伙伴匹配系统(移动端 H5 网站(APP 风格)基于Spring Boot 后端 + Vue3 - 03
伙伴匹配系统(移动端 H5 网站(APP 风格)基于Spring Boot 后端 + Vue3 - 03
项目地址:
开发用户修改页面:后端
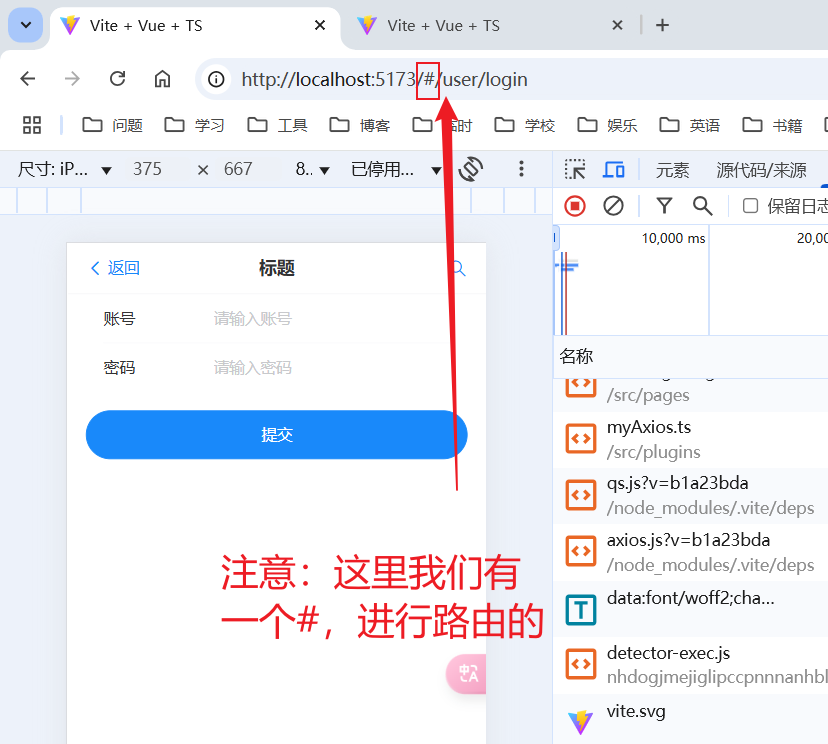
开发用户登录功能:后端
to do
更新 脱敏,bean(注意没有映射,以及逻辑删除注解),以及 xml
前端:抽象通用列表组件
批量导入数据 | 多种方案介绍对比
尽量不要一次性,导入太多数据,而是一点一点的加量导入数据。比如:10,100,1000,10000
导入数据
- 用可视化界面:适合一次性导入,数据量可控。
- 写程序: for 循环,建议分批,不要一把梭哈(可以用接口来控制),要保证可控,幂等,注意:线上环境和测试环境是有区别的。
编写一次性任务:
for 循环插入数据的问题:
- 建立和释放数据连接:
- for 循环是绝对线性的:(并发)
补充:Spring 启动定时任务,@EnableScheduling // 启动定时任务
@EnableScheduling // 启动定时任务
package com.rainbowsea.yupao;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@MapperScan("com.rainbowsea.yupao.mapper")
@EnableScheduling // 启动定时任务
public class YuPaoApplication {
public static void main(String[] args) {
SpringApplication.run(YuPaoApplication.class, args);
}
}
并发编程(多线程池)
并发要注意执行的先后顺序无所谓,不要用到非并发类的集合(eg: 不要用 List 默认是线程不安全的),要转成线程安全的集合。
for 循环插入数据的特点:
- 频繁建立和释放数据库连接(用批量查询解决)
- for 循环是绝对线性的(可以并发提速)
使用简单的 for 循环进行一个并发提速插入,批量元素内容。
package com.rainbowsea.yupao.one;
import com.rainbowsea.yupao.mapper.UserMapper;
import com.rainbowsea.yupao.model.User;
import com.rainbowsea.yupao.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.stereotype.Component;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
import java.util.ArrayList;
@Component
@RunWith(SpringRunner.class)
public class InsertUsers {
@Resource
private UserService userService;
/**
* 批量插入用户
*/
// @Scheduled(fixedDelay = 5000, fixedRate = Long.MAX_VALUE)
@Test
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch(); // 监视查看内容信息
stopWatch.start(); // 开始时间点
ArrayList<User> userList = new ArrayList<>(); // ArrayList<>() 支持并发,不存在多并发问题
final int INSERT_NUM = 100000; // shift + ctrl + u 切换为大写
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeuyupi");
user.setAvatarUrl("https://profile-avatar.csdnimg.cn/2f8ef0ed68a647bcad04088152e00c69_weixin_61635597.jpg!1");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setIsDelete(0);
user.setPlanetCode("1111111");
userList.add(user);
}
userService.saveBatch(userList, 1000);
stopWatch.stop(); // 结束时间点
System.out.println(stopWatch.getTotalTimeMillis()); // 打印显示提示信息
}
}
使用定时任务,完成并发处理
package com.rainbowsea.yupao.one;
import com.rainbowsea.yupao.mapper.UserMapper;
import com.rainbowsea.yupao.model.User;
import com.rainbowsea.yupao.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.stereotype.Component;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
import java.util.ArrayList;
@Component
@RunWith(SpringRunner.class)
public class InsertUsers {
@Resource
private UserService userService;
/**
* 批量插入用户
*/
@Scheduled(fixedDelay = 5000, fixedRate = Long.MAX_VALUE)// 注意主启动类上要加上,@EnableScheduling // 启动定时任务
// @Test
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch(); // 监视查看内容信息
stopWatch.start(); // 开始时间点
ArrayList<User> userList = new ArrayList<>();
final int INSERT_NUM = 100000; // shift + ctrl + u 切换为大写
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeuyupi");
user.setAvatarUrl("https://profile-avatar.csdnimg.cn/2f8ef0ed68a647bcad04088152e00c69_weixin_61635597.jpg!1");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setIsDelete(0);
user.setPlanetCode("1111111");
userList.add(user);
}
userService.saveBatch(userList, 1000);
stopWatch.stop(); // 结束时间点
System.out.println(stopWatch.getTotalTimeMillis()); // 打印显示提示信息
}
}
采用异步执行,并发执行的方式
package com.rainbowsea.yupao.one;
import com.rainbowsea.yupao.mapper.UserMapper;
import com.rainbowsea.yupao.model.User;
import com.rainbowsea.yupao.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.stereotype.Component;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CompletableFuture;
@Component
@RunWith(SpringRunner.class)
public class InsertUsers {
@Resource
private UserService userService;
/**
* 批量插入用户
*/
// @Scheduled(fixedDelay = 5000, fixedRate = Long.MAX_VALUE)
@Test
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch(); // 监视查看内容信息
stopWatch.start(); // 开始时间点
final int INSERT_NUM = 100000; // shift + ctrl + u 切换为大写
List<CompletableFuture<Void>> futureList = new ArrayList<>(); // 列表
// 分 10 组
int j = 0;
for (int i = 0; i < INSERT_NUM; i++) {
List<User> userList = new ArrayList<>();
while (true) {
j++;
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeuyupi");
user.setAvatarUrl("https://profile-avatar.csdnimg.cn/2f8ef0ed68a647bcad04088152e00c69_weixin_61635597.jpg!1");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setIsDelete(0);
user.setPlanetCode("1111111");
userList.add(user);
if(j % 10000 == 0) {
break;
}
}
// 异步执行
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("threadName:" + Thread.currentThread().getName());
userService.saveBatch(userList, 1000);
});
futureList.add(future);
}
CompletableFuture.allOf(futureList.toArray(new CompletableFuture[]{})).join();
stopWatch.stop(); // 结束时间点
System.out.println(stopWatch.getTotalTimeMillis()); // 打印显示提示信息
}
}
注意:使用并发时要注意数据的插入先后顺序是否无所谓。
并发时不要用到非并发类的集合。
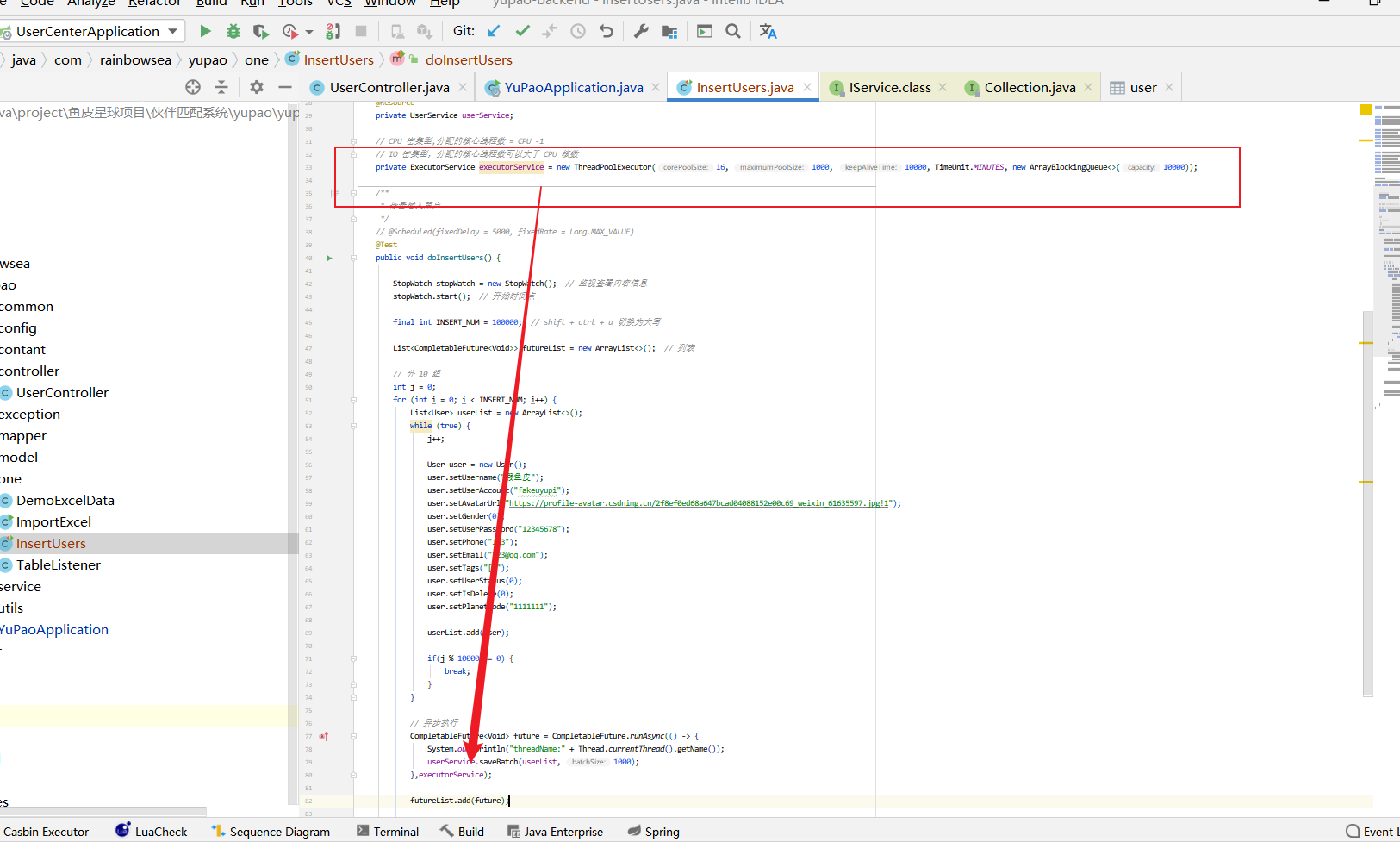
建立执行器(线程池),自己创建线程池,进行一个获取自己创建的线程池,执行并发,获取线程池连接。
private ExecutorService executorService = new ThreadPoolExecutor(16, 1000, 10000, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10000));
package com.rainbowsea.yupao.one;
import com.rainbowsea.yupao.mapper.UserMapper;
import com.rainbowsea.yupao.model.User;
import com.rainbowsea.yupao.service.UserService;
import org.apache.tomcat.util.threads.ThreadPoolExecutor;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.stereotype.Component;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.TimeUnit;
@Component
@RunWith(SpringRunner.class)
public class InsertUsers {
@Resource
private UserService userService;
// CPU 密集型,分配的核心线程数 = CPU -1
// IO 密集型,分配的核心线程数可以大于 CPU 核数
private ExecutorService executorService = new ThreadPoolExecutor(16, 1000, 10000, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10000));
/**
* 批量插入用户
*/
// @Scheduled(fixedDelay = 5000, fixedRate = Long.MAX_VALUE)
@Test
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch(); // 监视查看内容信息
stopWatch.start(); // 开始时间点
final int INSERT_NUM = 100000; // shift + ctrl + u 切换为大写
List<CompletableFuture<Void>> futureList = new ArrayList<>(); // 列表
// 分 10 组
int j = 0;
for (int i = 0; i < INSERT_NUM; i++) {
List<User> userList = new ArrayList<>();
while (true) {
j++;
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeuyupi");
user.setAvatarUrl("https://profile-avatar.csdnimg.cn/2f8ef0ed68a647bcad04088152e00c69_weixin_61635597.jpg!1");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setIsDelete(0);
user.setPlanetCode("1111111");
userList.add(user);
if(j % 10000 == 0) {
break;
}
}
// 异步执行
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("threadName:" + Thread.currentThread().getName());
userService.saveBatch(userList, 1000);
},executorService);
futureList.add(future);
}
CompletableFuture.allOf(futureList.toArray(new CompletableFuture[]{})).join();
stopWatch.stop(); // 结束时间点
System.out.println(stopWatch.getTotalTimeMillis()); // 打印显示提示信息
}
}
连接池参数设置:
// CPU 密集型:分配的核心线程数 = CPU - 1
// IO 密集型:分配的核心线程数可以大于 CPU 核数
页面加载太慢
- 优化:数据库慢,用户不登录,用户查看的数据是一样的,既然是一样的,我们就不需要重复查多次了,那我们就可以预先把数据查出来,放到一个更快读取的地方,不用再查数据库了。缓存。为了防止第一个用户,查询的时候,没有走缓存——>预加载缓存,定时更新缓存。(可以采用定时任务)
- 多个机器都要执行任务呢?(分布式锁:控制同一时间只有一台机器去执行定时任务,其他机器不用重复执行了)
- 比较慢的地方,可以想想可不可以复用,减少慢的次数。
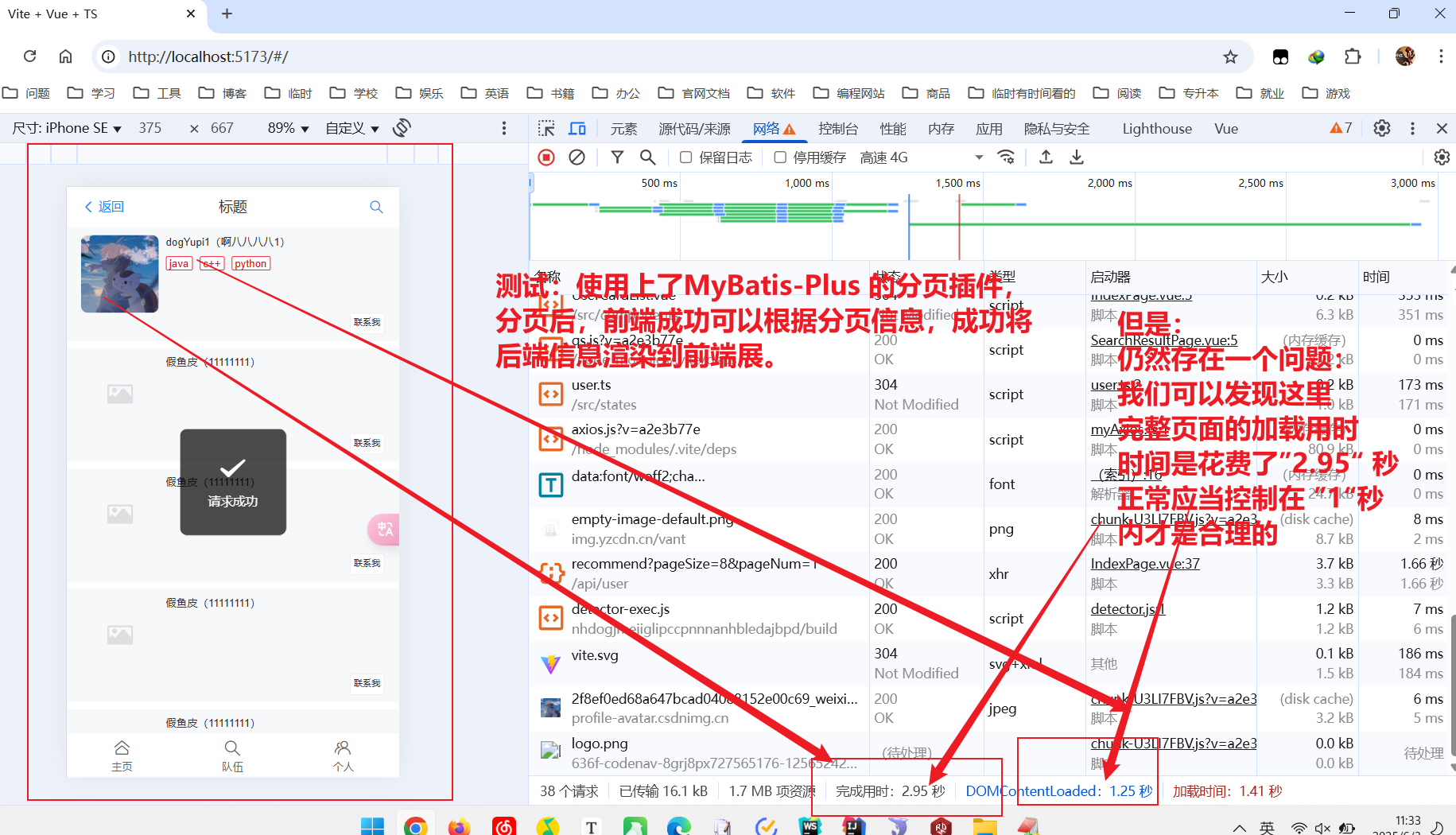
多个数据,前端显示,进行分页处理,如果一下子将 10W 个数据信息给前端进行渲染,前端是无法渲染处理的,是会直接报错处理的,所以这里进行一个 MyBatis-Plus 的一个分页插件进行处理,运行观察执行的 SQL 日志,并不是直接一次性将 10W / 所有数据查询出来,而是通过一个分页查询,查询其中所需的一部分,发送给前端,提高查询效率,同时避免前端接收过多数据,渲染加载数据失败。
/**
* 首页 recommend 推荐显示内容,同时进行了分页处理
*
* @param request
* @return
*/
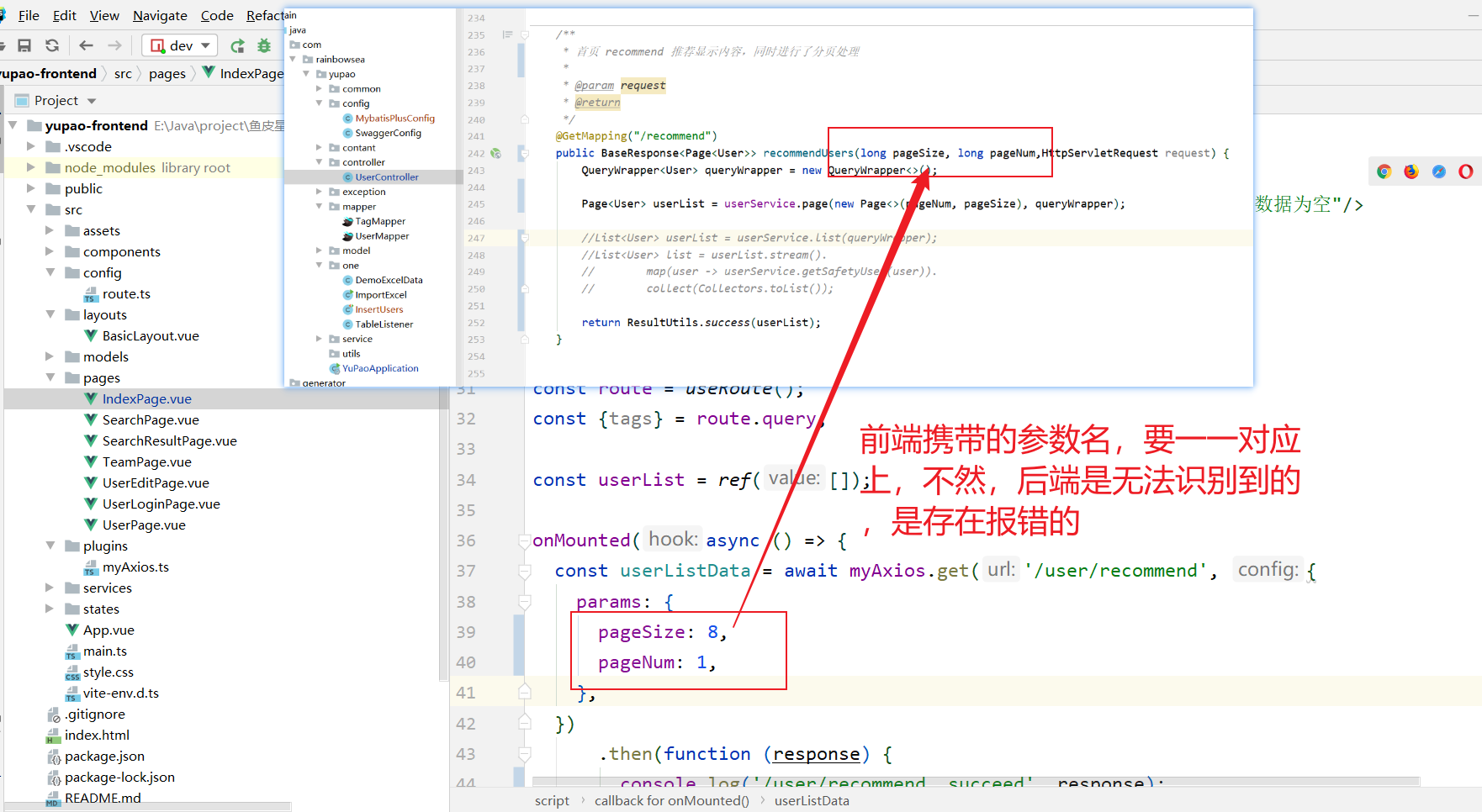
@GetMapping("/recommend")
public BaseResponse<Page<User>> recommendUsers(long pageSize, long pageNum,HttpServletRequest request) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Page<User> userList = userService.page(new Page<>(pageNum, pageSize), queryWrapper);
//List<User> userList = userService.list(queryWrapper);
//List<User> list = userList.stream().
// map(user -> userService.getSafetyUser(user)).
// collect(Collectors.toList());
return ResultUtils.success(userList);
}
同时需要在 在 Spring Boot 项目中,你可以通过 Java 配置来添加分页插件:
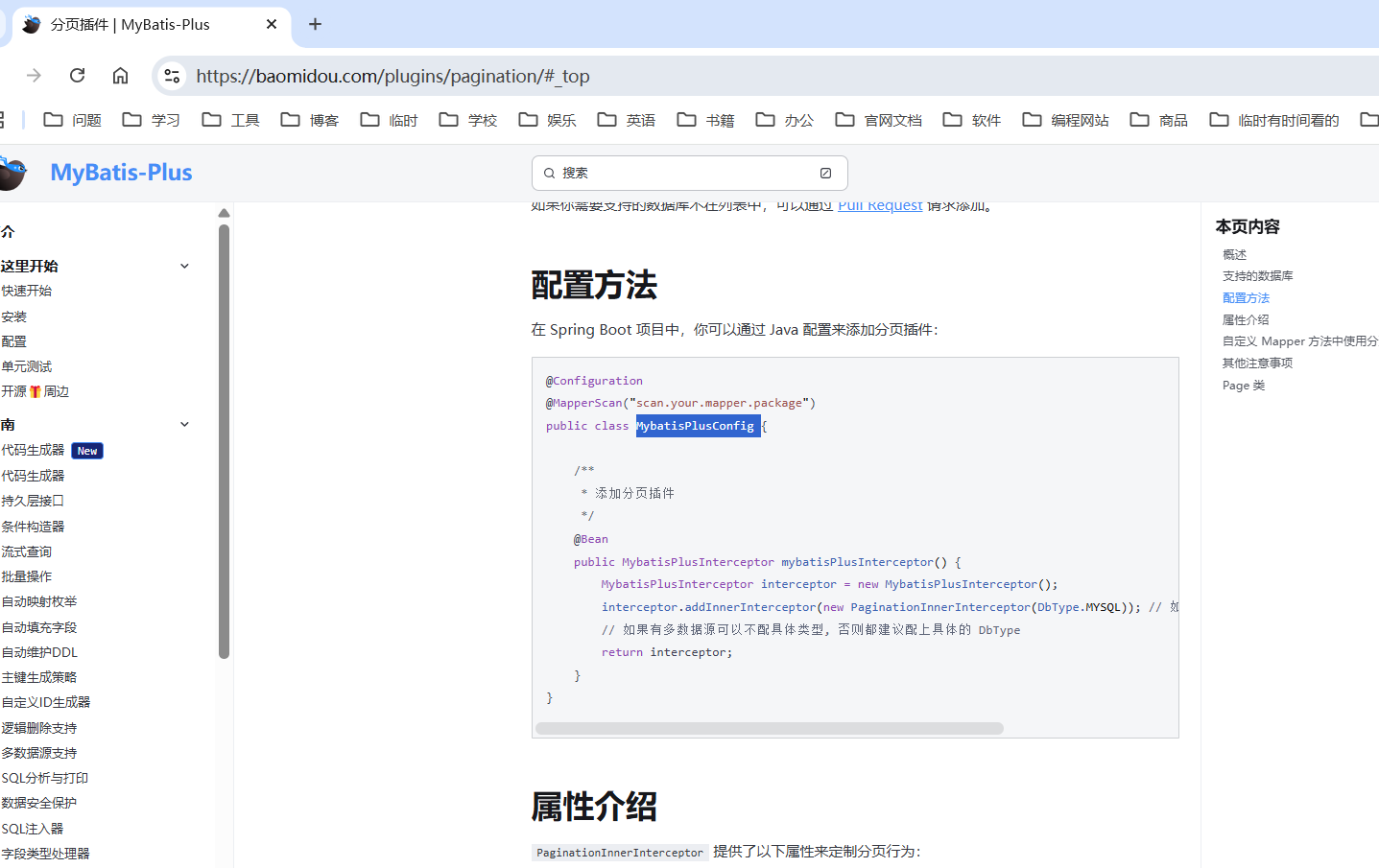
@Configuration
@MapperScan("scan.your.mapper.package")
public class MybatisPlusConfig {
/**
* 添加分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); // 如果配置多个插件, 切记分页最后添加
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
}
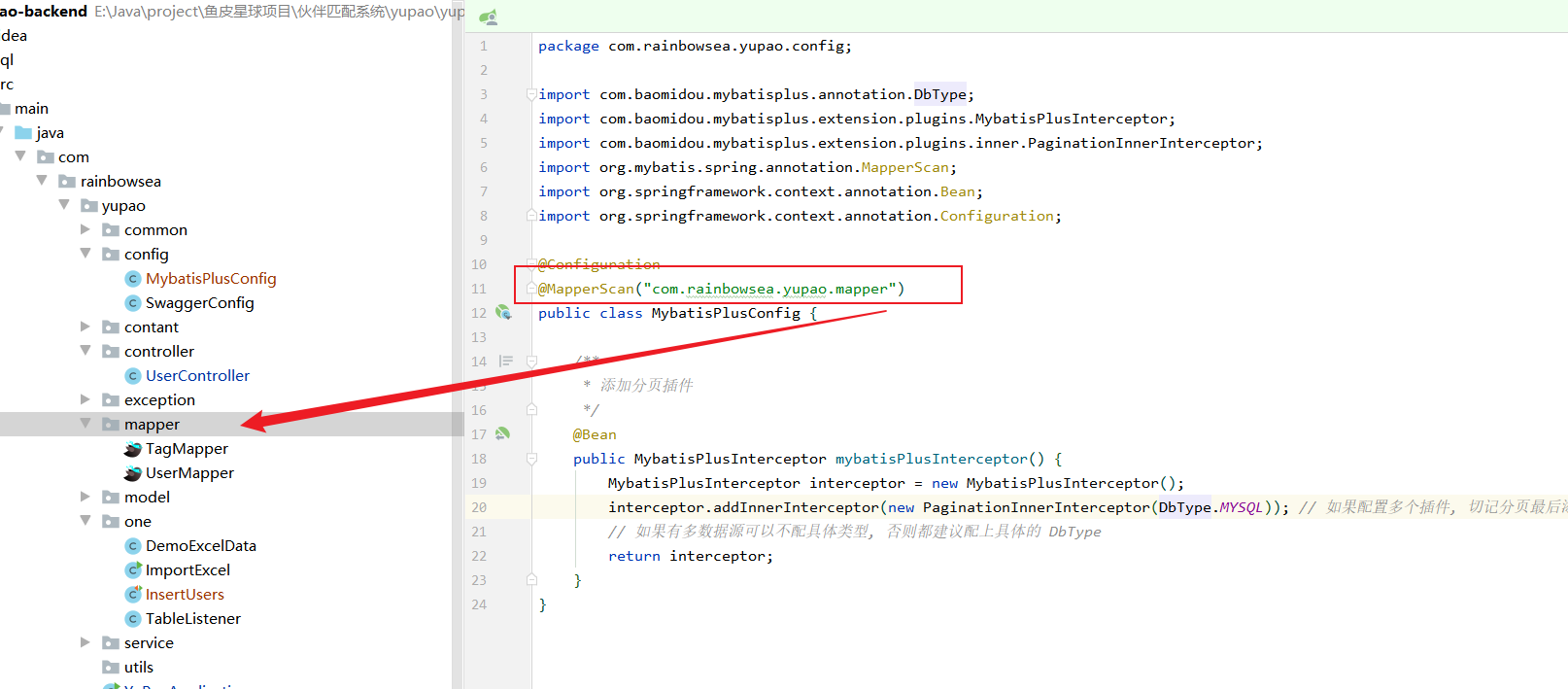
前端添加上相关,分页携带的数据信息:
<template>
<user-card-list :user-list="userList"/>
<!-- <van-card-->
<!-- v-for="user in userList"-->
<!-- :desc="user.prfile"-->
<!-- :title="`${user.username} (${user.planetCode}})`"-->
<!-- :thumb="user.avatarUrl"-->
<!-- >-->
<!-- <template #tags>-->
<!-- <van-tag plain type="danger" v-for="tag in user.tags" style="margin-right: 8px; margin-top: 8px">-->
<!-- {{tag}}-->
<!-- </van-tag>-->
<!-- </template>-->
<!-- <template #footer>-->
<!-- <van-button size="mini">联系我</van-button>-->
<!-- </template>-->
<!-- </van-card>-->
<!-- 搜索提示 -->
<van-empty v-if="!userList || userList.length < 1" description="数据为空"/>
</template>
<script setup>
import {onMounted, ref} from 'vue';
import {useRoute} from "vue-router";
import myAxios from "../plugins/myAxios";
import {Toast} from "vant";
import UserCardList from "../components/UserCardList.vue";
const route = useRoute();
const {tags} = route.query;
const userList = ref([]);
onMounted(async () => {
const userListData = await myAxios.get('/user/recommend', {
params: {
pageSize: 8,
pageNum: 1,
},
})
.then(function (response) {
console.log('/user/recommend succeed', response);
Toast.success("请求成功")
return response?.data?.records;
})
.catch(function (error) {
console.error('/user/recommend error', error);
Toast.fail('请求失败')
})
console.log("数据数据:", userListData)
if (userListData) {
userListData.forEach(user => {
if (user.tags) {
user.tags = JSON.parse(user.tags);
}
})
userList.value = userListData;
}
})
</script>
<style scoped>
</style>
运行观察执行的 SQL 日志,并不是直接一次性将 10W / 所有数据查询出来,而是通过一个分页查询,查询其中所需的一部分,发送给前端,提高查询效率,同时避免前端接收过多数据,渲染加载数据失败。
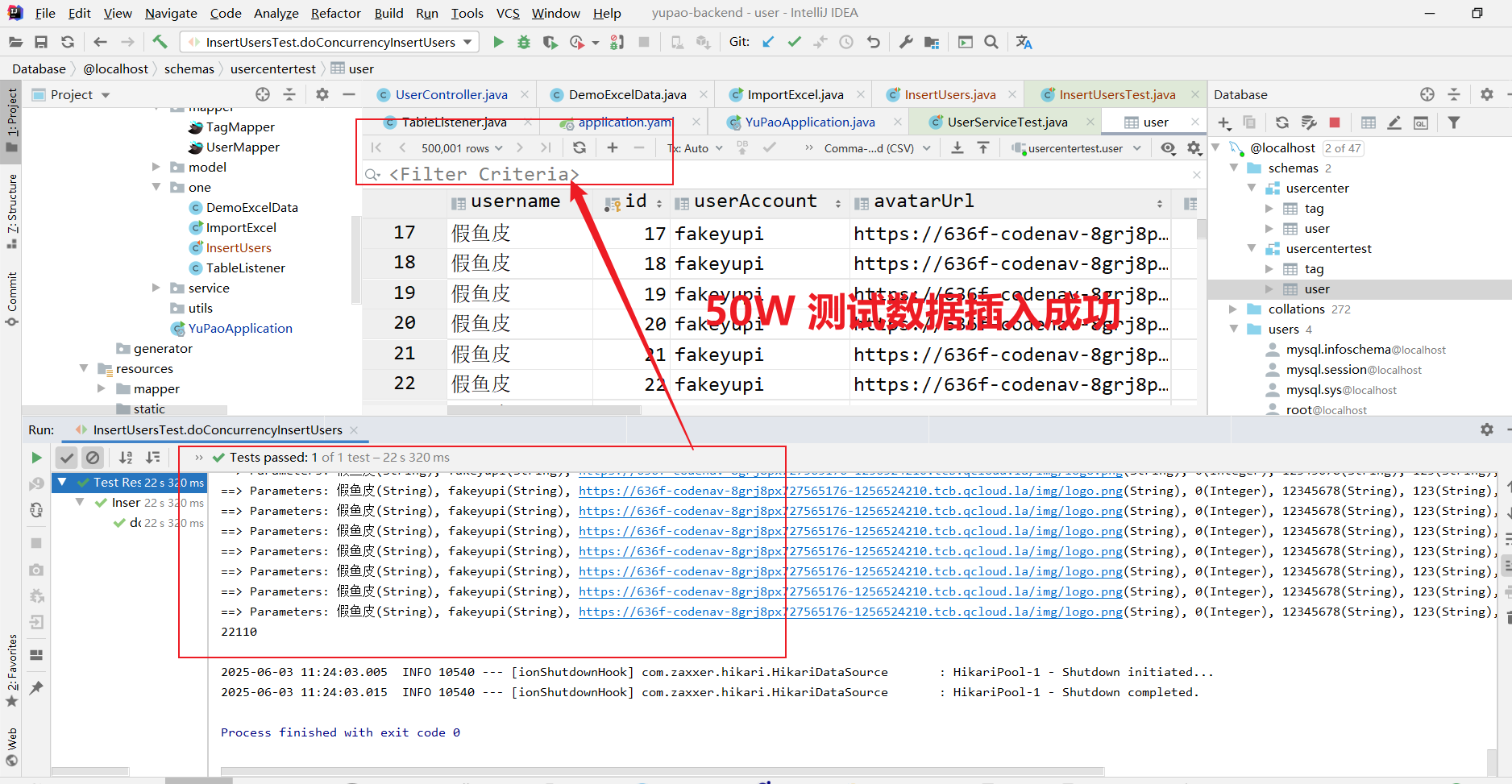
- 首先,模拟插入 50W 条数据,测试。这里我们创建一个用于测试的数据库名为 "usercentertest"
create table tag
(
id bigint auto_increment comment 'id'
primary key,
tagName varchar(256) null comment '标签名称',
userId bigint null comment '用户id',
parenId bigint null comment '父标签 id',
isParent tinyint null comment '0 - 不是, 1- 父标签',
createTime datetime default CURRENT_TIMESTAMP null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP null comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除 0 1(逻辑删除)',
constraint uniIdx_tagName
unique (tagName)
)
comment '标签';
create index idx_userId
on tag (userId);
create table user
(
username varchar(256) null comment '用户昵称',
id bigint auto_increment comment 'id'
primary key,
userAccount varchar(256) null comment '账号',
avatarUrl varchar(1024) null comment '用户头像',
gender tinyint null comment '性别',
userPassword varchar(512) not null comment '密码',
phone varchar(128) null comment '电话',
email varchar(512) null comment '邮箱',
userStatus int default 0 not null comment '状态-0-正常',
createTime datetime default CURRENT_TIMESTAMP null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP null comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除 0 1(逻辑删除)',
userRole int default 0 not null comment '用户角色 0- 普通用户 1 - 管理员 2 - vip',
planetCode varchar(512) null comment '用户的编号',
tags varchar(1024) null comment '标签列表 json',
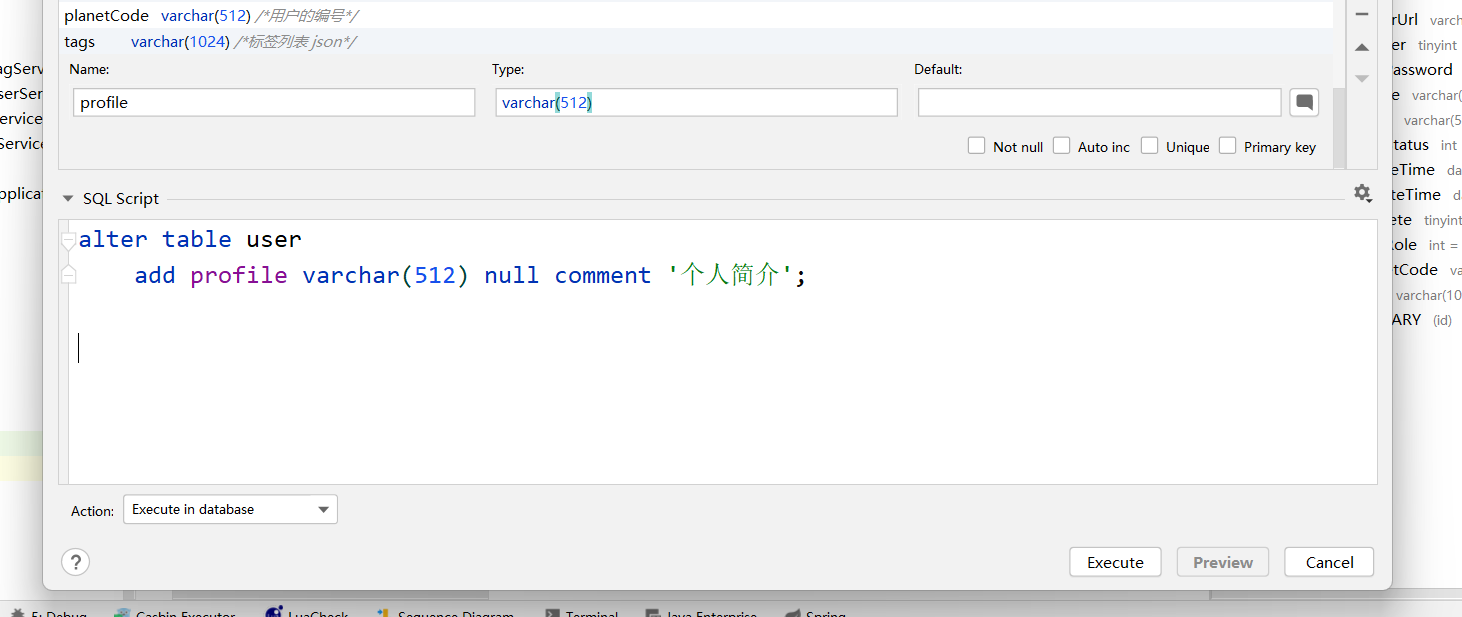
profile varchar(512) null comment '个人简介'
)
comment '用户';
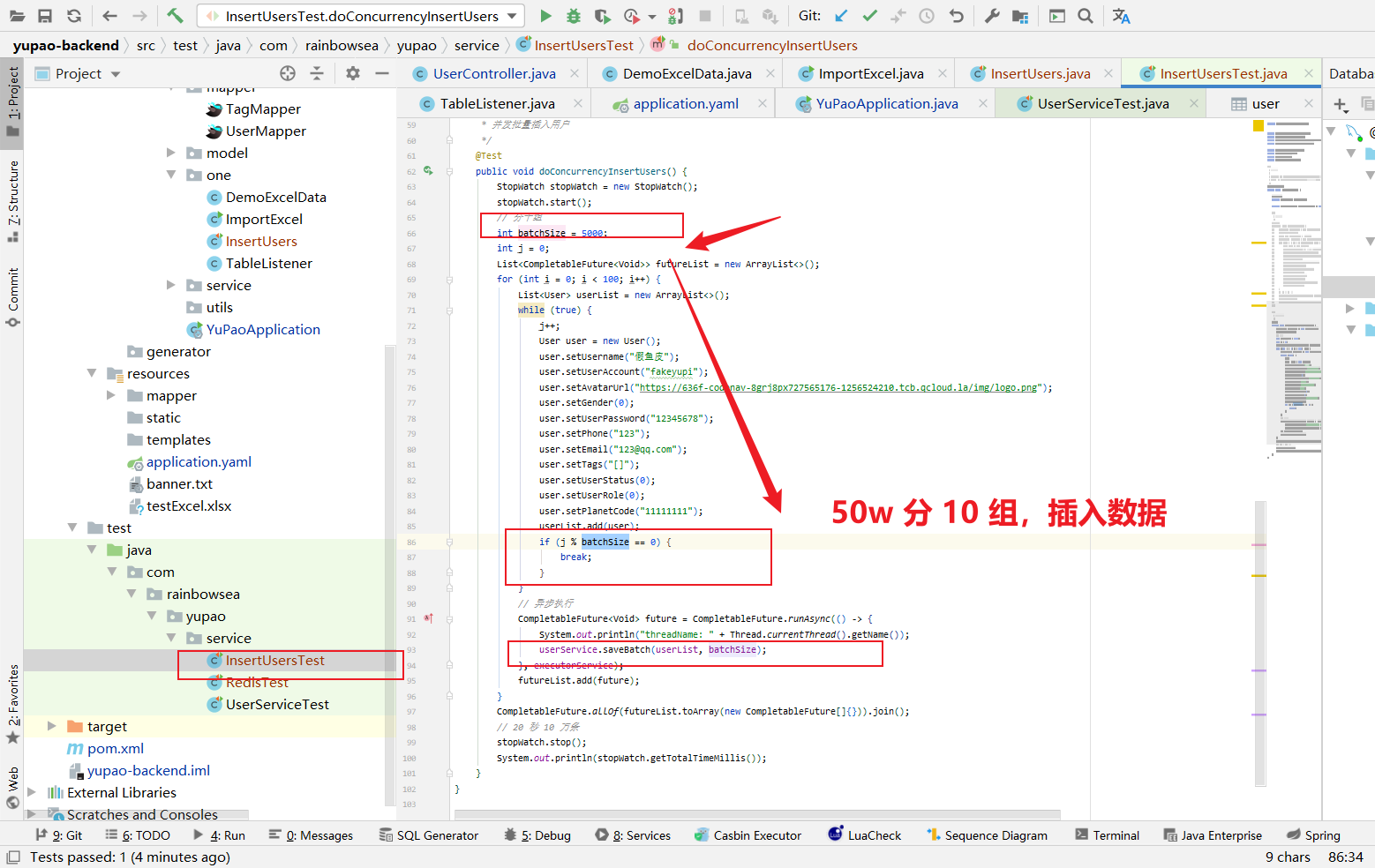
这里我们利用 for 批量插入 50W 条数据,注意:对于这种大数据插入的测试,必须分组,分批进行,防止插入时中间发生报错处理。
package com.yupi.yupao.once.importuser;
import com.yupi.yupao.mapper.UserMapper;
import com.yupi.yupao.model.domain.User;
import org.springframework.stereotype.Component;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
/**
* 导入用户任务
*
* @author <a href="https://github.com/liyupi">程序员鱼皮</a>
* @from <a href="https://yupi.icu">编程导航知识星球</a>
*/
@Component
public class InsertUsers {
@Resource
private UserMapper userMapper;
/**
* 批量插入用户
*/
// @Scheduled(initialDelay = 5000, fixedRate = Long.MAX_VALUE)
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch();
System.out.println("goodgoodgood");
stopWatch.start();
final int INSERT_NUM = 1000;
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeyupi");
user.setAvatarUrl("https://636f-codenav-8grj8px727565176-1256524210.tcb.qcloud.la/img/logo.png");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setUserRole(0);
user.setPlanetCode("11111111");
userMapper.insert(user);
}
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
}
}
package com.yupi.yupao.service;
import com.yupi.yupao.model.domain.User;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
/**
* 导入用户测试
*
* @author <a href="https://github.com/liyupi">程序员鱼皮</a>
* @from <a href="https://yupi.icu">编程导航知识星球</a>
*/
@SpringBootTest
public class InsertUsersTest {
@Resource
private UserService userService;
private ExecutorService executorService = new ThreadPoolExecutor(40, 1000, 10000, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10000));
/**
* 批量插入用户
*/
@Test
public void doInsertUsers() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
final int INSERT_NUM = 100000;
List<User> userList = new ArrayList<>();
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("原_创 【鱼_皮】https://t.zsxq.com/0emozsIJh");
user.setUserAccount("fakeyupi");
user.setAvatarUrl("https://636f-codenav-8grj8px727565176-1256524210.tcb.qcloud.la/img/logo.png");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setUserRole(0);
user.setPlanetCode("11111111");
userList.add(user);
}
// 20 秒 10 万条
userService.saveBatch(userList, 10000);
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
}
/**
* 并发批量插入用户
*/
@Test
public void doConcurrencyInsertUsers() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 分十组
int batchSize = 5000;
int j = 0;
List<CompletableFuture<Void>> futureList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
List<User> userList = new ArrayList<>();
while (true) {
j++;
User user = new User();
user.setUsername("假鱼皮");
user.setUserAccount("fakeyupi");
user.setAvatarUrl("https://636f-codenav-8grj8px727565176-1256524210.tcb.qcloud.la/img/logo.png");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123");
user.setEmail("123@qq.com");
user.setTags("[]");
user.setUserStatus(0);
user.setUserRole(0);
user.setPlanetCode("11111111");
userList.add(user);
if (j % batchSize == 0) {
break;
}
}
// 异步执行
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("threadName: " + Thread.currentThread().getName());
userService.saveBatch(userList, batchSize);
}, executorService);
futureList.add(future);
}
CompletableFuture.allOf(futureList.toArray(new CompletableFuture[]{})).join();
// 20 秒 10 万条
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
}
}
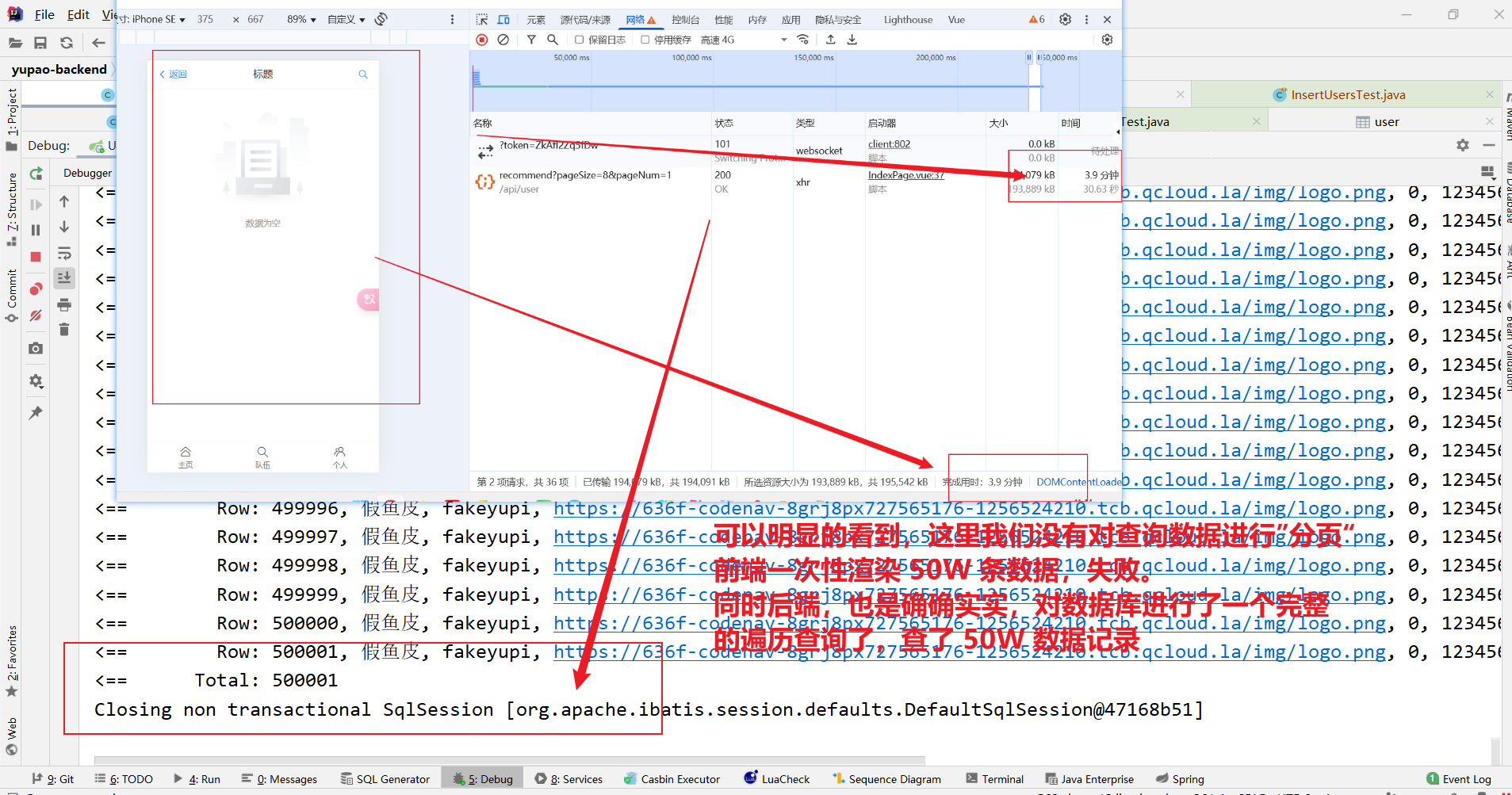
访问前端,查看前端是否会因为 50 W 数据,渲染加载失败。
这里未使用 MyBatis-Plus 进行分页查询,前端渲染失败。
使用了 MyBatis-Plus 分页插件,测试的效果
关于:页面加载太慢的问题,如下:使用缓存和分布式缓存策略,解决。
缓存和分布式缓存
数据查询慢怎么办?
- 用缓存:提前把数据取出来保存好(通常保存到读写更快的介质,eg 内存),就可以更快地读写。
缓存:
- Redis(分布式缓存)
- memcached(分布式)
- Etcd( 云原生架构的一个分布式存储,存储配置,扩容能力)
进程(单机)缓存
- ehcache
- Java 内存集合,如 HashMap
- Caffeine ( Java 内存缓存性能之王,高性能)
- Google Guava
- 分库分表
- 提前查询
Java 操作 Redis
Spriing Data Redis(推荐)
地址:https://mvnrepository.com/artifact/org.springframework.data/spring-data-redis
Spring Data : 通用的数据访问框架,定义了一组 增删改查的接口。
还可以操作:MySQL,Redis,JPA
使用方式如下:
- 引入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.6.4</version>
</dependency>
也可以添加上:Lettuce是一个高级redis客户端,支持高级的redis特性,比如Sentinel、集群、流水线、自动重新连接和redis数据
<!-- https://mvnrepository.com/artifact/io.lettuce/lettuce-core -->
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.1.6.RELEASE</version>
</dependency>
- 配置 Redis 地址
spring:
# redis 配置
redis:
port: 6379
host: localhost
database: 0 # 显式使用的是 Redis 0 号数据库
Redis 数据结构:
- String 字符串类型:name:"yupi"
- List 列表:names:["yupi","dogyupi"]。 List 和 数组的区别。数组的大小是固定的,而 List 大小是动态的
- Set 集合:names:["yupi","dogyupi"](值不重复)
- Hash 哈希:nameAge:
- Zset 集合:names: '{yupi - 9,dogyupi - 12 }' 适合排行榜
高级:
- bloomfilter (布隆过滤器,主要从大量的数据中快速过滤值,比如邮件黑名单拦截)
- geo(计算地理位置)
- hyperloglog (pv / uv)
- pub / sub(发布订阅,类似消息队列)
- BitMap (100101010101010101010101)
引入一个新库时,记得先写测试类。
测试:使用成功连接上了 Redis ,是否可以成功操作 Redis 数据库
package com.rainbowsea.yupao.service;
import com.rainbowsea.yupao.model.User;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import javax.annotation.Resource;
@SpringBootTest
public class RedisTest {
@Resource
private RedisTemplate redisTemplate; // 实例化 操作 Redis 的实例模板
@Test
void test() {
ValueOperations valueOperations = redisTemplate.opsForValue();
// 增
valueOperations.set("yupiString","dog");
valueOperations.set("yupiInt",1);
valueOperations.set("yupiDouble",2.0);
User user = new User();
user.setId(1L);
user.setUsername("yupi");
valueOperations.set("yupiUser",user);
// 查
Object yupi = valueOperations.get("yupiString");
Assertions.assertTrue("dog".equals((String)yupi));
yupi = valueOperations.get("yupiInt");
Assertions.assertTrue(1 == (Integer) yupi);
yupi = valueOperations.get("yupiDouble");
Assertions.assertTrue(2.0 == (Double) yupi);
System.out.println(valueOperations.get("yupiUser"));
}
}
Reids 自定义序列化:RedisTemplateConfig
为了防止写入的 Redis 的数据乱码,浪费空间等,可以自定义序列化器。示例代码如下:
package com.yupi.yupao.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.RedisSerializer;
@Configuration
public class RedisTemplateConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
redisTemplate.setKeySerializer(RedisSerializer.string());
return redisTemplate;
}
}

设计缓存 key
不同用户看到的数据不同。
建议格式:
systemID:moduleID:funcu: (注意:就是不要和别的冲突,因为可能存在多个人/项目共用一个 Redis 缓存)
eg:这里我们设计:**yupao:user:recommed:userId**
**注意:Redis 内存不能无限增加,一定要设置过期时间。Redis 内存是有限的,而且在服务器当中特别贵。非常重要 **
缓存,运行测试:
伙伴匹配系统(移动端 H5 网站(APP 风格)基于Spring Boot 后端 + Vue3 - 03的更多相关文章
- 基于Spring Boot、Spring Cloud、Docker的微服务系统架构实践
由于最近公司业务需要,需要搭建基于Spring Cloud的微服务系统.遍访各大搜索引擎,发现国内资料少之又少,也难怪,国内Dubbo正统治着天下.但是,一个技术总有它的瓶颈,Dubbo也有它捉襟见肘 ...
- 基于Spring Boot的在线问卷调查系统的设计与实现+论文
全部源码下载 # 基于Spring Boot的问卷调查系统 ## 介绍 > * 本项目的在线问卷调查调查系统是基于Spring Boot 开发的,采用了前后端分离模式来开发. > * 前端 ...
- multipages-generator今日发布?!妈妈再也不用担心移动端h5网站搭建了!
本文适合的读者???? 现在在手淘,京东,今日头条,美柚等过亿用户的手机app中的,都常见h5网页,他们有更新快,灵活,便于分享和传播的特性.这里有他们中的几个h5的例子:(手淘,美柚).这些a ...
- pc、移动端H5网站 QQ在线客服、群链接代码【我和qq客服的那些事儿】
转载:http://blog.csdn.net/fungleo/article/details/51835368#comments 移动端H5 QQ在线客服链接代码 <a href=" ...
- 基于SpringBoot前后端分离的点餐系统
基于SpringBoot前后端分离的点餐系统 开发环境:主要采用Spring boot框架和小程序开发 项目简介:点餐系统,分成卖家端和买家端.买家端使用微信小程序开发,实现扫码点餐.浏览菜单.下单. ...
- spring boot部署系统--morphling简介
Morphling 简介 Morphling是一套基于Spring Boot 1.5开发的部署系统,依赖简单,一套Mysql即可运行,操作简单明了,适用于百台规模几下机器的运维操作 功能概述 系统部署 ...
- 利用spring boot创建java app
利用spring boot创建java app 背景 在使用spring框架开发的过程中,随着功能以及业务逻辑的日益复杂,应用伴随着大量的XML配置和复杂的bean依赖关系,特别是在使用mvc的时候各 ...
- 基于netty实现rpc框架-spring boot服务端
demo地址 https://gitee.com/syher/grave-netty RPC介绍 首先了解一下RPC:远程过程调用.简单点说就是本地应用可以调用远程服务器的接口.那么通过什么方式调用远 ...
- 支付宝H5、APP支付服务端的区别(php)
php支付宝H5和APP支付1.准备工作需要前往 蚂蚁金服开放平台申请https://openhome.alipay.com/developmentDocument.htm 2.大致流程1.用户添加商 ...
- H5开发APP考题和答案
{ "last_updated": { "$date": 1544276670569 }, "page_count": 1, "a ...
随机推荐
- 弹性公网IP的五大核心优势解析
在云服务架构中,弹性公网IP(EIP)已成为现代企业网络部署的核心组件.与传统固定IP相比,它通过独特的技术机制解决了动态环境下的公网访问难题.以下五大核心优势决定了其不可替代的价值: 一.动态绑定的 ...
- TGCTF 2025 web 个人wp
AAA偷渡阴平(复仇) <?php $tgctf2025=$_GET['tgctf2025']; if(!preg_match("/0|1|[3-9]|\~|\`|\@|\#|\\$| ...
- 如何在FastAPI中轻松实现OAuth2认证并保护你的API?
title: 如何在FastAPI中轻松实现OAuth2认证并保护你的API? date: 2025/06/09 05:16:05 updated: 2025/06/09 05:16:05 autho ...
- 告别图形界面:Windows系统OpenSSH服务部署
前言 士别三日当刮目相待 没想到这么多年过去了,Windows 也不再是以前那个离开了图形界面啥也不是的系统 Windows 10/11 和 Server 2019+ 已内置 OpenSSH Serv ...
- map-HashMap
HashMap 图片~~~ 其他常见的map结构 常见的map结构 常用的Map结构有:hashMap(最常用).hashTable.LinkedHashMap.TreeMap(对存入的键值进行排序) ...
- UFT API
- 五、Linux系统常用调试工具
4.2.ps(查看进程状态) 用途:显示系统中运行的进程及其相关信息,如 PID(进程 ID).CPU 使用率.内存占用等. 常见用法: ps aux # 显示所有进程,包含用户.PID.CPU/内存 ...
- 东方财富服务端开发暑期实习面试,已拿offer!!
这是一位球友投稿的东方财富服务端开发暑期实习面经,问的内容还是比较多的,难度也相对比较大.下面是正文. 最近参与了东方财富服务端开发暑期实习的招聘,并最终收获了 Offer.整个过程持续了大约一周,从 ...
- Sql server 游标处理数据
https://blog.csdn.net/sinat_28984567/article/details/79811887 DECLARE @id INT , @name NVARCHAR(50) - ...
- java实现聊天,服务端与客户端代码(UDP)-狂神改
首先是文件结构: 最后run的是下面两个 代码用的狂神的,不过他写的有点小bug,比如传信息会出现一堆空格(recieve data那里长度不应该用data.lenth()而应该用packet.get ...