Scalable Rule-Based Representation Learning for Interpretable Classification
概
传统的诸如决策树之类的机器学习方法具有很强的结构性, 也因此具有很好的可解释性. 和深度学习方法相比, 这类方法比较难以推广到大规模的问题上, 很重要的一个原因便是, 其离散的参数和结构导致无法利用梯度进行优化. 本文是对利用梯度来优化这些模型的一个尝试.
主要内容
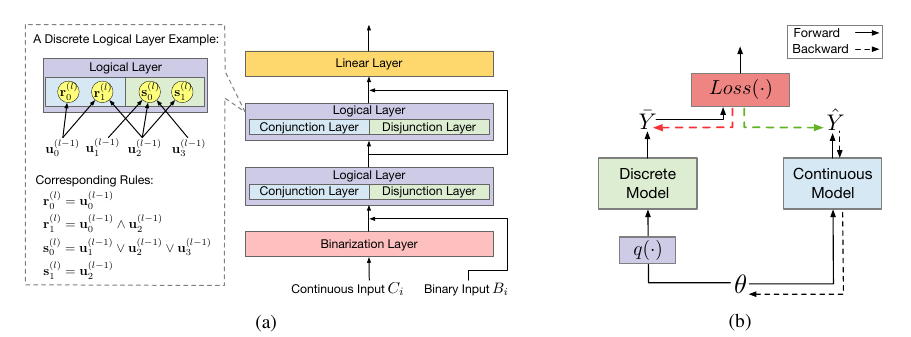
本文考虑的是上图(a)中的离散模型, 其接受连续变量\(C_i\)和离散变量\(B_i\):
- 通过Binarization Layer 将连续变量\(C_i\)离散化并与\(B_i\)拼接得到输入\(\bm{u}^{(0)}\);
- 对于Logical Layer, 其以\(\bm{u}^{l-1}\)为输入, 输出\(\bm{u}^l\), 其包含且\(\bm{r}\)和或\(\bm{s}\)两个部分:
s_i^{(l)} = \bigvee_{W_{ij}^{(l, 1)} = 1} u_j^{(l-1)}. \\
\]
其中\(W^{(l, 0)}\)表示\(\bm{r}\)与\(\bm{u}\)的邻接矩阵, 而\(W^{(l, 1)}\)表示\(\bm{s}\)与\(\bm{u}\)的邻接矩阵. 可以发现, Logical Layer中的输入输出和权重都是二元的.
3. 最后通过一个线性层进行分类, 需要说明的是, 线性层的权重是连续的.
显然由于logical layer是离散的, 直接通过梯度更新是办不到的. 一个自然的想法是用一个连续的版本\(\hat{\mathcal{F}}(X; \theta)\)进行替换, 更新连续的参数\(\theta\)然后获得下列的离散的版本:
\]
显然直接套用这个方法是低效的, 因为训练过程和离散没有任何关系, 我们没法保证离散后的模型依旧是有效的, 此外还有一个问题, 上述离散模型如何匹配到一个连续的版本.
下面是一个有趣的解决方案, 假设\(\hat{W}_{i,j} \in [0, 1]\), 则
Disj (\bm{u}, W_i) = 1 - \prod_{j=1}^n \bigg\{1 - W_{i,j}u_j \bigg\}, \\
\]
便为且和或操作的连续版本.
试想:
& r_i = 1 \\
\Leftrightarrow & \bigwedge_j [u_j^{(l-1)} \vee (1 - W_{ij})] = 1\\
\Leftrightarrow & \prod_j \bigg\{1 - W_{i,j}(1 - u_j) \bigg\} = 1.\\
\end{array}
\]
其它情况可以类似推导, 实在是有趣.
但是上述式子在实际中会有一些梯度消失的问题(因为连乘号, 且内部是[0, 1]之间的), 所示在实际使用中, 作者加了一个投影算子
\]
其中(这设计都是为了避免梯度消失, 怎么想到的? 怎么会往这个方向去想的?)
\]
解决了连续版本的问题, 现在剩下的难啃的地方是如何更新\(\theta\)以保证\(q(\theta)\)也是有意义的.
作者采用如下的梯度更新公式:
\]
其中\(\hat{Y} = \hat{\mathcal{F}}(X; \theta)\), \(\bar{Y} = \mathcal{F}(X; \bar{\theta})\).
作者用了一个嫁接的例子来说明该思想, 即损失关于预测的导数用离散的, 内部的导数用连续的.
我惊讶的是, 这些改动居然work? 太不可思议了.
Scalable Rule-Based Representation Learning for Interpretable Classification的更多相关文章
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- Hierarchical Attention Based Semi-supervised Network Representation Learning
Hierarchical Attention Based Semi-supervised Network Representation Learning 1. 任务 给定:节点信息网络 目标:为每个节 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- (zhuan) Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Evolution Strategies as a Scalable Alternative to Reinforcement Learning this blog from: https://blo ...
- (zhuan) Notes on Representation Learning
this blog from: https://opendatascience.com/blog/notes-on-representation-learning-1/ Notes on Repr ...
- Self-Supervised Representation Learning
Self-Supervised Representation Learning 2019-11-11 21:12:14 This blog is copied from: https://lilia ...
- 【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID
目录 主要挑战 主要的贡献和创新点 提出的方法 总体框架与算法 Vanilla pseudo label sampling (PLS) PLS with adversarial learning Tr ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- (转)Predictive learning vs. representation learning 预测学习 与 表示学习
Predictive learning vs. representation learning 预测学习 与 表示学习 When you take a machine learning class, ...
随机推荐
- python生成器浅析
A 'generator' is a function which returns a generator iterator. It looks like a normal function exce ...
- 断言(assert)简介
java中的断言assert的使用 一.assertion的意义和用法 J2SE 1.4在语言上提供了一个新特性,就是assertion功能,他是该版本再Java语言方面最大的革新. 从理论上来说,通 ...
- Spark基础:(四)Spark 数据读取与保存
1.文件格式 Spark对很多种文件格式的读取和保存方式都很简单. (1)文本文件 读取: 将一个文本文件读取为一个RDD时,输入的每一行都将成为RDD的一个元素. val input=sc.text ...
- 大数据学习day36-----flume02--------1.avro source和kafka source 2. 拦截器(Interceptor) 3. channel详解 4 sink 5 slector(选择器)6 sink processor
1.avro source和kafka source 1.1 avro source avro source是通过监听一个网络端口来收数据,而且接受的数据必须是使用avro序列化框架序列化后的数据.a ...
- Handler与多线程
1.Handler介绍 在Android开发中,我们常会使用单独的线程来完成某些操作,比如用一个线程来完成从网络上下的图片,然后显示在一个ImageView上,在多线程操作时,Android中必须保证 ...
- Git命令行演练-团队开发
** 团队开发必须有一个共享库,这样成员之间才可以进行协作开发** ### 0. 共享库分类 > 本地共享库(只能在本地面对面操作) - 电脑文件夹/U盘/移动硬盘 & ...
- Spring Boot中使用Dubbo
高并发下Redis会出现的问题: 缓存穿透 缓存雪崩 热点缓存 一.定义commons工程11-dubboCommons (1) 创建工程 创建Maven的Java工程,并命名为11-dubboCom ...
- 使用springboot配置和注入数据源属性的方法和步骤
/** 1.书写一个名为resources/application.properties的属性文件---->书写一个配置属性类,类名为: **/ 文件:application.propertie ...
- C#获取Windows10屏幕的缩放比例
现在1920x1080以上分辨率的高分屏电脑渐渐普及了.我们会在Windows的显示设置里看到缩放比例的设置.在Windows桌面客户端的开发中,有时会想要精确计算窗口的面积或位置.然而在默认情况下, ...
- 如何用three.js实现数字孪生、3D工厂、3D工业园区、智慧制造、智慧工业、智慧工厂-第十课
文章前,先聊点啥吧. 最近元宇宙炒的挺火热,在所有人都争相定义元宇宙的时候,资本就开始着手入场了.当定义明确,全民皆懂之后,风口也就过去了. 前两天看到新闻,新世界CEO宣布购入最大的数字地块,这块虚 ...