基于tcp协议的粘包问题(subprocess、struct)
要点:
- 报头 固定长度bytes类型
1、粘包现象
粘包就是在获取数据时,出现数据的内容不是本应该接收的数据,如:对方第一次发送hello,第二次发送world,
我放接收时,应该收两次,一次是hello,一次是world,但事实上是一次收到helloworld,一次收到空,这种现象
叫粘包
只有TCP有粘包现象,TCP协议是面向流的协议,这也是容易出现粘包问题的原因。例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束。所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
2、两种情况下会发生粘包。
发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
3.粘包的解决
是通过设置报头,在传信息之前,先把该信息的报头传给对方,在传该信息,就不会出现粘包
报头是一个字典,它含有信息的大小,还有可以有文件的名称,文件的hash值,如下
head_dic={'size':len(data),'filename':filenaem,'hash':hash值},如果还有,可以继续在字典中加
1、基于远程执行命令的程序
需要用到subprocess模块
服务端
#1、执行客户端发送的指令
import socket
import subprocess
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.bind(('127.0.0.1',8090))
phone.listen(5)
while True:
conn,addr=phone.accept()
print('IP:%s PORT:%s' %(addr[0],addr[1]))
while True:
try:
cmd=conn.recv(1024)
if not cmd:break
#执行命令
obj=subprocess.Popen(cmd.decode('utf-8'),shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
conn.send(stdout+stderr)
except Exception:
break
conn.close()
phone.close()
客户端:
import socket
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',8090))
while True:
cmd=input('>>:').strip()
if not cmd:continue
phone.send(cmd.encode('utf-8'))
res=phone.recv(1024)
print(res.decode('gbk'))
phone.close()
注意注意注意:
res=subprocess.Popen(cmd.decode('utf-8'),
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE)
的结果的编码是以当前所在的系统为准的,如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码,且只能从管道里读一次结果。
subprocess模块
从python2.4版本开始,可以用subprocess这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。
subprocess意在替代其他几个老的模块或者函数,比如:os.system os.spawn* os.popen* popen2.* commands.*
subprocess模块定义了一个类: Popen
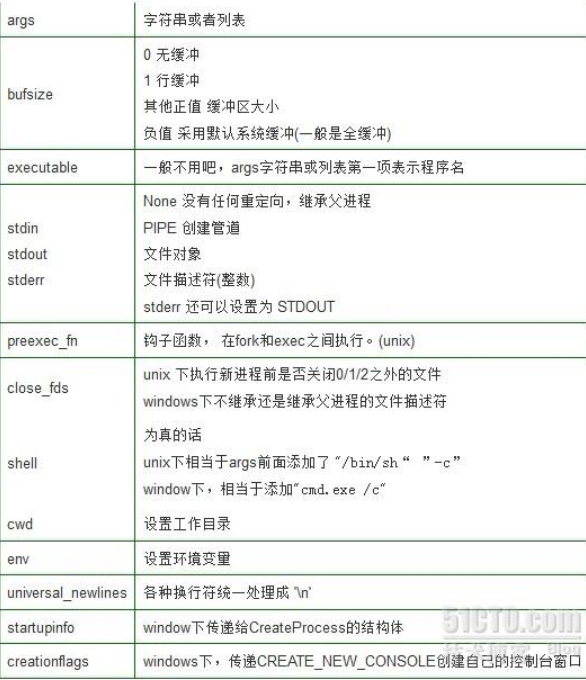
class subprocess.Popen( args,
bufsize=0,
executable=None,
stdin=None,
stdout=None,
stderr=None,
preexec_fn=None,
close_fds=False,
shell=False,
cwd=None,
env=None,
universal_newlines=False,
startupinfo=None,
creationflags=0)
struct模块
struct.pack(fmt, v1, v2, ...)
struct.pack用于将Python的值根据格式符,转换为字符串,准确来说是Byte。
Python3内的unicode和bytes,在Py3内文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。
Py2是没有Byte这么个东西的。参数fmt是格式字符串,v1, v2, ...表示要转换的python值
struct.unpack(fmt, buffer)
struct.unpack做的工作刚好与struct.pack相反,用于将字节流转换成python数据类型。它的函数原型为:struct.unpack(fmt, string),该函数返回一个tuple。
struct.calcsize(fmt)
struct.calcsize用于计算格式字符串所对应的结果的长度,如:struct.calcsize('ii'),返回8。因为两个int类型所占用的长度是8个字节。

import struct #帮我们把数字转成固定长度的bytes类型
res=struct.pack('i',123123)
print(res,len(res)) # b'\xf3\xe0\x01\x00' 4 res1=struct.unpack('i',res)
print(res1[0]) #
格式符"i"表示转换为int,'ii'表示有两个int变量。进行转换后的结果长度为8个字节(int类型占用4个字节,两个int为8个字节)
import struct
res=struct.pack('ii',1220,520)
print(res,len(res)) # b'\xc4\x04\x00\x00\x08\x02\x00\x00' 8
小端:较高的有效字节存放在较高的存储器地址,较低的有效字节存放在较低的存储器地址。
大端:较高的有效字节存放在较低的存储器地址,较低的有效字节存放在较高的存储器地址。
采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
res=struct.pack('>ii',1220,520)
print(res,len(res)) # b'\x00\x00\x04\xc4\x00\x00\x02\x08' 8 大端保存
res=struct.pack('<ii',1220,520)
print(res,len(res)) # b'\xc4\x04\x00\x00\x08\x02\x00\x00' 8 小端保存
解决粘包问题
办法1
服务端
import subprocess
import struct
from socket import *
server=socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8084))
# print(server)
server.listen(5)
while True:
conn,addr=server.accept()
# print(conn)
print(addr)
while True:
try:
cmd=conn.recv(8096)
if not cmd:break #针对linux #执行命令
cmd=cmd.decode('utf-8')
#调用模块,执行命令,并且收集命令的执行结果,而不是打印
obj = subprocess.Popen(cmd, shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
#第一步:制作报头:
total_size=len(stdout)+len(stderr) header=struct.pack('i',total_size)
#第二步:先发报头(固定长度)
conn.send(header) #第三步:发送命令的结果
conn.send(stdout)
conn.send(stderr)
except ConnectionResetError:
break
conn.close() server.close()
客户端
import struct
from socket import * client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8084)) while True:
cmd=input('>>: ').strip()
if not cmd:continue
client.send(cmd.encode('utf-8')) #第一步:收到报头
header=client.recv(4)
total_size=struct.unpack('i',header)[0] #第二步:收完整真实的数据
recv_size=0
res=b''
while recv_size < total_size:
recv_data=client.recv(1024)
res+=recv_data
recv_size+=len(recv_data)
print(res.decode('gbk')) client.close()
由于模块struct的pack方法中使用的i类型存在整数无限大时会出现报错的弊端,故提出如下解决方案:
办法二(终极版)
服务端
import subprocess
import struct
import json
from socket import *
server=socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8086))
# print(server)
server.listen(5)
while True:
conn,addr=server.accept()
# print(conn)
print(addr)
while True:
try:
cmd=conn.recv(8096)
if not cmd:break #针对linux #执行命令
cmd=cmd.decode('utf-8')
#调用模块,执行命令,并且收集命令的执行结果,而不是打印
obj = subprocess.Popen(cmd, shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
stdout=obj.stdout.read()
stderr=obj.stderr.read() # 1:先制作报头,报头里放:数据大小, md5, 文件
header_dic = {
'total_size':len(stdout)+len(stderr),
'md5': 'xxxxxxxxxxxxxxxxxxx',
'filename': 'xxxxx',
'xxxxx':''
}
header_json = json.dumps(header_dic)
header_bytes = header_json.encode('utf-8')
header_size = struct.pack('i', len(header_bytes)) # 2: 先发报头的长度
conn.send(header_size) # 3:先发报头
conn.send(header_bytes) # 4:再发送真实数据
conn.send(stdout)
conn.send(stderr)
except ConnectionResetError:
break
conn.close() server.close()
客户端
import struct
import json
from socket import * client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8086)) while True:
cmd=input('>>: ').strip()
if not cmd:continue
client.send(cmd.encode('utf-8')) # 1:先收报头长度
obj = client.recv(4)
header_size = struct.unpack('i', obj)[0] # 2:先收报头,解出报头内容
header_bytes = client.recv(header_size)
header_json = header_bytes.decode('utf-8')
header_dic = json.loads(header_json) print(header_dic)
total_size = header_dic['total_size'] # 3:循环收完整数据
recv_size=0
res=b''
while recv_size < total_size:
recv_data=client.recv(1024)
res+=recv_data
recv_size+=len(recv_data)
print(res.decode('gbk')) client.close()
能下载视频
服务端
import subprocess
import struct
import json
import os
from socket import *
server=socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8087))
# print(server)
server.listen(5)
def get(filename):
# 1:先制作报头,报头里放:数据大小, md5, 文件
header_dic = {
'total_size': os.path.getsize(filename),
'md5': 'xxxxxxxxxxxxxxxxxxx',
'filename': 'xxxxx',
'xxxxx': ''
}
header_json = json.dumps(header_dic)
header_bytes = header_json.encode('utf-8')
header_size = struct.pack('i', len(header_bytes)) # 2: 先发报头的长度
conn.send(header_size) # 3:先发报头
conn.send(header_bytes) # 4:再发送真实数据
with open(filename,'rb') as f:
for line in f:
conn.send(line) while True:
conn,addr=server.accept()
# print(conn)
print(addr)
while True:
try:
cmd=conn.recv(8096) #get C:\\a.txt
if not cmd:break #针对linux cmd,filename=cmd.split()
if cmd == 'get':
get(filename)
except ConnectionResetError:
break
conn.close() server.close()
客户端
import struct
import json
from socket import * client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8087)) while True:
cmd=input('>>: ').strip()
if not cmd:continue
client.send(cmd.encode('utf-8')) # 1:先收报头长度
obj = client.recv(4)
header_size = struct.unpack('i', obj)[0] # 2:先收报头,解出报头内容
header_bytes = client.recv(header_size)
header_json = header_bytes.decode('utf-8')
header_dic = json.loads(header_json) print(header_dic)
total_size = header_dic['total_size']
filename = header_dic['filename']
md5 = header_dic['md5'] # 3:循环收完整数据
recv_size=0
with open(filename,'wb') as f:
while recv_size < total_size:
recv_data=client.recv(1024)
f.write(recv_data)
recv_size+=len(recv_data) client.close()
基于tcp协议的粘包问题(subprocess、struct)的更多相关文章
- 基于tcp协议下粘包现象和解决方案,socketserver
一.缓冲区 每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区.write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送 ...
- 网络编程之tcp协议以及粘包问题
网络编程tcp协议与socket以及单例的补充 一.单例补充 实现单列的几种方式 #方式一:classmethod # class Singleton: # # __instance = None # ...
- 为什么 TCP 协议有粘包问题
为什么 TCP 协议有粘包问题 这部分转载自draveness博客. TCP/IP 协议簇建立了互联网中通信协议的概念模型,该协议簇中的两个主要协议就是 TCP 和 IP 协议.TCP/ IP 协议簇 ...
- tcp协议下粘包问题的产生及解决方案
1 tcp有粘包及udp无粘包 - TCP 是面向连接的,面向流的可靠协议:发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据, 合并成 ...
- TCP协议的粘包问题(八)
一.什么是粘包 在socket缓冲区和数据的传递过程介绍中,可以看到数据的接收和发送是无关的,read()/recv() 函数不管数据发送了多少次,都会尽可能多的接收数据.也就是说,read()/re ...
- TCP协议的粘包现象和解决方法
# 粘包现象 # serverimport socket sk = socket.socket()sk.bind(('127.0.0.1', 8005))sk.listen() conn, addr ...
- [Swoole系列入门教程 6] TCP协议和粘包
- Learning-Python【28】:基于TCP协议通信的套接字
什么是 Socket Socket 是应用层与 TCP/IP 协议通信的中间软件抽象层,它是一组接口.在设计模式中,Socket 其实就是一个门面模式,它把复杂的 TCP/IP 协议族隐藏在 Sock ...
- (2)socket的基础使用(基于TCP协议)
socket()模块函数用法 基于TCP协议的套接字程序 netstart -an | findstr 8080 #查看所有TCP和UDP协议的状态,用findstr进行过滤监听8080端口 服务端套 ...
随机推荐
- 75. Sort Colors(荷兰国旗问题 三指针)
Given an array with n objects colored red, white or blue, sort them so that objects of the same co ...
- 使用Vue.js初次真正项目开发-2018/07/14
一.组件化 使用Vue.js进行开发,按照MVVM模式,围绕数据为核心,进行开发. 开发过程根据业务和功能组件化,组件化一方面让我们开发思路更加清晰,另一方面对于数据的处理和控制变得更加简单,毕竟一个 ...
- 【leetcode刷题笔记】Majority Element
Given an array of size n, find the majority element. The majority element is the element that appear ...
- C++中的内存区[译文]
C++ 中的内存区 Const Data: The const data area stores string literals and other data whose values are kno ...
- 并查集 试水 hdu1232
#include <stdio.h> #include <stdlib.h> int n,m; ],rank[]; int count; int find(int x) { i ...
- Madplay移植到mini2440开发板【转】
本文转载自:https://blog.csdn.net/simanstar/article/details/24035379 madplay交叉编译 交叉编译器:arm-linux-gcc 3.4.1 ...
- Python 面向对象的综合应用
# 面向对象的综合应用 # 计算器:实现一些基本的计算操作,已经打印结果 # --------------- 代码1 ---------------------- def add(x, y): ret ...
- java基础(6)--数组和方法
数组 1. 什么是数组? 数组是相同数据类型的元素组成的集合.这些元素按线性顺序排列.所谓线性顺序是指除第一个元素外,每一个元素都有唯一的前驱元素:除最后一个元素外,每一个元素都有唯一的后继元素.(“ ...
- IE6+以上清除浮动普遍方法总结
浮动,CSSfloat属性.学过的人应该知道这个属性,平时用的应该也是很多的.特别是在N栏布局中. 但是我们会经常遇到这样一种情况,前面的元素浮动之后会影响后面的元素,后面的元素需要用清除浮动来消灭前 ...
- NumPy来自现有数据的数组
NumPy - 来自现有数据的数组 这一章中,我们会讨论如何从现有数据创建数组. numpy.asarray 此函数类似于numpy.array,除了它有较少的参数. 这个例程对于将 Python 序 ...