Java应用日志如何与Jaeger的trace关联
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
经过《Jaeger开发入门(java版)》的实战,相信您已经能将自己的应用接入Jaeger,并用来跟踪定位问题了,本文将介绍Jaeger一个小巧而强大的辅助功能,用少量改动大幅度提升定位问题的便利性:将业务日志与Jaeger的trace关联
在正式开始前,咱们先来看一个具体的问题:
- 一次web请求可能有多条业务日志(log4j或者logback配置的那种),这和您写代码执行log.info的次数有关,假设有10条,那么十次请求就有一百条业务日志;
- 通过jaeger发现这十次请求中有一次耗时特别长,想定位一下具体原因,现在问题来了:一共有100条业务日志,到底哪些是和Jaeger中耗时长的那一次请求有关?
您可能会说:有些业务特征如user-id,咱们可以写入span的tag或者log中,这样通过span查到user-id,再去日志中查找含有此user-id的日志即可,这样确实可以,但未必每条日志都有user-id,所以并非最佳方式
好在Jaeger官方给出了一种简单有效的方案:基于MDC,Jaeger的SDK在日志中注入trace相关的变量
关于MDC
关于sl4j的MDC不是本篇的重点,因此只把本篇用到的特性简单说说即可,经验丰富的您如果对MDC已经了解,请跳过此节
在sl4j的配置文件中可以配置日志的格式,例如logback的配置文件如下,可见模板中新增了一段内容[user-id=%X{user-id}]:
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<!--%logger{10}表示类名过长时会自动缩写-->
<pattern>%d{HH:mm:ss} [%thread] %-5level %logger{10} [user-id=%X{user-id}] %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
</appender>
- 再来看一段日志的代码,先调用MDC.put方法将一个键值对写入当前线程的诊断上下文map(diagnostic context map),键名和上面的模板中配置的%X{user-id}一模一样:
@GetMapping("/test")
public void test() {
MDC.put("user-id", "user-" + System.currentTimeMillis());
log.info("this is test request");
}
- 现在把代码运行起来,打印日志看看,如下所示,之前模板中配置的%X{user-id}已被替换成了user-1632122267618,就是代码中MDC.put设置的值:
15:17:47 [http-nio-18081-exec-6] INFO c.b.j.c.c.HelloConsumerController [user-id=user-1632122267618] this is test request
以上就是MDC的基本功能:对日志模板中的变量进行填充,填充的内容可以用MDC.put方法随意设置;
此刻聪明的您应该能猜到jaeger官方的方案是如何实现的了,没错,就是借助MDC将trace信息填充到日志模板中,这样每行日志都有了trace信息,咱们在jaeger web页面中感兴趣的任何一次trace,都能找到对应的日志了
关于Jaeger的官方方案
- Jaeger的官方方案如下图所示,SDK已经把traceId、spanId、sampled写入当前线程的诊断上下文map(diagnostic context map),只要日志模板中配置上述三个变量,就会在所有业务日志中输出它们具体的值:
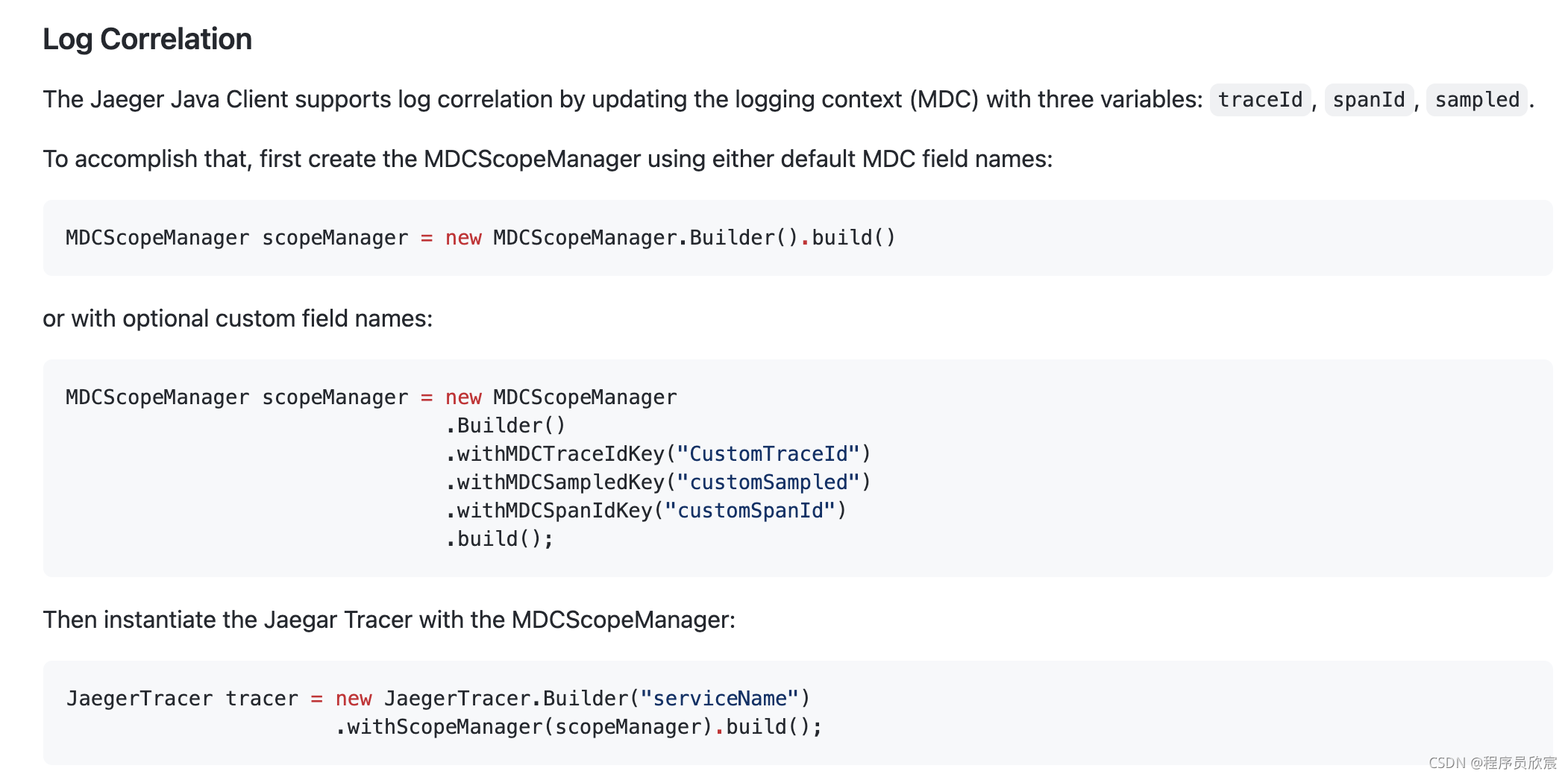
- 看起来似乎非常简单,那就动手编码试试吧
编码实战
jaeger与MDC的关联只是个小功能,没必要大张旗鼓的新建项目,基于《Jaeger开发入门(java版)》的代码继续开发即可,也就是说修改两个子工程jaeger-service-consumer和jaeger-service-provider的源码,让它们的业务日志打印出Jaeger的trace信息
首先从jaeger-service-provider工程开始,增加一个标准的logback日志配置文件logback.xml,如下所示,日志模板中已添加了traceId、spanId、sampled变量:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<contextName>logback</contextName>
<!--输出到控制台-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<!--%logger{10}表示类名过长时会自动缩写-->
<pattern>%d{HH:mm:ss} [%thread] %-5level %logger{10} [traceId=%X{traceId} spanId=%X{spanId} sampled=%X{sampled}] %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
</appender>
<root level="info">
<appender-ref ref="console" />
</root>
</configuration>
- 再去检查配置类,确认JaegerTracer实例化时用了MDCScopeManager参数,如下所示,咱们在上一章已经这么做了,可以维持不变:
package com.bolingcavalry.jaeger.provider.config;
import io.jaegertracing.internal.MDCScopeManager;
import io.opentracing.contrib.java.spring.jaeger.starter.TracerBuilderCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JaegerConfig {
@Bean
public TracerBuilderCustomizer mdcBuilderCustomizer() {
// 1.8新特性,函数式接口
return builder -> builder.withScopeManager(new MDCScopeManager.Builder().build());
}
}
- 接下来是在业务代码中随意加几行打印日志的代码,如下图红框所示:
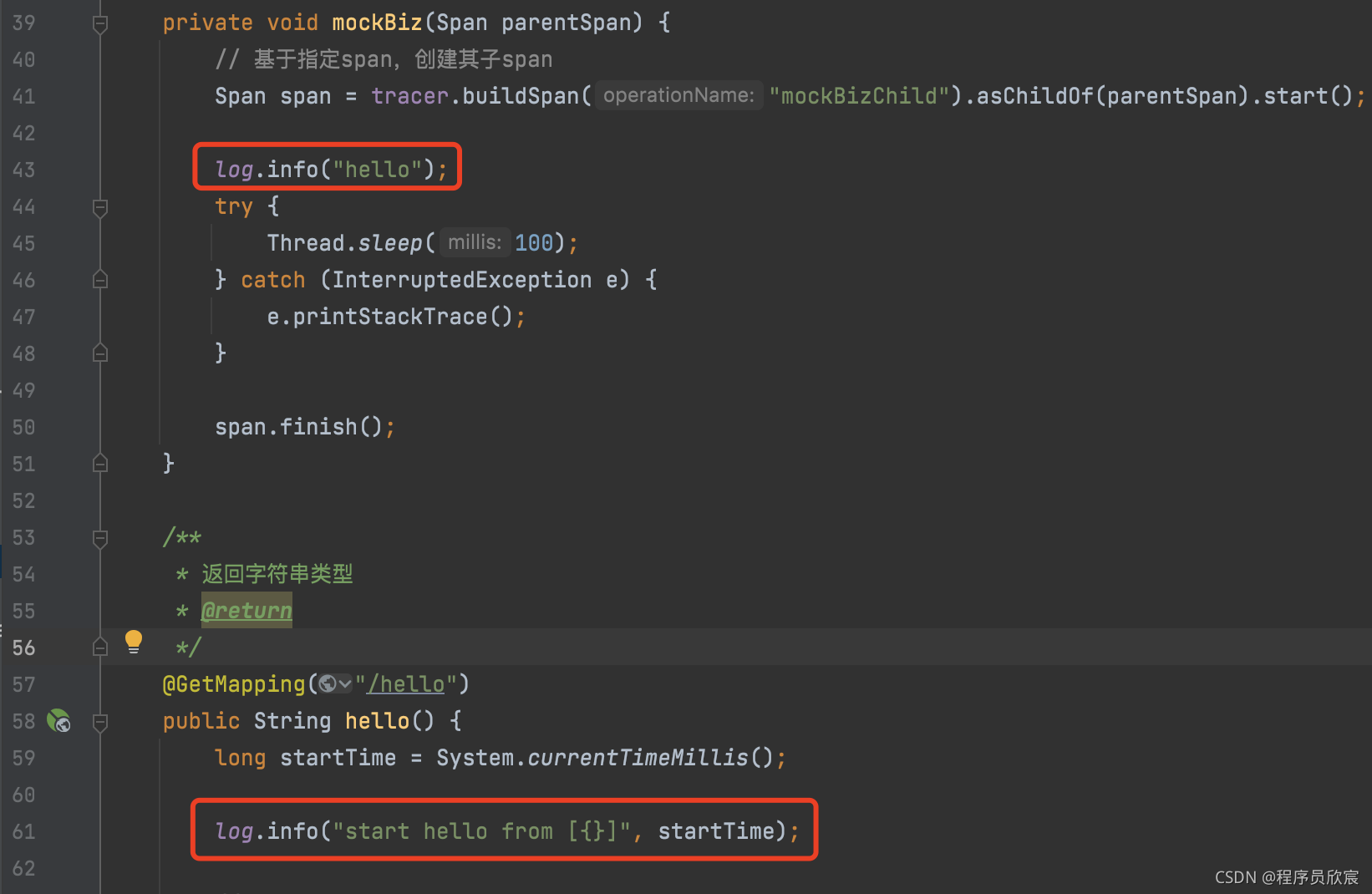
- 接下来继续修改jaeger-service-consumer子工程,具体步骤与刚才改造jaeger-service-provider时一模一样,就不多占用篇幅赘述了,记得在业务代码中随意加几行日志,如下图红框:
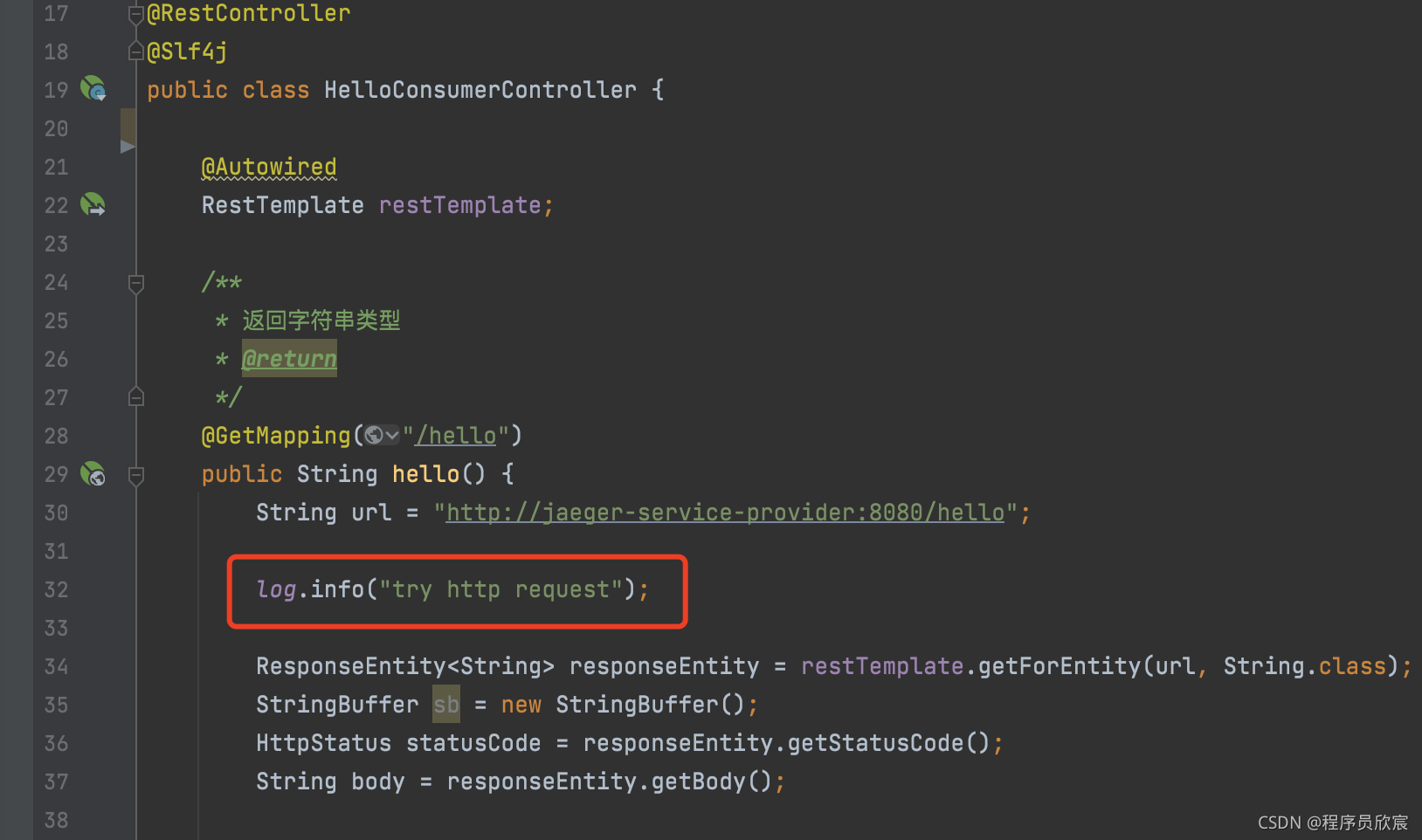
- 开发完成,开始验证吧
验证
像《Jaeger开发入门(java版)》那样操作,将jaeger-service-consumer和jaeger-service-provider编译构建制作成docker镜像
用docker-compose将所有服务启动,然后通过浏览器访问jaeger-service-consumer的服务,多访问几次
打开jaeger的web页面,可以看到多次请求的trace,咱们随机选择一个,鼠标点击下图红框中的圆点:
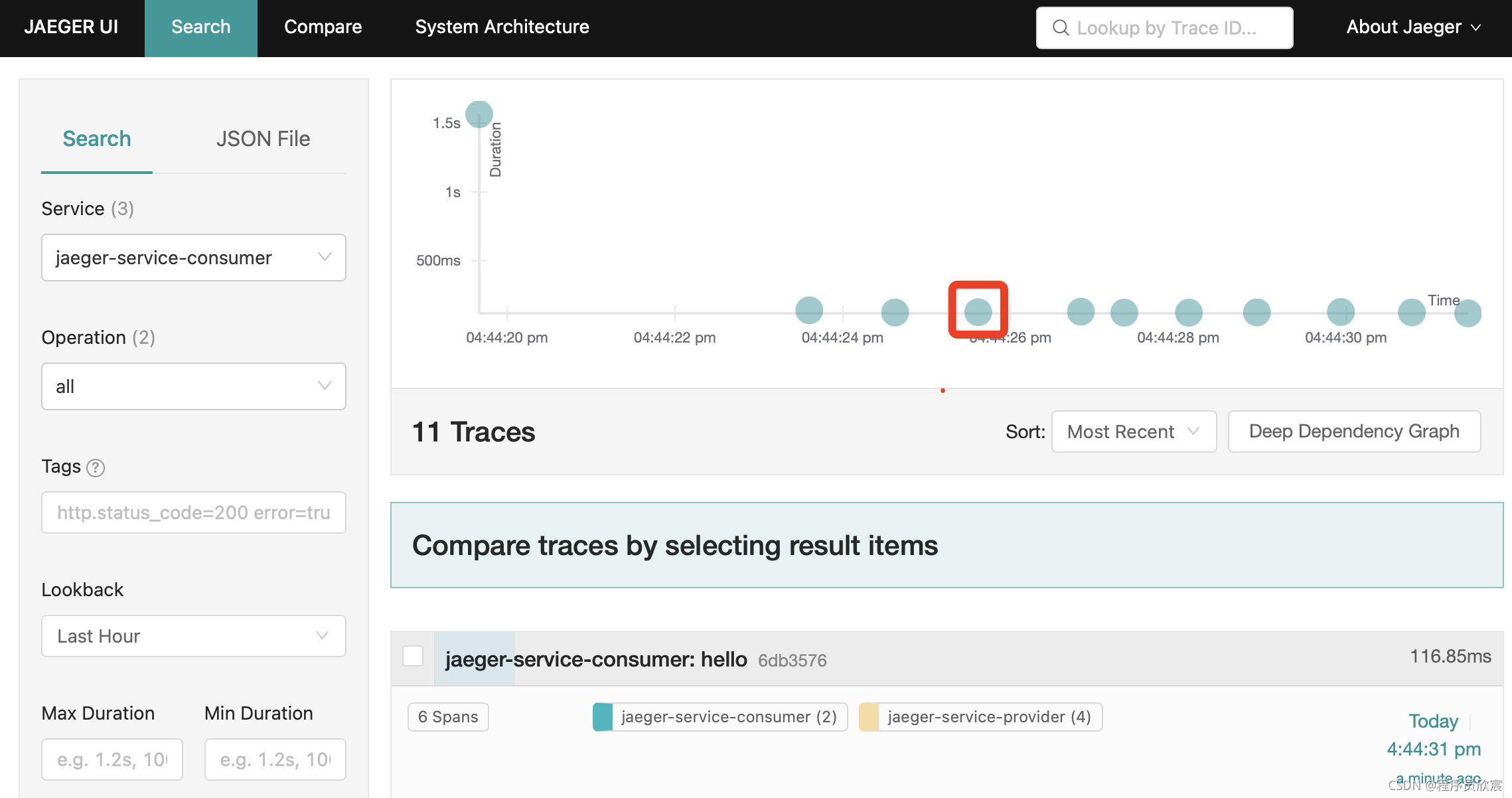
- 此时会跳转到该trace的详情页,注意页面的url,如下图红框,里面的2037fe105d73f4a5就是traceid:
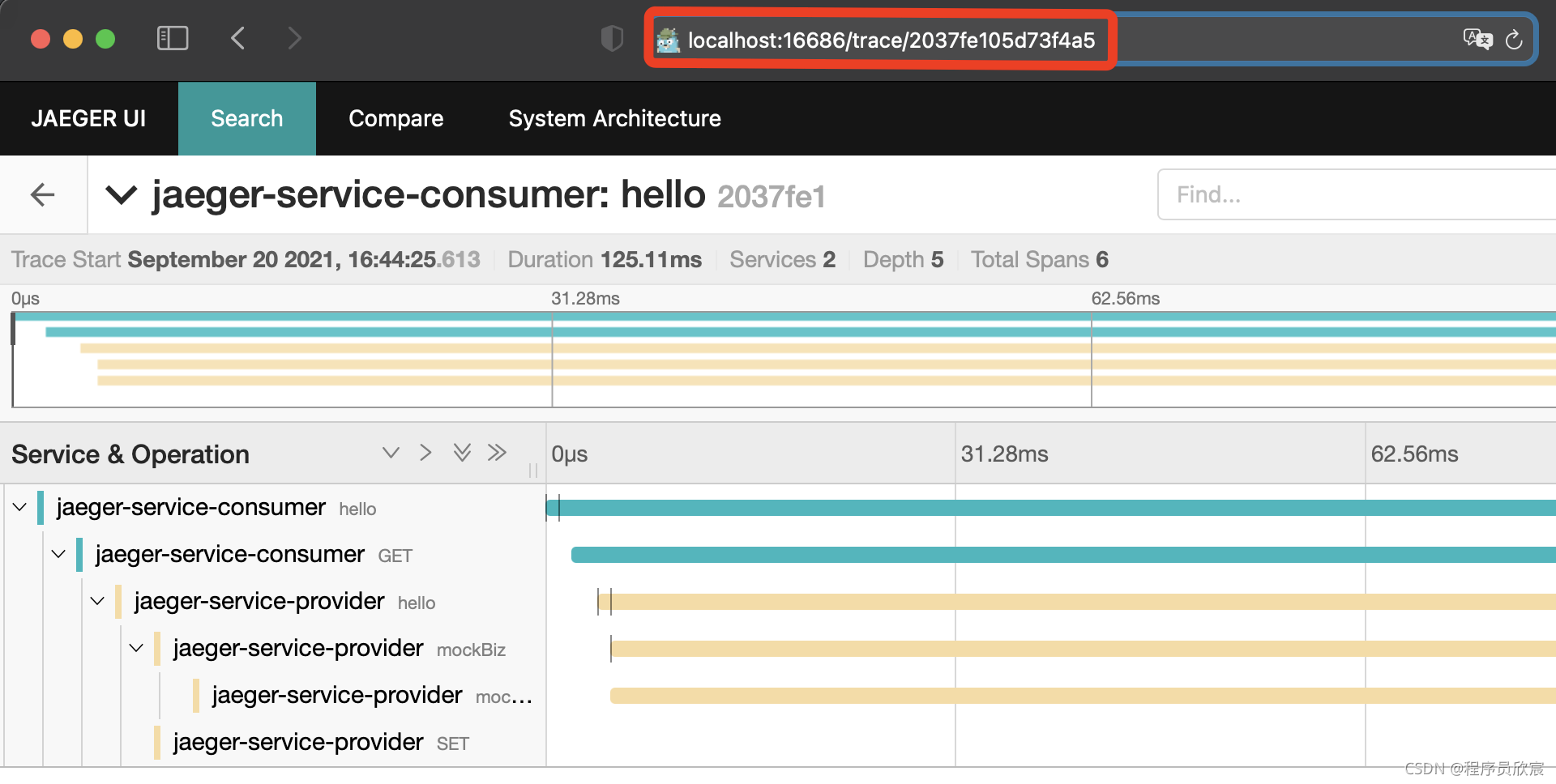
- 用2037fe105d73f4a5搜索jaeger-service-provider的日志,由于应用部署在docker中,咱们要用docker log和grep命令组合来过滤,如下所示,咱们代码写的日志都打印出来了,并且红框中就是traceid等关键信息

- 再去查看jaeger-service-consumer的日志,如下图红框,本次请求相关的日志也可以通过traceid搜索到:

- 至此,本篇实战就完成了,Jaeger的web页面上的任何一个trace,现在都能轻易找到与之对应的所有业务日志,这在定位问题时简直是如虎添翼的效果,如果您的系统用了ELK或者EFK来汇总所有分布式服务的日志,那就更高效了
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Java应用日志如何与Jaeger的trace关联的更多相关文章
- 细说Java主流日志工具库
概述 在项目开发中,为了跟踪代码的运行情况,常常要使用日志来记录信息. 在Java世界,有很多的日志工具库来实现日志功能,避免了我们重复造轮子. 我们先来逐一了解一下主流日志工具. java.util ...
- Java主流日志工具库
在项目开发中,为了跟踪代码的运行情况,常常要使用日志来记录信息.在Java世界,有很多的日志工具库来实现日志功能,避免了我们重复造轮子.我们先来逐一了解一下主流日志工具. 1.java.util.lo ...
- java Log日志规范
Overview 一个在生产环境里运行的程序如果没有日志是很让维护者提心吊胆的,有太多杂乱又无意义的日志也是令人伤神.程序出现问题时候,从日志里如果发现不了问题可能的原因是很令人受挫的.本文想讨论的是 ...
- JAVA主流日志梳理
JAVA主流日志梳理 引入 历史故事 Log4j - JDK1.3及以前 JUL - JDK1.4 JCL - 日志门面commons-logging的出现 SLF4j - 可能是最好的日志框架 lo ...
- Java中日志组件详解
avalon-logkit Java中日志组件详解 lanhy 发布于 2020-9-1 11:35 224浏览 0收藏 作为开发人员,我相信您对日志记录工具并不陌生. Java还具有功能强大且功能强 ...
- Java Slf4j日志配置输出到文件中
1.概述 新项目需要增加日志需求,所以网上找了下日志配置,需求是将日志保存到指定文件中.网上找了下文章,发现没有特别完整的文章,下面自己整理下. 1.Java日志概述 对于一个应用程序来说日志记录是必 ...
- Java 标准日志工具 Log4j 的使用(附源代码)
源代码下载 Log4j 是事实上的 Java 标准日志工具.会不会用 Log4j 在一定程度上可以说是衡量一个开发人员是否是一位合格的 Java 程序员的标准.如果你是一名 Java 程序员,如果你还 ...
- Java自定义日志输出文件
Java自定义日志输出文件 日志的打印,在程序中是必不可少的,如果需要将不同的日志打印到不同的地方,则需要定义不同的Appender,然后定义每一个Appender的日志级别.打印形式和日志的输出路径 ...
- Java GC 日志详解(转)
Java GC日志可以通过 +PrintGCDetails开启 以ParallelGC为例 YoungGC日志解释如下(图片源地址:这里) : FullGC(图片源地址:这里): http://blo ...
随机推荐
- es的rest风格的api文档
rest风格的api put http://127.0.0.1:9200/索引名称/类型名称/文档id (创建文档,指定文档id) post http://127.0.0.1:9200/索引名称/类型 ...
- 强化学习之MountainCarContinuous(注册自己的gym环境)
目录 1. 问题概述 2. 环境 2.1 Observation & state 2.2 Actions 2.3 Reward 2.4 初始状态 2.5 终止状态- Episode Termi ...
- CF1540B Tree Array
先写一下自己想到的部分: 考虑枚举一个根. 计算一个点对出现的概率. 对于我这种期望概率基本不会的人,差点就把这题切了. 自己想到的部分都没有假. 问题在于: 如何计算一个点对出现的概率. 考虑和这两 ...
- 【机器学习与R语言】9- 支持向量机
目录 1.理解支持向量机(SVM) 1)SVM特点 2)用超平面分类 3)对非线性空间使用核函数 2. 支持向量机应用示例 1)收集数据 2)探索和准备数据 3)训练数据 4)评估模型 5)提高性能 ...
- python基础实战
字符串的互相转换 字典的排序 字典的排序可以直接把,key值或者,values拿出来排序 也可以用dict.items拿出所有的key,value的值再加key=lambda x:x[1] 来排序. ...
- C#时间选择
<script type="text/javascript" src="http://www.shicishu.com/down/WdatePicker.js&qu ...
- 生产调优4 HDFS-集群扩容及缩容(含服务器间数据均衡)
目录 HDFS-集群扩容及缩容 添加白名单 配置白名单的步骤 二次配置白名单 增加新服务器 需求 环境准备 服役新节点具体步骤 问题1 服务器间数据均衡 问题2 105是怎么关联到集群的 服务器间数据 ...
- 在windows 10家庭版上安装docker的步骤
本人之前写Redis书和Spring Cloud Alibaba书时,发现一些分布式组件更适合安装在linux环境,而在搭建Redis等集群时,更需要linux环境. 本人日常练习代码和写书所用的机器 ...
- day07 Linux配置修改
day07 Linux配置修改 昨日回顾 1.系统目录 /etc :系统配置目录 /bin-> /usr/bin :保存常用命令的目录 /root :超级管理员目录 /home :普通管理员目录 ...
- hadoop/spark面试题
总结于网络 转自:https://www.cnblogs.com/jchubby/p/5449379.html 1.简答说一下hadoop的map-reduce编程模型 首先map task会从本地文 ...