大数据学习day16------第三阶段-----scala04--------1. 模式匹配和样例类 2 Akka通信框架
1. 模式匹配和样例类
Scala有一个十分强大的模式匹配机制,可以应用到很多场合:如switch语句、类型检查等。并且Scala还提供了样例类,对模式匹配进行了优化,可以快速进行匹配
1.1 模式匹配
1.1.1 匹配字符串
object CaseDemo1 extends App { // 继承App特质(接口)后就不需要写main方法了
val arr = Array("A","B","C")
val name = arr(Random.nextInt(arr.length))
name match{
case "A" => println("我是A")
case "B" => println("我是B")
case _ => println("我可以匹配一切")
}
}
1.1.2 匹配类型
object CaseDemo02 extends App {
val arr = Array("hello", 1, 2.0, CaseDemo02)
val v = arr(Random.nextInt(arr.length))
v match{
case v:String => println("String:"+v)
case v:Int => println("Int:"+v)
case v:Double => println("Double:"+v)
case _ => throw new Exception("not match exception")
}
}

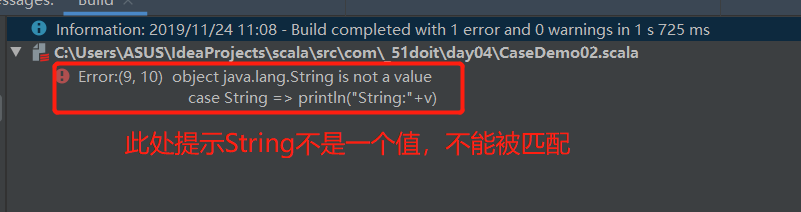
注意:case后面接收的一定是一个值,不能是参数类型,自己犯的错误:
case String => println("String:"+v)
报错如下:
1.1.3 匹配数组、集合、元组
数组
object CaseDemo03 extends App {
// 不可变数组
val arr = Array(1, 3, 6)
arr match {
case Array(1, x, y) => println(x + " " + y)
case Array(0) => println("only 0")
case Array(0, _*) => println("0 ...")
case _ => println("something else")
}
}
集合
// 不可变集合
val lst = List(3, -1)
lst match {
case 0 :: Nil => println("only 0")
case x :: y :: Nil => println(s"x: $x y: $y") case 0 :: tail => println("0 ...")
case _ => println("something else")
注意:s 底层是一个方法,其是一个简单的值插入器,它可以通过${}的形式从任意表达式中取出其字符串形式的值,上面因为就一个参数,所以可以省略{},若是上式改成如下

其打印的结果为x: 3+y y: -1 所以若想取多个参数的值必须使用${}
知识点补充:
- “+:”和"::" 都是用来拼接集合的
- 一个集合分为头部和尾部(第一个元素为头,其余元素组成的集合为尾)
- Nil代表空
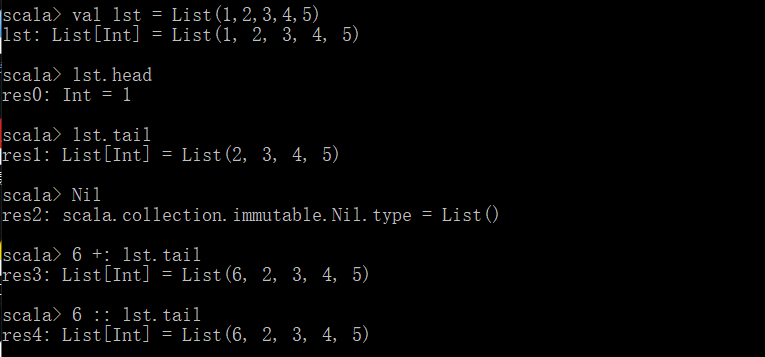
注意: 在Scala中列表要么为空(Nil表示空列表)要么是一个head元素加上一个tail列表。9 :: List(5, 2) ":: "操作符是将给定的头和尾创建一个新的列表
" :: "操作符是右结合的,如9 :: 5 :: 2 :: Nil相当于 9 :: (5 :: (2 :: Nil))
1.2 样例类
在Scala中样例是一种特殊的类,可用于模式匹配。case class是多例的,后面要跟构造参数,case object是单例的。其内部直接实现了序列化并且创建对象不需要new,直接写类名即可
// case class主要是为了封装数据和模式匹配
case class SubmitTask(id: String, name: String)
case class HeartBeat(time: Long)
//case class Heart() //case class一定要有参数,此处是空参数
case object CheckTimeOutTask // 不能有参数 object CaseDemo04 extends App{
val arr = Array(CheckTimeOutTask, HeartBeat(12333), SubmitTask("0001", "task-0001")) arr(Random.nextInt(arr.length)) match {
case SubmitTask(id, name) => {
println(s"$id, $name")
}
case HeartBeat(time) => {
println(time)
}
case CheckTimeOutTask => {
println("check")
}
}
}
补充:模式匹配也可以匹配自定义的类型,那么自定义的类型和case class/object有哪些区别呢?
case class创建对象不用new,实现了序列化接口、比自定义的类型匹配更加高效
1.3 Option类型
在Scala中Option类型样例类用来表示可能存在或也可能不存在的值(Option的子类有Some和None)。Some包装了某个值,None表示没有值
object OptionDemo {
def main(args: Array[String]) {
val map = Map("a" -> 1, "b" -> 2)
val v = map.get("b") match {
case Some(i) => i
case None => 0
}
println(v)
//更好的方式
val v1 = map.getOrElse("c", 0)
println(v1)
}
}
1.4 偏函数
被包在花括号内没有match的一组case语句是一个偏函数(类型是PartialFunction,有case,无match),它是PartialFunction[A, B]的一个实例,A代表参数类型,B代表返回类型,常用作输入模式匹配
object PartialFuncDemo {
// 使用偏函数
def func1: PartialFunction[String, Int] = {
case "one" => 1
case "two" => 2
case _ => -1
}
// 不使用偏函数,也能实现这个功能,只是使用偏函数简洁些
def func2(num: String) : Int = num match {
case "one" => 1
case "two" => 2
case _ => -1
}
def main(args: Array[String]) {
println(func1("one"))
println(func2("one"))
}
}
2. Akka通信框架
2.0 背景 :
在JVM领域,比较流行的、高效的、通信框架有哪些
- Netty: 使用用Java编写,基于Java Nio、事件驱动的并发编程框架,可以实现多种网络编程协议(Http、TCP、UDP)【Hadoop、Spark】
Akka:用scala编程的一个异步通信框架、基于Actor编程模型,通过发送消息实现并发,支持Scala和Java的API【Spark、Flink】
Mina:用Java编程的NIO通信框架
2.1 Akka简介:
Akka是J在AVA虚拟机JVM平台上构建高并发、分布式和容错应用的工具包。Akka用Scala语言写成,同时提供了Scala和JAVA的开发接口。
Akka处理并发的方法基于Actor模型。在Akka里,Actor之间通信的唯一机制就是消息传递。
2.2 Akka的特点 :
- Simple Concurrency & Distribution单并发性&分布式
- Resilient by Design (可恢复的、弹性的)
- High Performance高效
- Elastic & Decentralized 弹性、去中心的(分散)
- Extensible可扩展
2.3 Actors:(来源:https://www.jianshu.com/p/449850aa8e82)
Actor模型是一个概念模型,用于处理并发计算。它定义了一系列系统组件应该如何动作和交互的通用规则。
一个Actor指的是一个最基本的计算单元。它能接收一个消息并且基于其执行计算。
这个理念很像面向对象语言,一个对象接收一条消息(方法调用),然后根据接收的消息做事(调用了哪个方法)。
Actors一大重要特征在于actors之间相互隔离,它们并不互相共享内存。这点区别于上述的对象。也就是说,一个actor能维持一个私有的状态,并且这个状态不可能被另一个actor所改变。
actor是用来收发消息的,一个Actor就是一个类的实例。可以创建多个Actor实现并发,根据老师和学生的例子(老师和学生都是Actor),所有的Actor都要管理者(教学总监),创建Actor和管理Actor,以后发送的消息是带类型的,可以根据消息类型进行匹配,处理不同的逻辑。如果用Scala实现,用到的知识点:case class、case object
2.4 Akka的通信流程
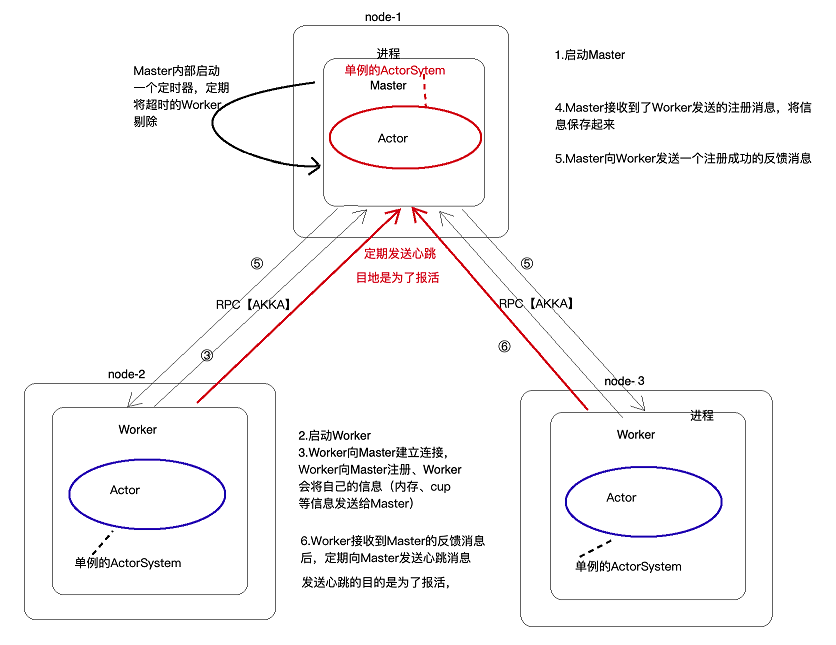
3 AKKA案例
需求:实现上述akka的通信流程
3.1 创建一个master,并向自己发送消息
过程:
- 创建master类(因为是多实例的),并让其实现Actor特质(让其与Akka关联起来)
- 重写Actor特质中的方法(receive),用来接收消息,其会一直等着接收消息,此方法的返回值的类型为偏函数,所以函数体中可以用偏函数的形式去匹配
- 创建master的伴生对象
- 在伴生对象中创建actor(通过ActorSystem)
- 使用创建的actor发送消息
代码如下:
// Actor编程模型进行通信,需要让其与AKKA发生点关系(此处实现Actor特质)
class Master extends Actor {
override def receive: Receive = {
case "hah" => {
println("receive a hello msg")
}
}
} object Master{
def main(args: Array[String]): Unit = {
val host = "localhost"
val port = 8888
val configStr =
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider" // 负责通信的核心类,有必要可以自己定义
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin // 此方法负责切割
val conf = ConfigFactory.parseString(configStr)
val actorSystem = ActorSystem.apply("MASTER_ACTOR_SYSTEM", conf)
// 通过ActorSystem对象常见Actor(通过反射指定类型的Actor的实例)
val masterActor = actorSystem.actorOf(Props[Master], name = "MASTER_ACTOR")
// 向Actor发送消息
// ! 表示的是发送异步消息
masterActor.!(message = "hah")
}
}
3.2 创建一个worker,并向自己发送消息,过程同master
代码如下:
class Worker extends Actor {
// 重写用于接收消息的方法
override def receive: Receive = {
case "liZhi" => println("z这个世界会好吗")
}
}
object Worker{
def main(args: Array[String]): Unit = {
val host = "localhost"
val port = 7777
val configStr =
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider" // 负责通信的核心类,有必要可以自己定义
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin // 此方法负责切割
val conf = ConfigFactory.parseString(configStr)
val workerActorSystem = ActorSystem("WORKER_ACTOR_SYSTEM", conf)
val workerActor: ActorRef = workerActorSystem.actorOf(Props[Worker], name = "WORKER_ACTOR")
workerActor.!("liZhi")
}
}
以上都是自己给自己发消息,如何是worker和master彼此间互发消息呢?
worker去连接master(老大)
3.3 Worker向Master建立连接并发送消息(测试)
以下只列出代码的改变处:
Worker部分:
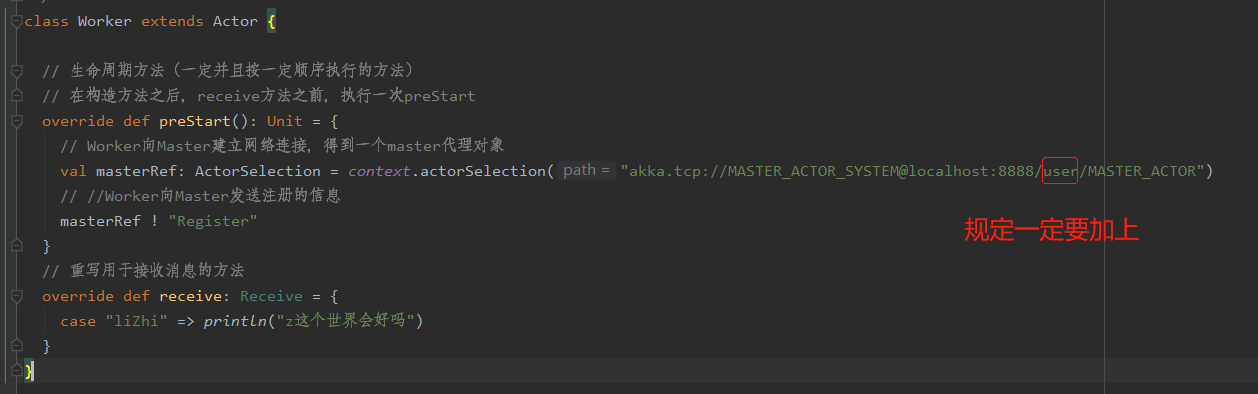
Master部分(写接收worker发送消息的代码即可)
3.4 最终版
思路
- worker在接收消息前,构造方法之后(preStart方法),创建与Master的连接,并发送注册信息(RegisterWorker:注册消息应该包括自己的id,内存情况,以及自己使用的cpu个数)
发送的注册信息用case class(后面带有信息的传递都使用case class,此处创建了Messages类),因为case class既可以封装数据,又可以进行模式匹配,还实现了序列化接口
- Master处定义receive方法,用来接收worker处发送过来的注册消息,并将该消息保存到内存中,然后向worker回复注册成功消息(RegisteredWorker)
(1)定义一个包含所有注册信息的类(此处自己定义的是WorkInfo)
(2)创建一个map,并将该信息以worker的id为key,workerInfo类为value存入该map(即存入了内存)
- worker处接收注册成功的信息,并启动一个定时器,定时向Master发送心跳信息
由于worker端的定时器不能将定时信息发送给Master处(worker与Master处于两个进程中),所以其先将心跳信息(Heartbeat)发送给自己,然后worker自己接收到这个信息再发送给Master
- Master匹配并接收Worker发送过来的心跳汇报消息(此处涉及每次心跳时间的更新)
- Master自己创建一个定时器,定期检查是否有deadWorker,用来剔除该worker
代码:
worker
package com._51doit.akka.rpc
import java.util.UUID
import akka.actor.{Actor, ActorRef, ActorSelection, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
import scala.concurrent.duration._
/**
* Worker Actor最好在构造方法执行之后,receive方法之前,向Master建立连接
*/
class Worker extends Actor {
var masterRef: ActorSelection = _
val WORKER_ID = UUID.randomUUID().toString
// 生命周期方法(一定并且按一定顺序执行的方法)
// 在构造方法之后,receive方法之前,执行一次preStart
override def preStart(): Unit = {
// Worker向Master建立网络连接,得到一个master代理对象
masterRef = context.actorSelection("akka.tcp://MASTER_ACTOR_SYSTEM@localhost:8888/user/MASTER_ACTOR")
// //Worker向Master发送注册的信息
masterRef ! RegisterWorker(WORKER_ID, 4096, 8)
}
// 重写用于接收消息的方法
override def receive: Receive = {
//Master反馈给Worker的消息
case RegisteredWorker => {
//导入隐式转换
import context.dispatcher
//启动一个定时器,定期向Master发送心跳,使用Akka框架封装的定时器
//定期给自己发送消息,然后再给Master发送心跳
//参数依次为第一次的延迟时间,多少时间执行一次,消息发送给谁(此处找不到master,发送给masterRef代理对象也不行,),发送的消息
context.system.scheduler.schedule(0 millisecond, 5000 millisecond, self, SendHeartbeat)
}
//自己给自己发送的消息
case SendHeartbeat => {
//可以进行一些逻辑判断
//向Master发送心跳消息
masterRef ! Heartbeat(WORKER_ID)
}
}
}
object Worker{
def main(args: Array[String]): Unit = {
val host = "localhost"
val port = 7777
val configStr =
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider" // 负责通信的核心类,有必要可以自己定义
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin // 此方法负责切割
val conf = ConfigFactory.parseString(configStr)
val workerActorSystem = ActorSystem("WORKER_ACTOR_SYSTEM", conf)
val workerActor: ActorRef = workerActorSystem.actorOf(Props[Worker], name = "WORKER_ACTOR")
workerActor.!("liZhi")
}
}
Master
package com._51doit.akka.rpc
import akka.actor.{Actor, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
import scala.concurrent.duration._
import scala.collection.mutable
// Actor编程模型进行通信,需要让其与AKKA发生点关系(此处实现Actor特质)
class Master extends Actor {
// 定义一个map,用来接收数据
val id2Worker = new mutable.HashMap[String, WorkerInfo]()
// 在preStart中启动定时器,定期检查超市的Worker,然后剔除
override def preStart(): Unit = {
import context.dispatcher
context.system.scheduler.schedule(0 millisecond, 10000 millisecond, self, CheckTimeOutWorker)
}
override def receive: Receive = {
// Master匹配并接收Worker发送过来的注册消息
case RegisterWorker(id, memory, cores) => {
//将数据封装起来,保存到内存中
val workerInfo: WorkerInfo = new WorkerInfo(id,memory,cores)
id2Worker(id) = workerInfo
//向Worker反馈一个注册成功的消息
sender() ! RegisteredWorker
}
// Master匹配并接收Worker发送过来的心跳汇报消息
case Heartbeat(workerId) => {
// 根据workId去map中查找相对应的WorkerInfo
if(id2Worker.contains(workerId)){
//根据ID取出WorkerInfo
val workerInfo = id2Worker(workerId)
//获取当前时间
val currentTime = System.currentTimeMillis()
//更新最近一次心跳时间
workerInfo.lastUpdateTime = currentTime
}
}
// 匹配定时器发送的内容,用于提出超时的worker
case CheckTimeOutWorker => {
val currentTime = System.currentTimeMillis()
// 取出map中的值,并计算出超时的worker
val values: Iterable[WorkerInfo] = id2Worker.values
val deadWorkers: Iterable[WorkerInfo] = values.filter(value => currentTime - value.lastUpdateTime > 10000)
// 移除所有超时的worker
deadWorkers.foreach(dw => id2Worker -= dw.id)
println("current alive worker is : " + id2Worker.size)
}
}
}
object Master {
def main(args: Array[String]): Unit = {
val host = "localhost"
val port = 8888
val configStr =
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider" // 负责通信的核心类,有必要可以自己定义
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin // 此方法负责切割
val conf = ConfigFactory.parseString(configStr)
val actorSystem = ActorSystem.apply("MASTER_ACTOR_SYSTEM", conf)
// 通过ActorSystem对象常见Actor(通过反射指定类型的Actor的实例)
val masterActor = actorSystem.actorOf(Props[Master], name = "MASTER_ACTOR")
// 向Actor发送消息
// ! 表示的是发送异步消息
masterActor.!(message = "hah")
}
}
注意:当创建了master actor对象时,AKKA框架底层会自动调用声明周期方法
Message
package com._51doit.akka.rpc // Worker发送给Master的注册消息,case class默认实现了序列化接口
case class RegisterWorker(id: String, memory: Int, cores: Int) //Master发送给Worker注册成功的消息
case object RegisteredWorker //Worker发送给Master的心跳消息
case class Heartbeat(workerId: String) //Worker自己给自己发送的消息(内部消息)
case object SendHeartbeat //Master发送给自己的消息,用于检查超时的Worker
case object CheckTimeOutWorker
WorkInfo
package com._51doit.akka.rpc
class WorkerInfo(val id: String, var memory: Int, var cores: Int) {
var lastUpdateTime: Long = _
// 重写toString方法
override def toString = s"WorkerInfo($id, $memory, $cores)"
}
大数据学习day16------第三阶段-----scala04--------1. 模式匹配和样例类 2 Akka通信框架的更多相关文章
- Scala学习十四——模式匹配和样例类
一.本章要点 match表达式是更好的switch,不会有意外调入下一个分支 如果没有模式能够匹配,会抛出MatchError,可以用case _模式避免 模式可以包含一个随意定义的条件,称做守卫 你 ...
- 大数据学习--day16(集合总体架构--ArrayList--LinkedList)
集合总体架构--ArrayList--LinkedList Collection接口的实现类用法上都有相似的方法.Map同理. List: 特性 : 1. 有索引 2. 有序 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- 猫狗收容所 牛客网 程序员面试金典 C++
猫狗收容所 牛客网 程序员面试金典 C++ 题目描述 有家动物收容所只收留猫和狗,但有特殊的收养规则,收养人有两种收养方式,第一种为直接收养所有动物中最早进入收容所的,第二种为选择收养的动物类型(猫或 ...
- cf Make It Nondeterministic (简单贪心)
有N个人.每个人都有两个名字. 给出这N个人的一个排列.p[1]...p[N]. 现在让每个人挑自己丙个名字中的一个名字.问是否存在一种方案,使得挑出来的N个名字按字典序排完以后正好是p[1]...p ...
- 第01课 OpenGL窗口(3)
接下来的代码段创建我们的OpenGL窗口.我花了很多时间来做决定是否创建固定的全屏模式这样不需要许多额外的代码,还是创建一个容易定制的友好的窗口但需要更多的代码.当然最后我选择了后者.我经常在EMai ...
- shell 中小括号,中括号,大括号的区别
一.小括号,圆括号() 1.单小括号 () ①命令组.括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用.括号中多个命令之间用分号隔开,最后一个命令可以没有分号, ...
- FAIL : Keyword 'BuiltIn.Log' expected 1 to 6 arguments, got 12(解决方法)
RF运行关键字:Run Keyword If ,log输出报错"FAIL : Keyword 'BuiltIn.Log' expected 1 to 6 arguments, got 12. ...
- request truncate large response body
requests.exceptions.ChunkedEncodingError: ('Connection broken: IncompleteRead(0 bytes read, 512 more ...
- 大爽Python入门教程 0-1 安装python
大爽Python入门公开课教案 点击查看教程总目录 一 如何找到下载地址并下载 下面展示找到下载地址的方法步骤 嫌步骤太慢可直接跳到第4步, 查看详细下载地址 使用搜索引擎搜索python 打开搜索结 ...
- 菜鸡的Java笔记 第二十 - java 方法的覆写
1.方法的覆写 当子类定义了与父类中的完全一样的方法时(方法名称,参数类型以及个数,返回值类型)这样的操作就称为方法的覆写 范例:观察方法的覆写 class A{ public void ...
- Unity Ioc 类型初始值设定项引发异常,The type name or alias SqlServer could not be resolved. Please check your configuration file and verify this type name.
先看一下unity的配置信息 <unity> <typeAliases> <typeAlias alias="IDatabase" type=&quo ...
- [bzoj5291]链上二次求和
记$bi=b_{i-1}+ai$,$ci=c_{i-1}+bi$,那么答案就是$\sum_{i=l}^{r}\sum_{j=0}^{n-i}b_{j+i}-bj=(r-l+1)cn-\sum_{i=l ...