Hive作为Hadoop访问接口是最有效的。
3). 有关Hive的运维:
因为Hive是基于Hadoop构建的,简单地说就是一套Hadoop的访问接口,Hive本身并没有太多的东西,所以运维上面我们注意下面几个问题就行了。
- 1. 使用单独的数据库存储元数据
- 2. 定义合理的表分区和键
- 3. 设置合理的bucket数据量
- 4. 进行表压缩
- 5. 定义外部表使用规范
- 6. 合理的控制Mapper, Reducer数量
Hive学习路线图--张丹老师的更多相关文章
- Mahout学习路线图-张丹老师
前言 Mahout是Hadoop家族中与众不同的一个成员,是基于一个Hadoop的机器学习和数据挖掘的分布式计算框架.Mahout是一个跨学科产品,同时也是我认为Hadoop家族中,最有竞争力,最难掌 ...
- Hadoop家族学习路线图-张丹老师
前言 使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了.Hadoop在大数据领域的成功,更引发了它本身的加速发展.现 ...
- Hive学习路线图(转)
Hadoophivehqlroadmap学习路线图 1 Comment Hive学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig ...
- 【转】Hive学习路线图
原文博客出自于:http://blog.fens.me/hadoop-hive-roadmap/ 感谢! Hive学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Ha ...
- Hive学习路线图
- Hadoop家族学习路线图--转载
原文地址:http://blog.fens.me/hadoop-family-roadmap/ Sep 6, 2013 Tags: Hadoophadoop familyroadmap Comment ...
- Hadoop学习路线图
Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括, ...
- Hadoop家族学习路线图
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- Hadoop家族学习路线图v
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
随机推荐
- Unix系统编程(一)
主要内容:文件输入/输出的系统调用. 在Linux中,万事万物皆文件. 文件描述符的概念 通用I/O模型的系统调用: 打开文件 open 关闭文件 close 向文件写数据 write 从文件读数据 ...
- 关于selenium IDE找不到元素bug
使用 selenium IDE 录制脚本,经常会发生 这样一种错误. 页面上,明明存在这个元素,就是找不到. 其实原理很简单 , 按钮 点击,没有时间延迟,但是页面加载,需要一段时间. 页面元素还 ...
- redux-effect
npm install --save redux-effect 通过redux中间件的方式使async方法可以在redux中使用. 如果你使用redux-saga,应该非常容易上手redux-effe ...
- 学习正则 - golang实现
元字符: 表1.常用的元字符 代码 说明 . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线或汉字 \s 匹配任意的空白符 \d 匹配数字 \b 匹配单词的开始或结束 ^ 匹配字符串的开始 ...
- iframe宽高百分百显示
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- java 利用同步工具类控制线程
前言 参考来源:<java并发编程实战> 同步工具类:根据工具类的自身状态来协调线程的控制流.通过同步工具类,来协调线程之间的行为. 可见性:在多线程环境下,当某个属性被其他线程修改后,其 ...
- Java WEB 之页面间传递特殊字符
本文是学习网络上的文章时的总结以及自己的一点实践.感谢大家无私的分享. 昨天在做项目的时候,有一个页面间传递特殊字符的需求,查了一些资料.如今将自己的经验写出来. 首先.在前台编码 var fckPu ...
- [ppurl]从”皮皮书屋”下载电子书的姿势
(欢迎转载,转载请注明出处:http://blog.csdn.net/hcbbt/article/details/42072545) 写在前面的扯皮 为什么标题的"皮皮书屋"加上了 ...
- Install EPEL repo on CentOS 7 / RHEL 7
On CentOS 7, we have found without downloading the epel-release RPM package(as we used to do on prev ...
- hdu 4289(最小割)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4289 思路:求最小花费,最小割应用,将点权转化为边权,拆点,(i,i+n)之间连边,容量为在城市i的花 ...