Streamlit入门:10分钟搭建数据可视化界面
一、Streamlit简介
Streamlit是一个用Python构建数据应用的开源框架,它能让我们快速创建漂亮的数据可视化界面。本文将通过一个简单的示例,展示如何使用Streamlit构建数据可视化应用。
二、环境准备
2.1 安装依赖
pip install streamlit pandas plotly numpy
2.2 创建项目
mkdir streamlit_demo
cd streamlit_demo
touch demo_app.py
三、代码实现
3.1 完整代码
import streamlit as st
import pandas as pd
import plotly.express as px
import numpy as np
# 页面配置
st.set_page_config(
page_title="Streamlit Demo",
page_icon="",
layout="wide"
)
# 标题
st.title(" Streamlit数据可视化示例")
st.markdown("---")
# 侧边栏
with st.sidebar:
st.header(" 配置面板")
# 数据生成配置
num_points = st.slider("数据点数量", 10, 100, 50)
chart_type = st.selectbox(
"图表类型",
["折线图", "柱状图", "散点图", "饼图"]
)
# 生成示例数据
df = pd.DataFrame({
'日期': pd.date_range('2024-01-01', periods=num_points),
'数值': np.random.randn(num_points).cumsum(),
'类别': np.random.choice(['A', 'B', 'C'], num_points)
})
# 主要内容区
col1, col2 = st.columns(2)
with col1:
st.subheader(" 数据预览")
st.dataframe(df, use_container_width=True)
with col2:
st.subheader(" 可视化展示")
if chart_type == "折线图":
fig = px.line(df, x='日期', y='数值', color='类别')
elif chart_type == "柱状图":
fig = px.bar(df, x='日期', y='数值', color='类别')
elif chart_type == "散点图":
fig = px.scatter(df, x='日期', y='数值', color='类别')
else: # 饼图
fig = px.pie(df, values='数值', names='类别')
st.plotly_chart(fig, use_container_width=True)
# 统计信息
st.markdown("---")
st.subheader(" 统计信息")
col1, col2, col3 = st.columns(3)
with col1:
st.metric("数据点数量", num_points)
with col2:
st.metric("平均值", f"{df['数值'].mean():.2f}")
with col3:
st.metric("标准差", f"{df['数值'].std():.2f}")
# 交互式数据筛选
st.markdown("---")
st.subheader(" 数据筛选")
selected_categories = st.multiselect(
"选择类别",
df['类别'].unique(),
default=df['类别'].unique()
)
filtered_df = df[df['类别'].isin(selected_categories)]
st.dataframe(filtered_df, use_container_width=True)
# 下载按钮
st.markdown("---")
st.download_button(
" 下载数据",
filtered_df.to_csv(index=False).encode('utf-8'),
"data.csv",
"text/csv",
key='download-csv'
)
3.2 代码说明
- 页面配置
st.set_page_config(
page_title="Streamlit Demo",
page_icon="",
layout="wide"
)
设置页面标题、图标和布局方式。
- 侧边栏配置
with st.sidebar:
st.header(" 配置面板")
num_points = st.slider("数据点数量", 10, 100, 50)
chart_type = st.selectbox(
"图表类型",
["折线图", "柱状图", "散点图", "饼图"]
)
创建侧边栏控制面板,包含数据点数量滑块和图表类型选择器。
- 数据展示
col1, col2 = st.columns(2)
with col1:
st.dataframe(df, use_container_width=True)
with col2:
st.plotly_chart(fig, use_container_width=True)
使用列布局展示数据表格和可视化图表。
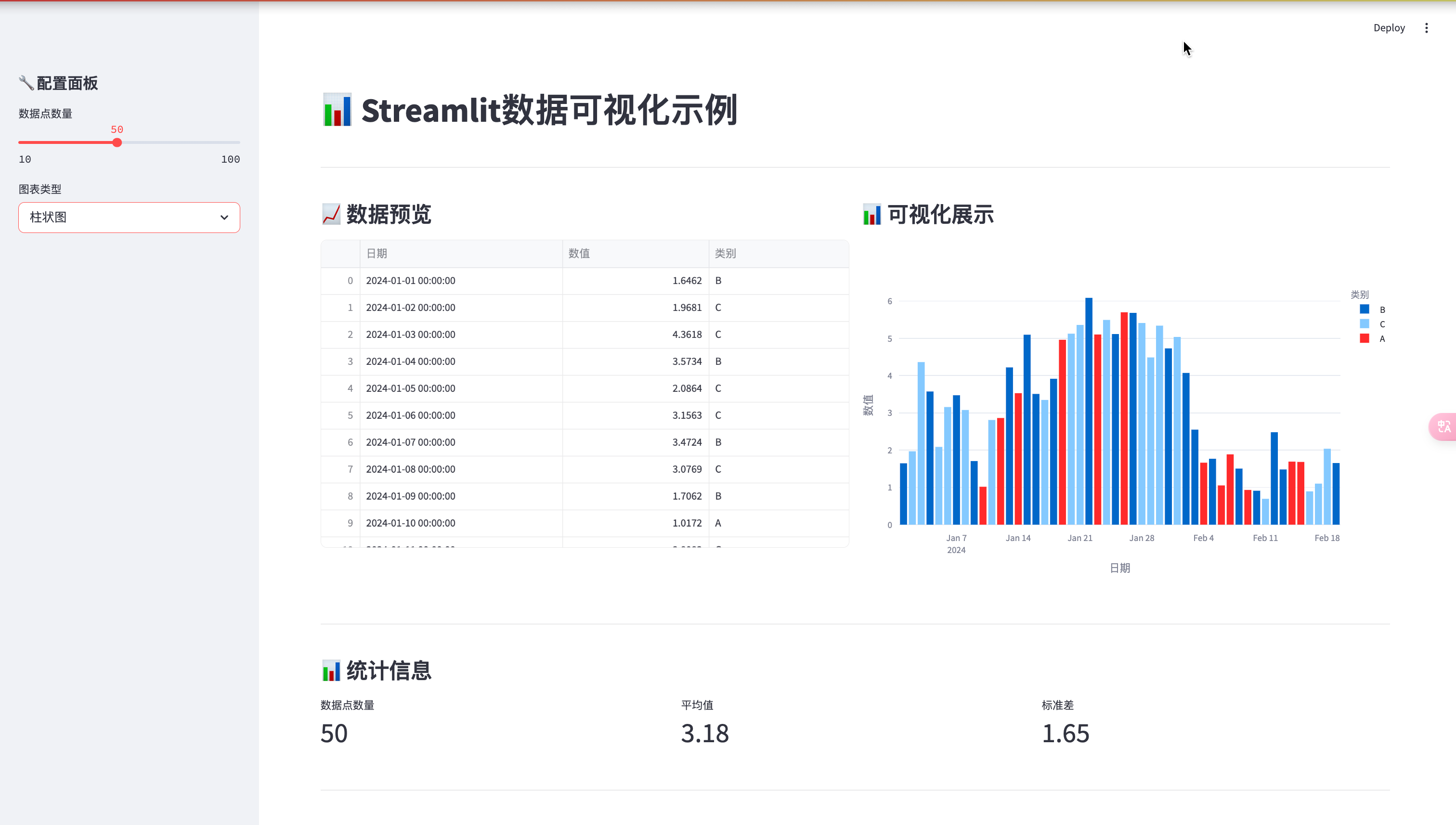
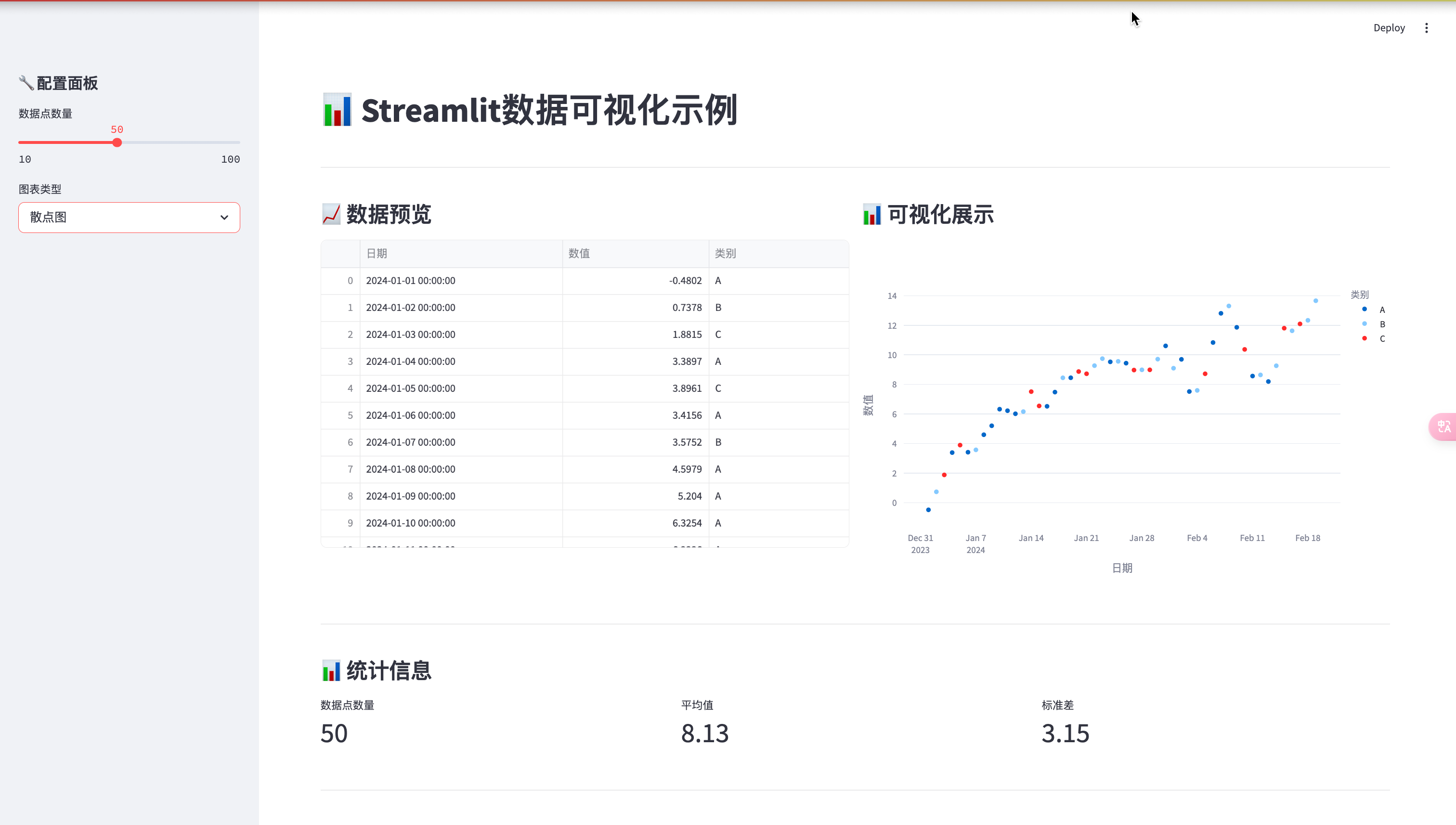
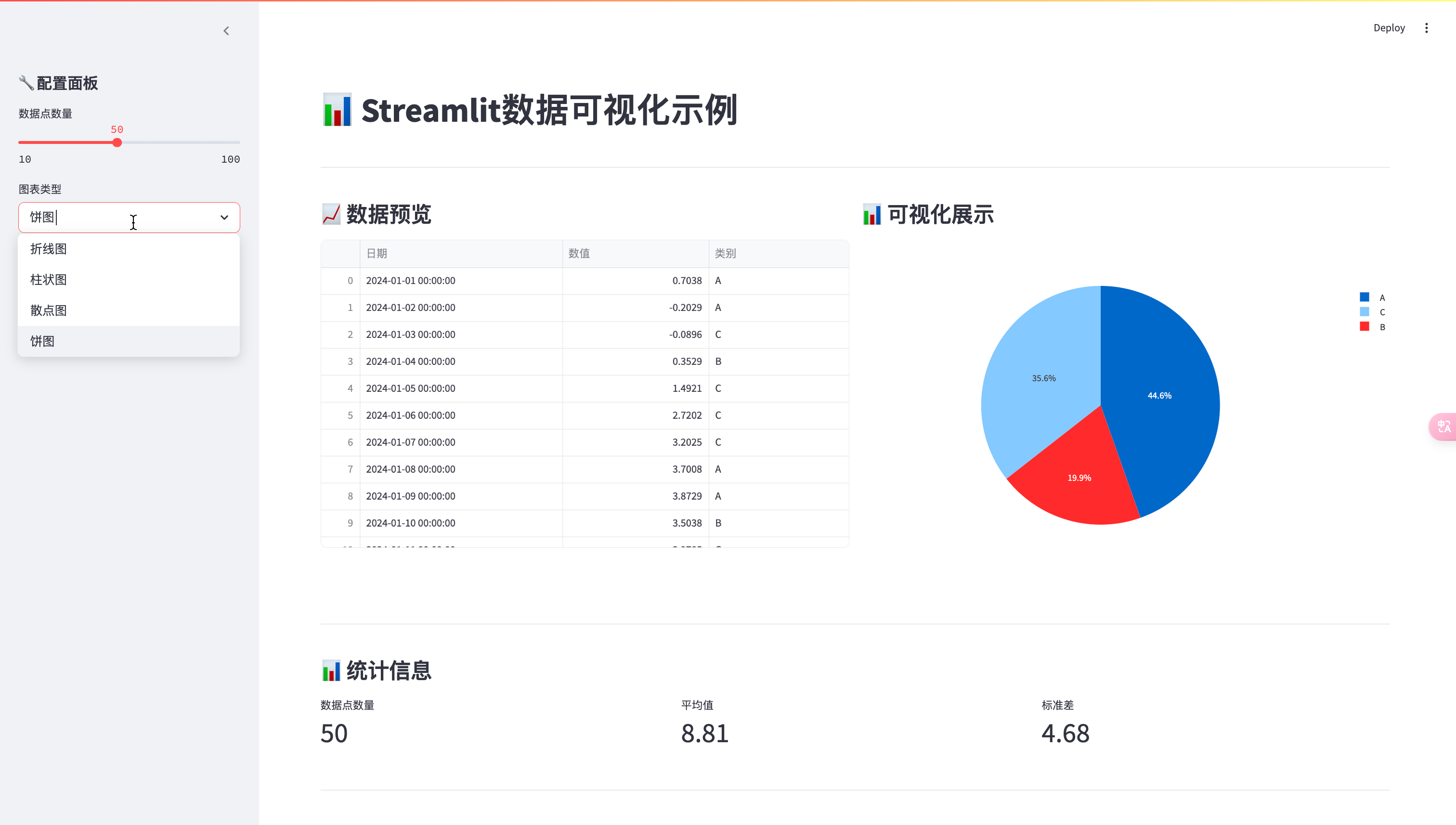
四、界面展示
4.1 主界面

主界面采用双列布局,左侧显示数据表格,右侧显示可视化图表。
4.2 侧边栏

侧边栏包含配置选项,可以调整数据量和图表类型。
4.3 数据筛选

支持多选筛选数据类别,筛选结果实时更新。
4.4 统计信息

使用指标卡片展示关键统计信息。
五、运行应用
streamlit run demo_app.py
运行后,应用将在浏览器中自动打开,默认地址为:http://localhost:8501
六、功能特点
交互式配置
- 可调整数据点数量
- 支持多种图表类型
- 实时数据筛选
数据可视化
- 支持折线图、柱状图、散点图、饼图
- 自适应布局
- 交互式图表
数据操作
- 数据预览
- 统计信息展示
- CSV格式导出
七、优化建议
性能优化
- 使用@st.cache_data缓存数据
- 限制数据显示数量
- 优化图表渲染
界面优化
- 添加加载动画
- 优化错误提示
- 改善移动端适配
八、总结
通过这个简单的示例,我们展示了Streamlit的基本用法:
- 页面布局和组件使用
- 数据处理和可视化
- 交互功能实现
Streamlit的优势在于:
- 快速开发
- 简单易用
- 丰富的组件
- 良好的可扩展性
参考资料
最终效果
Streamlit入门:10分钟搭建数据可视化界面的更多相关文章
- 10分钟搭建一个小型网页(python django)(hello world!)
10分钟搭建一个小型网页(python django)(hello world!) 1.安装django pip install django 安装成功后,在Scripts目录下存在django-ad ...
- DB2输出每隔10分钟的数据
一.输出1-100的数据 此处参考 https://bbs.csdn.net/topics/390516027 with t(id) as ( as id from sysibm.sysdummy1 ...
- Streamlit:快速数据可视化界面工具
目录 Streamlit简介 Streamlit使用指南 常用命令 显示文本 显示数据 显示图表 显示媒体 交互组件 侧边栏 缓存机制 Streamlit使用Hack Streamlit的替代品 相关 ...
- python scrapy 入门,10分钟完成一个爬虫
在TensorFlow热起来之前,很多人学习python的原因是因为想写爬虫.的确,有着丰富第三方库的python很适合干这种工作. Scrapy是一个易学易用的爬虫框架,尽管因为互联网多变的复杂性仍 ...
- 10分钟搭建 App 主流框架
搭建主流框架界面 0.达成效果 我们玩iPhone应用的时候,有没发现大部分的应用都是上图差不多的结构,下面的TabBar控制器可以切换子控制器,上面又有Navigation导航条 我们本文主要是搭建 ...
- 利用django框架,手把手教你搭建数据可视化系统(一)
如何使用django去构建数据可视化的 web,可视化的结果可以呈现在web上. 使用django的MTV模型搭建网站 基础铺垫-MTV模型 Created with Raphaël 2.1.0Req ...
- Docker搭建Portainer可视化界面
为了解决上回说到的问题,在网上找了找 找到了一个 非常有好的可视化界面管理工具. Portainer 是什么东西 (开源轻量级) Portainer是Docker的图形化管理工具,提供状态显示面板.应 ...
- pandas入门10分钟——serries其实就是data frame的一列数据
10 Minutes to pandas This is a short introduction to pandas, geared mainly for new users. You can se ...
- TTS-零基础入门-10分钟教你做一个语音功能
在本片博客正式開始之前,大家先跟我做一个简单的好玩的 小语音. 新建一个文本文档,然后再文档里输入这样 一句话 CreateObject("SAPI.SpVoice").Spea ...
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
随机推荐
- ABC245Ex题解
前言 \(2024.11.21\) 联考第三题,本人由于太菜没有推出 \(m=p^x\) 的性质遂部分分跑路,作文以记之. 简要题意 对于一个长度为 \(n\),值域为 \([0,m-1]\) 的序列 ...
- 花3分钟来了解一下Vue3中的插槽到底是什么玩意
前言 插槽看着是一个比较神秘的东西,特别是作用域插槽还能让我们在父组件里面直接访问子组件里面的数据,这让插槽变得更加神秘了.其实Vue3的插槽远比你想象的简单,这篇文章我们来揭开插槽的神秘面纱. 欧阳 ...
- Selenium KPI接口- 鼠标案例
鼠标操作 实现功能:百度页面->移动到'设置'按钮->右键点击/鼠标双击/鼠标拖拽到元素松开. 首先导入ActionChains方法 使用格式:ActionChains(driver).操 ...
- [Qt 基础-01] QPushButton
QPushButton 简介 QPushButton是一个很常用的一个按钮控件,主要用于创建一个可按压的按键.它显示了一 个文本和一个图标.另外,你也可以在创建时,指定一个快捷键. 基本用法 1. 创 ...
- ssh: connect to host github.com port 22: Connection timed out----git问题记录
今天使用git命令提交代码,git add .,git commit -m '',git push 一顿操作猛如虎啊,嘴角一勾,邪魅一笑像往常一样期待着等着进度条100%,然后直接出现ssh: con ...
- 如何删除Docker Swarm中的Node
好吧,我又回来了...断了那么久主要是因为懒...现在有空会更新一些docker相关的知识.本文主要是总结下在工作中需要管理Docker Swarm中的Node遇到的问题:如何删除一个Swarm中的N ...
- BUUCTF---rot
题目 破解下面的密文: 83 89 78 84 45 86 96 45 115 121 110 116 136 132 132 132 108 128 117 118 134 110 123 111 ...
- 【硬件】认识和选购4K画质的显卡
2.6 认识和选购4K画质的显卡 显卡一般是一块独立的电路板,插在主板上接收由主机发出的控制显示系统工作的指令和显示内容的数字信号,然后通过输出模拟(或数字)信号控制显示器显示各种字符和图形,它和显示 ...
- study Rust-7【使用结构体的demo】
fn main() { let width1 = 30; let height1 = 50; println!( "The area of the rectangle is {} squar ...
- SSL测试证书
1. tomcat 1.1 生成 keytool -genkey -alias tomcat -keyalg RSA -keystore tomcat.keystore -validity 365 过 ...