02-爬取http://www.allitebooks.org/网站,获取图片url,书名,简介,作者
import requests
from lxml import etree
from bs4 import BeautifulSoup
import json class BookSpider(object):
def __init__(self):
self.base_url = 'http://www.allitebooks.com/page/{}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'} self.data_list = [] # 1.构建所有url
def get_url_list(self):
url_list = []
for i in range(1, 10): # 此处爬取的页数按需要确定
url = self.base_url.format(i)
url_list.append(url)
return url_list # 2.发请求
def send_request(self, url):
data = requests.get(url, headers=self.headers).content.decode()
return data # 3.解析数据 xpath
def parse_xpath_data(self, data):
parse_data = etree.HTML(data) # 1.解析出所有的书 book
book_list = parse_data.xpath('//div[@class="main-content-inner clearfix"]/article') # 2.解析出 每本书的 信息
for book in book_list:
book_dict = {}
# 1.书名字
book_dict['book_name'] = book.xpath('.//h2[@class="entry-title"]//text()')[0] # 2.书的图片url
book_dict['book_img_url'] = book.xpath('div[@class="entry-thumbnail hover-thumb"]/a/img/@src')[0] # 3.书的作者
book_dict['book_author'] = book.xpath('.//h5[@class="entry-author"]//text()')[0] # 4.书的简介
book_dict['book_info'] = book.xpath('.//div[@class="entry-summary"]/p/text()')[0] self.data_list.append(book_dict) def parse_bs4_data(self, data): bs4_data = BeautifulSoup(data, 'lxml')
# 1.取出所有的书
book_list = bs4_data.select('article') # 2.解析出 每本书的 信息
for book in book_list:
book_dict = {}
# 1.书名字
book_dict['book_name'] = book.select_one('.entry-title').get_text() # # 2.书的图片url
book_dict['book_img_url'] = book.select_one('.attachment-post-thumbnail').get('src') # # 3.书的作者
book_dict['book_author'] = book.select_one('.entry-author').get_text()[3:]
#
# # 4.书的简介
book_dict['book_info'] = book.select_one('.entry-summary p').get_text()
print(book_dict)
self.data_list.append(book_dict) # 4.保存数据
def save_data(self):
json.dump(self.data_list, open("04book.json", 'w')) # 统筹调用
def start(self): url_list = self.get_url_list() # 循环遍历发送请求
for url in url_list:
data = self.send_request(url)
# self.parse_xpath_data(data)
self.parse_bs4_data(data) self.save_data() BookSpider().start()
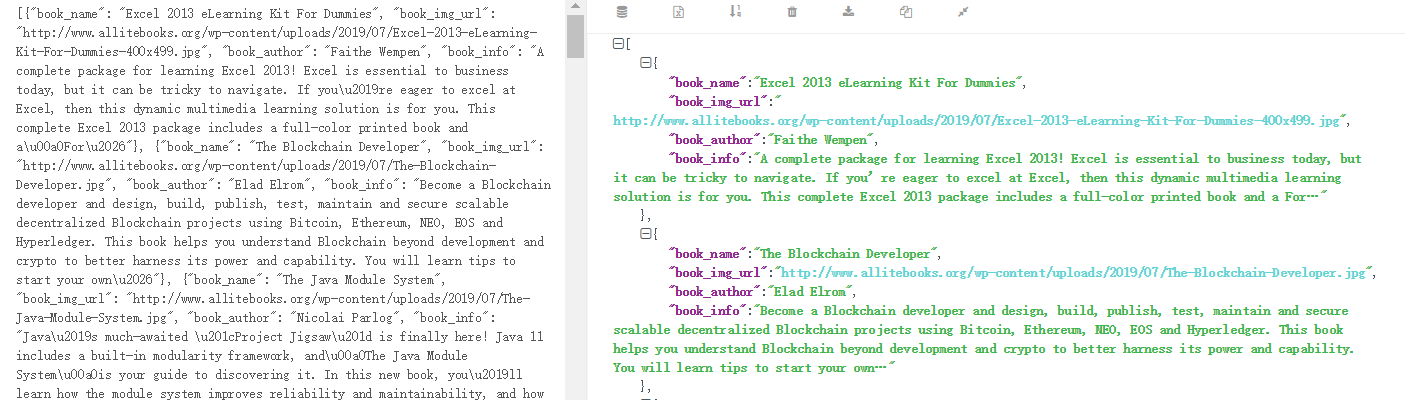
运行结果(下面利用了json转换)
02-爬取http://www.allitebooks.org/网站,获取图片url,书名,简介,作者的更多相关文章
- 02. 爬取get请求的页面数据
目录 02. 爬取get请求的页面数据 一.urllib库 二.由易到难的爬虫程序: 02. 爬取get请求的页面数据 一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用 ...
- Python爬虫实例(一)爬取百度贴吧帖子中的图片
程序功能说明:爬取百度贴吧帖子中的图片,用户输入贴吧名称和要爬取的起始和终止页数即可进行爬取. 思路分析: 一.指定贴吧url的获取 例如我们进入秦时明月吧,提取并分析其有效url如下 http:// ...
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- Scrapy实战:爬取http://quotes.toscrape.com网站数据
需要学习的地方: 1.Scrapy框架流程梳理,各文件的用途等 2.在Scrapy框架中使用MongoDB数据库存储数据 3.提取下一页链接,回调自身函数再次获取数据 重点:从当前页获取下一页的链接, ...
- [Python] 快速爬取当前城市所有租房网站房源及配置,一目了然
Python爬取当前城市房源信息,以徐州为例代码效果图请看下方,其他部分请查看附件,一起学习,谢谢 # -*- coding: utf-8 -*- """ @Time : ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- 亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取
1.亚马逊商品页面链接地址(本次要爬取的页面url) https://www.amazon.cn/dp/B07BSLQ65P/ 2.代码部分 import requestsurl = "ht ...
- Python 2.7_爬取CSDN单页面博客文章及url(二)_xpath提取_20170118
上次用的是正则匹配文章title 和文章url,因为最近在看Scrapy框架爬虫 需要了解xpath语法 学习了下拿这个例子练手 1.爬取的单页面还是这个rooturl:http://blog.csd ...
- 最简单的网络图片的爬取 --Pyhon网络爬虫与信息获取
1.本次要爬取的图片的url http://www.nxl123.cn/static/imgs/php.jpg 2.代码部分 import requestsimport osurl = "h ...
随机推荐
- 攻防世界 Misc 新手练习区 ext3 bugku Writeup
攻防世界 Misc 新手练习区 ext3 bugku Writeup 题目介绍 题目考点 WinHex工具的使用 linux磁盘挂载mount命令 Writeup 下载附件拖进winhex分析一下,查 ...
- uni-app 提示 v-for 暂不支持循环数据
这个问题由于目前博主只在APP端遇到过,解决办法是把v-for key值全部取循环的索引,如果解决了你的问题请给博主点个赞 <block v-for="(item,index) in ...
- 大一C语言学习笔记(9)---指针篇--从”内存的使用“和“流程控制”的角度来理解“指针变量的使用‘
#深入理解指针变量 举个错误栗子: //以下代码的目的是输出100和1000,但输出结果只有一个100 #include<stdio.h> #include<malloc.h> ...
- Part 18 $http service in AngularJS
In Angular there are several built in services. $http service is one of them. In this video, we will ...
- Unable to unwrap data, invalid status [CLOSED]-服务端webSocket报错
一.问题由来 现在的项目中在使用webSocket这门技术,主要用来在服务端和客户端进行实时的数据传输,因为需要及时的进行响应,所以才没有使用http请求的方式, 而是使用socket的方式,这样可以 ...
- Dapr-发布/订阅
前言 前篇文章对Dapr的状态管理进行了解,本篇继续对 订阅/发布 构建块进行了解. 一.定义: 发布订阅的概念来自于事件驱动架构(EDA)的设计思想,这是一种让程序(应用.服务)之间解耦的主要方式, ...
- [loj6734]图上的游戏
考虑原图是一条链的情况-- 思路:随机一个点$x$,将其所在段(边集)再划分为两段,重复此过程即可得到该链 实现上,(从左到右)维护每一段的左端点和边集,二分找到最后一个删除后$x$到根不连通的段,那 ...
- 【Spring】(1)-- 概述
Spring框架 -- 概述 2019-07-07 22:40:42 by冲冲 1. Spring的概念 ① Spring框架的关键词:开源框架.轻量级框架.JavaEE/J2EE开发框架.企业级 ...
- idea增加jvm内存
-server -XX:PermSize=256M -XX:MaxPermSize=1024m
- Jmeter BlazeMeter实现web录制
1. BlazeMeter安装和注册 BlazeMeter是一款与Apache JMeter兼容的chrome插件,采用BlazeMeter可以方便的进行流量录制和脚本生成,作为接口测试脚本编写的 ...