RAG越来越不准?你可能忽略了“元数据”的力量
你是否也有这样的困扰?
问大模型一个很具体的问题:“请告诉我A软件的安装方法。”
结果它却信誓旦旦地告诉了你B软件的安装步骤。
在这个过程中,你可能已经花了大量时间解析和清洗上千份文档,接入RAG,但结果仍然不理想。
为什么会这样?
其中一个很重要的原因是,我们花了很多时间构建知识库,却忽略了一个看似不起眼的部分 —— 元数据。
简单来说,元数据就是“描述数据的数据”。比如:
- 文档的元数据:作者、标题、文档类型、创建时间、用户权限等级、...
- 数据的元数据:字段描述、数据来源、更新时间、用户权限等级、...
举个例子:
图书馆中,你找一本书,不只靠书名,还会看作者、出版社、甚至自己的借阅权限。
元数据,正是这些“额外信息”的载体。
同样逻辑也适用于RAG —— 文档多了,就需要元数据来定位、过滤、聚焦内容。
回顾一下RAG,
全称Retrieval-Augmented Generation,中文“检索增强生成”。

简单来说就是“两步”:
- 先从知识库中检索与问题相关的内容
- 把检索结果作为上下文提供给大模型生成答案
在文档比较少的时候,效果看上去还不错。
但随着你积累的文档越来越多,尤其是类似内容的文档(如多个软件的安装手册)混在一起时,问题来了:
文件积累越多,RAG效果越差。
比如“A产品”和“B产品”的安装说明内容相近,RAG就可能命中错误的文档。
问题根源在于:文档的段落内容未明确指出其归属对象 。
以上,就需要给文档添加元数据。

比如:
- 给《A软件安装指南》打上“软件名称:A”
- 所有段落继承这个元数据字段
检索时,只需加一个条件:"软件名称=A",就能直接过滤掉B软件的内容。
接下来,在用户问问题时,引导他选元数据标签,就像聊天软件中@人一样,快速锁定文档范围,例如:“@软件名称:A 请问如何安装?”
不可避免的,用户有时候也会选择多个元数据。
比如,用户问:
“帮我对比产品A和产品B的宣传文档中,产品优势部分的内容。”
然后,选择了这些元数据:
- 产品名:A
- 产品名:B
- 文档类型:产品宣传
你可能自然想到“用AND连接这些条件”,而结果是什么文档都没命中。
因为没有任何一篇文档同时具备“产品A”、“产品B”、“产品宣传”这三项元数据。
更好的方式,是将这些元数据拆成两个组合:
[["产品名:A","文档类型:产品宣传"],["产品名:B","文档类型:产品宣传"]]这就是所谓的“有效元数据组合”。
比如可以这样约定组合策略:
1.每组内的元数据维度不能重复(不能两个产品名放在一组)
2.每组必须覆盖用户问题中明确提到的所有维度
组合策略构建代码示例:
import itertools
from collections import defaultdict
def calculate_tag_combinations(tags):
# 1. 解析标签并按类型分组
tag_groups = defaultdict(list)
for tag in tags:
tag = "".join(tag.split())
tag = tag.replace(":",":")
# 确保标签格式正确
if ":" in tag:
tag_type, _ = tag.split(":", 1)
tag_groups[tag_type].append(tag)
# 2. 检查是否有足够的标签类型
if not tag_groups:
return []
# 3. 生成所有可能的组合
# 使用itertools.product来高效生成笛卡尔积
tag_types = list(tag_groups.keys())
tag_values_by_type = [tag_groups[tag_type] for tag_type in tag_types]
combinations = list(itertools.product(*tag_values_by_type))
# 转换为列表格式
return [str(list(combo)) for combo in combinations]如果遇到更复杂一些的用户问题,比如:
“请对比产品A的技术规范和产品B的宣传文档。”
然后,用户选择了元数据:产品名:A 、产品名:B 、文档类型:产品宣传 、文档类型:技术规范
上面规则会给你四个组合,其中两个是没用的,那么建议通过大模型来提取有效组合。
[ ["产品名:A","文档类型:技术规范"], ["产品名:B","文档类型:产品宣传"]]提示词示例
System prompt
Role
元数据组合提取助手
Goal
根据用户输入的问题和元数据列表,分析匹配的元数据组合的二维列表。
Constraint
元数据组合必须完全来自用户提供的元数据列表,不能添加或修改原有元数据项。
每个组合必须包含用户问题中明确提到的所有相关元数据维度(如产品名、文档类型等)。
组合数量应与问题中需要对比或查询的实体数量一致(如对比两个产品需生成两个组合)。
Workflow
读取并理解用户提供的元数据列表
分析用户输入的问题,识别关键实体和需求
提取问题中明确提到的元数据关键词
将问题中的关键词与元数据列表进行匹配
确定需要组合的元数据维度(单维度或多维度)
根据问题需求构建元数据组合
检查组合是否完整覆盖问题需求
验证组合是否与元数据列表完全匹配
输出最终匹配的元数据组合
确保输出格式符合示例要求
Example
示例1:
用户选择的元数据列表
["产品名: X","产品名: Y","文档类型: 用户手册","文档类型: 快速指南"]
用户输入的问题
请比较产品X的用户手册和产品Y的快速指南的内容差异。
匹配的元数据组合
[ ["产品名:X","文档类型:用户手册"], ["产品名:Y","文档类型:快速指南"]]
示例2:
用户选择的元数据列表
["地区: 华东","地区: 华南","报告类型: 销售分析"]
用户输入的问题
请分析华东和华南地区的销售分析报告。
匹配的元数据组合
[ ["地区:华东","报告类型:销售分析"], ["地区:华南","报告类型:销售分析"]]
## 特别强调
输入[[""]]的二维列表的JSON格式。不要输出其它任何解释说明内容。
User prompt
**用户选择的元数据列表**
{{metadatas}}
**用户输入的问题**
{{query}}
以上,你已经基本理解了如何利用元数据提升RAG效果。
这里还有一些补充的小建议,有助于你更好的维护和使用元数据。
元数据的管理建议
- 字段名与字段值分开管理
建议将元数据的字段名和字段值分开管理,确保所有字段名全局唯一。相同的字段名可以对应多个字段值。具体而言,字段名可在文件库层面统一维护,而各文件的具体字段值则在文件层面进行维护。 - 区分内置与自定义元数据
内置元数据:在文件上传时自动提取或标注,不允许删除和修改,包括:文件名、文件类型(.docx、.jpg、.mp4等)、上传者、上传时间、更新时间、文件来源、文件大小、字数等信息。
自定义元数据:支持文件上传后按需添加和修改,例如:内容摘要、文件类别(合同、报表、手册等)、适用行业、适用区域、适用期限、归属对象等。
元数据的使用建议
除了让大模型自动提取有效元数据组合,还可以为用户提供自定义元数据逻辑关系(如AND/OR)的能力。
当用户选择了两个及以上的元数据后,建议系统自动提示设置 AND/OR 逻辑,并组合成有效的元数据检索条件。例如:
(产品名:A AND 文档类型:技术规范) OR (产品名:B AND 文档类型:产品宣传)
可以参考dify的交互
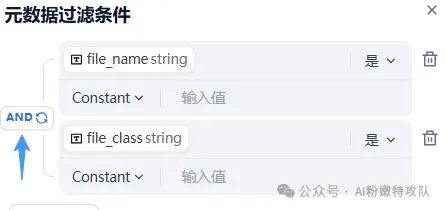
对于存在 OR 关系的多个元数据组合,推荐分别独立检索每个组合,然后在各自检索结果范围内各自执行 RAG,而不是在所有组合的并集范围内统一执行。
这样可以避免部分元数据组合因综合得分较低而被遗漏,从而提升检索的准确性和内容覆盖度。

以上,如果用户输入:“请对比产品A的技术规范与产品B的宣传文档中,技术规格部分的内容。”
并选择了元数据:“产品名:A、产品名:B、文档类型:技术规范、文档类型:产品宣传”
则元数据的RAG流程示例:

用户输入问题+选定元数据
LLM解析,生成有效元数据组合
提炼检索知识点“技术规格”
每组单独检索文档范围,并对文本段进行知识点语义向量检索
聚合所有结果文本段、去重合并、重排序
作为上下文提供给大模型生成最终答案
你的RAG可能比这个复杂,但是加入元数据的逻辑是一样的。
写在最后
元数据不仅是描述信息,更是大模型时代知识治理的基石。
越来越多的团队正在加速知识库的建设,但忽略了元数据的重要性。
也许你已经花了几个月构建文档,但一次简单的“属性标注”,却能让你的RAG真正聪明起来。
下次遇到大模型“答非所问”,别急着怼模型,或许是元数据,还没准备好。
从今天起,遇到RAG的问题,不妨先问一句:“元数据创建了吗?”
以上,既然看到这里了,如果觉得不错,随手点个赞、分享、推荐三连吧,我们,下次再见。
AI粉嫩特攻队 —— 内卷不灭,奋斗不止!关注我,帮你把时间还给创造!
作者:秋水
互动交流,请联系邮箱:fennenqiushui@qq.com
RAG越来越不准?你可能忽略了“元数据”的力量的更多相关文章
- FOC 电流采样为什么不准?你忽略了这个细节
文章目录 1 引言 2 延迟类型及典型时间 3 延迟源详细分析 3.1PWM死区时间插入 3.2 光耦延迟和预驱动器延迟 3.3晶体管开关延迟 3.4其他延迟 4 结语 在电机驱动的FOC控制开发过程 ...
- 我们都忽略了Html5的力量,如果只看成一种技术就大错特错了!
第一部分:Html5市场的力量 我们太忽略Html5的市场力量了.如果你把Html5当作一种技术,就大错特错了!忘掉你的产品,忘掉你的技术,想想移动时代的信息传播和消费场景.作为2B,我们实在是没有重 ...
- 解决setInterval计时器不准的问题
在js中如果打算使用setInterval进行倒数,计时等功能,往往是不准确的,因为setInterval的回调函数并不是到时后立即执行,而是等系统计算资源空闲下来后才会执行.而下一次触发时间则是在s ...
- 【译】自动发现 .NET 5 中代码的潜在错误
写代码是一件令人兴奋的事情,特别是对于 .NET 开发人员来说,平台越来越智能化了.我们现在默认在 .NET SDK 中包含丰富的诊断和代码建议.在您需要安装 NuGet 包或其他独立工具来进行更多 ...
- 时间序列分析算法【R详解】
简介 在商业应用中,时间是最重要的因素,能够提升成功率.然而绝大多数公司很难跟上时间的脚步.但是随着技术的发展,出现了很多有效的方法,能够让我们预测未来.不要担心,本文并不会讨论时间机器,讨论的都是很 ...
- Jimmychoo商城系统总结
一.需求 1.游戏模块 ①在进入H5之前,首先有一个动态的探照灯的动效,然后由"淡出"效果到H5首页. ②在点击"开始游戏"之后会有一段动画演示游戏内容,然后滑 ...
- js定时器优化
在js中如果打算使用setInterval进行倒数,计时等功能,往往是不准确的,因为setInterval的回调函数并不是到时后立即执行,而是等系统计算资源空闲下来后才会执行.而下一次触发时间则是在s ...
- MySQL DBA的修炼与未来(参考篇)
转自:https://blog.csdn.net/xielingshao/article/details/77840101 MySQL DBA的修炼与未来 随着MySQL地位爆炸式的提升, MySQL ...
- DOS程序员手册(二)
2.6存储设备 随着DOS的升级,磁盘存储容量也有了很大扩充.表2.4介绍了软盘容量的增加以 及所支持驱动器型号的数量. ...
- 理解setTimeout和setInterval
setTimeout和setInterval,这两个js函数都是用来定时执行.setTimeout执行一次,setInterval执行多次. 问题出现在今天,使用setInterval是,设置执行速度 ...
随机推荐
- nacos(六): 创建第一个多模块微服务项目(生产者与消费者)
要创建出生产者与消费者一体的多模块项目,总体来说分成三个步骤.分别是先创建出项目主体,再分别创建出生产者与消费者. 步骤一:创建项目主体 1. 先创建一个单体项目作为项目的主题.在这里,我们不用脚手架 ...
- JUC并发—9.并发安全集合二
大纲 1.并发安全的数组列表CopyOnWriteArrayList 2.并发安全的链表队列ConcurrentLinkedQueue 3.并发编程中的阻塞队列概述 4.JUC的各种阻塞队列介绍 5. ...
- 4个Sprint目标的挑战以及解决的技巧
1. Sprint 目标太大 有时,您的团队可能会尝试将过多的任务塞进冲刺中.抵制在冲刺中承担太多的诱惑,因为这会损害你的速度和持续交付的能力. 2. Sprint目标是模糊的 冲刺目标通常是不确定的 ...
- 奥特曼autMan对接BBK-JD扫码登录+微信扫码登录
1.BBK京东扫码容器配置 首先进入root目录 cd /root 拉取镜像创建容器 docker run -dit \ -v $PWD/conf:/data/conf \ -v $PWD/logs: ...
- windows 配置java发布环境
一.jdk安装 1.下载jdk安装文件 2.在"系统变量"下"新建"选项"JAVA_HOME"值为:"jdk"文件夹路径 ...
- .net core datatable 导出 pdf 支持中文
1.nuget 安装 iTextSharp (V4.1.6) to .NET Core. 2.code public DataTable ToDataTable<T>(IEnumerab ...
- Web前端入门第 11 问:HTML 常用标签有多少?全量标签有多少?
HELLO,这里是大熊学习前端开发的入门笔记. 本系列笔记基于 windows 系统. 截止发文,MDN 收录的 HTML 全量标签有 126 个,有 18 个标记已弃用. 名词解释:MDN --- ...
- Golang入门:协程(goroutine)
goroutine goroutine 是 Go 的并发模型的核心概念.为了理解 goroutine,我们来定义几个术语.第一个是进程.进程是程序的实例,由计算机的操作系统运行.操作系统将一些资源(如 ...
- 【踩坑系列】使用httpclient调用第三方接口返回javax.net.ssl.SSLHandshakeException异常
1. 踩坑经历 最近做了个需求,需要调用第三方接口获取数据,在联调时一直失败,代码抛出javax.net.ssl.SSLHandshakeException异常, 具体错误信息如下所示: javax. ...
- 小白必看的cmd简单代码!(图片看不到的可复制 粘贴到Typroa进行观看)
打卡cmd的方法 直接window加r 输入cmd 在下方菜单 找到window标志,打开 输入命令提示符 更高级的cmd权限使用:右键命令提示符,点击"以管理员身份运行" 一些简 ...