使用minio + iceberg-rest + amoro+ + trino搭建iceberg数据湖架构
该架构(MinIO + Iceberg REST Catalog + Amoro + Trino)的设计融合了现代数据湖的核心需求,旨在实现存储解耦、计算灵活、管理自动化及高性能查询的综合目标。
flink /spark 写入数据
↓ DolphinScheduler(调度)
MinIO 统一存储多地数据 → Iceberg REST 统一元数据 → Trino 跨云查询
↑ 接管
Amoro 自动优化
一、核心设计理念
- 存储与计算分离
- MinIO 作为底层对象存储,提供高扩展、低成本的云原生存储能力,兼容 S3 API 简化多引擎接入。
- 统一元数据治理
- Iceberg REST Catalog 替代 Hive Metastore,提供标准化 RESTful 接口管理表元数据(如分区、Schema、快照)。
- 优势:解耦元数据服务,避免单点故障,支持多引擎并发读写(Flink/Spark/Trino)。
- 自动化湖仓管理
- Amoro 填补了 Iceberg 原生能力的空白,提供:
- 小文件自动合并(通过 Flink 作业优化存储)
- 多引擎协调(保证 Trino、Flink、Spark 的事务一致性)
- 表生命周期管理(如分区清理、数据归档)
- 高性能分析查询
- Trino 作为统一 SQL 查询层,支持:
- 秒级响应复杂分析;
- Iceberg 高级特性(时间旅行、增量扫描)
数据写入建议使用spark、flink等引擎直接通过iceberg rest catalog写入minio存储。可实现批流、实时流。
上一篇文章中是 trino直接访问amoro,amoro存在单一节点存在性能瓶颈,amoro还在孵化阶段,为了解决上面的问题,因此引入iceberg rest catalog 元数据管理,让amoro接管外部 External Catalog,trino直接配置访问 rest catalog。
另外,大家会问为什么数据查询分析不适用doris? 其实是可以的。考虑一点:doris数仓分析访问iceberg时,它有一个10分钟的元数据同步时间,会导致实时写入iceberg的数据,不能第一时间查询到。因此引入doris 会导致只能达到分钟级的实时数仓。
二、部署流程
以下是使用docker-compose搭建,可用于日常开发环境。
确保已安装Docker 27.0.3 和Docker Compose。
把下面的yaml保存到docker-compose.yml的文件中:
version: "3"
services:
minio:
image: minio/minio
container_name: minio
networks:
demo-iceberg:
aliases:
- warehouse.minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
ports:
- 9001:9001
- 9000:9000
command: [ "server", "/data", "--console-address", ":9001" ]
rest:
image: tabulario/iceberg-rest
container_name: iceberg-rest
networks:
demo-iceberg:
aliases:
- warehouse.rest
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
amoro:
image: apache/amoro
container_name: amoro
ports:
- 8081:8081
- 1630:1630
- 1260:1260
environment:
- JVM_XMS=1024
networks:
demo-iceberg:
volumes:
- ./amoro:/tmp/warehouse
command: ["/entrypoint.sh", "ams"]
tty: true
stdin_open: true
trino:
image: trinodb/trino:419
container_name: trino
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
volumes:
- ./example.properties:/etc/trino/catalog/example.properties
networks:
demo-iceberg:
aliases:
- warehouse.trino
ports:
- 8080:8080
networks:
demo-iceberg:
ipam:
driver: default
iceberg rest 镜像使用 tabulario/iceberg-rest。不要去使用iceberg官网上的 apache/iceberg-rest-fixture,会报错。
接下来,在docker-compose.yml所在的目录下创建example.properties文件:
connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://<IP地址>:8181
fs.native-s3.enabled=true
s3.endpoint=http://<IP地址>:9000
s3.region=us-east-1
s3.aws-access-key=admin
s3.aws-secret-key=password
最后一步骤:使用以下命令启动docker容器:
docker-compose up minio rest amoro
配置
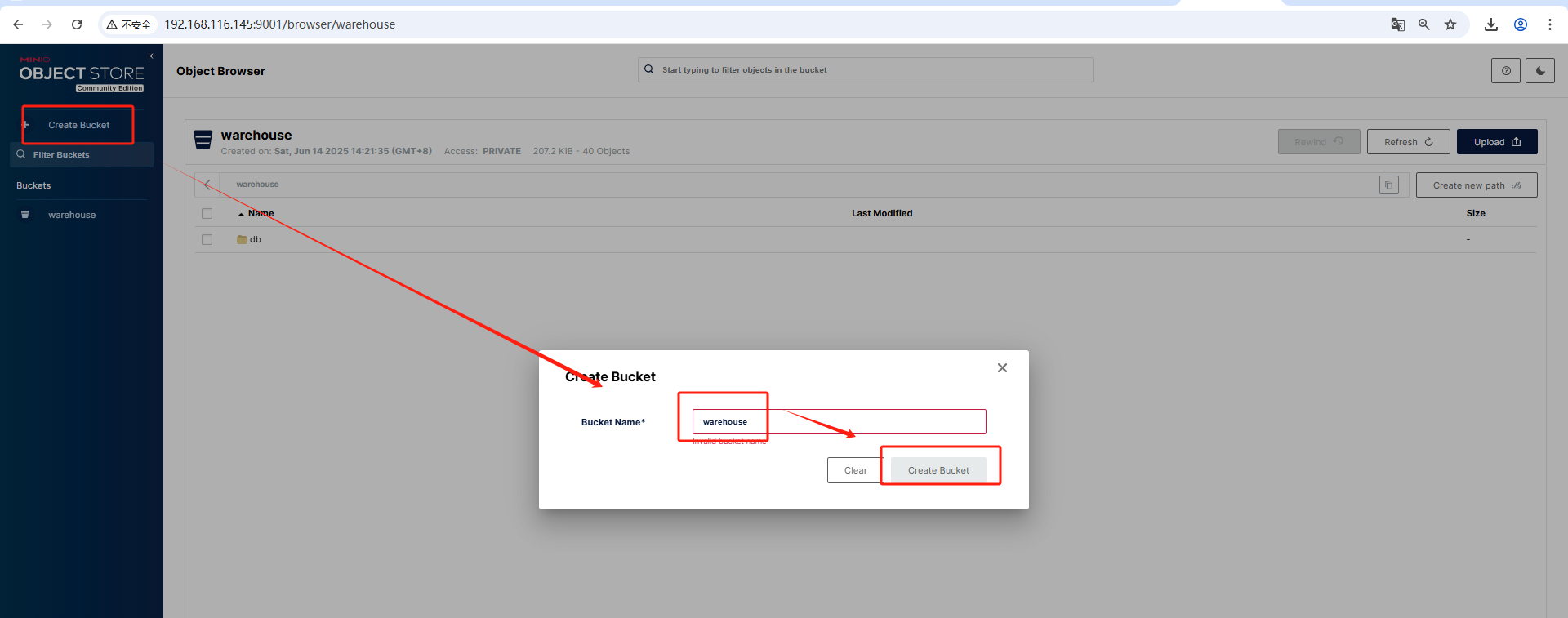
minio 创建 bucket
打开http://localhost:9000在浏览器中,输入admin/password登录minio界面。
amoro 配置
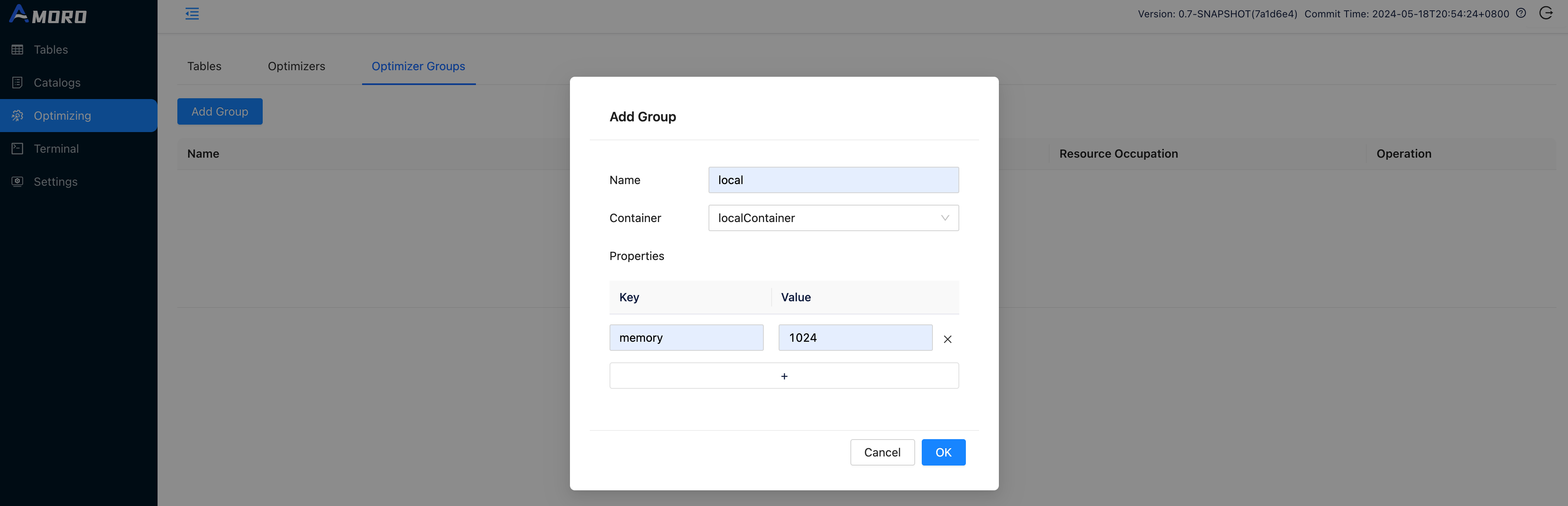
Create optimizer group
Open http://localhost:1630 in a browser, enter admin/admin to log in to the dashboard.
Click on Optimizing in the sidebar, choose Optimizer Groups and click Add Group button to create a new group befre creating catalog
Create catalog
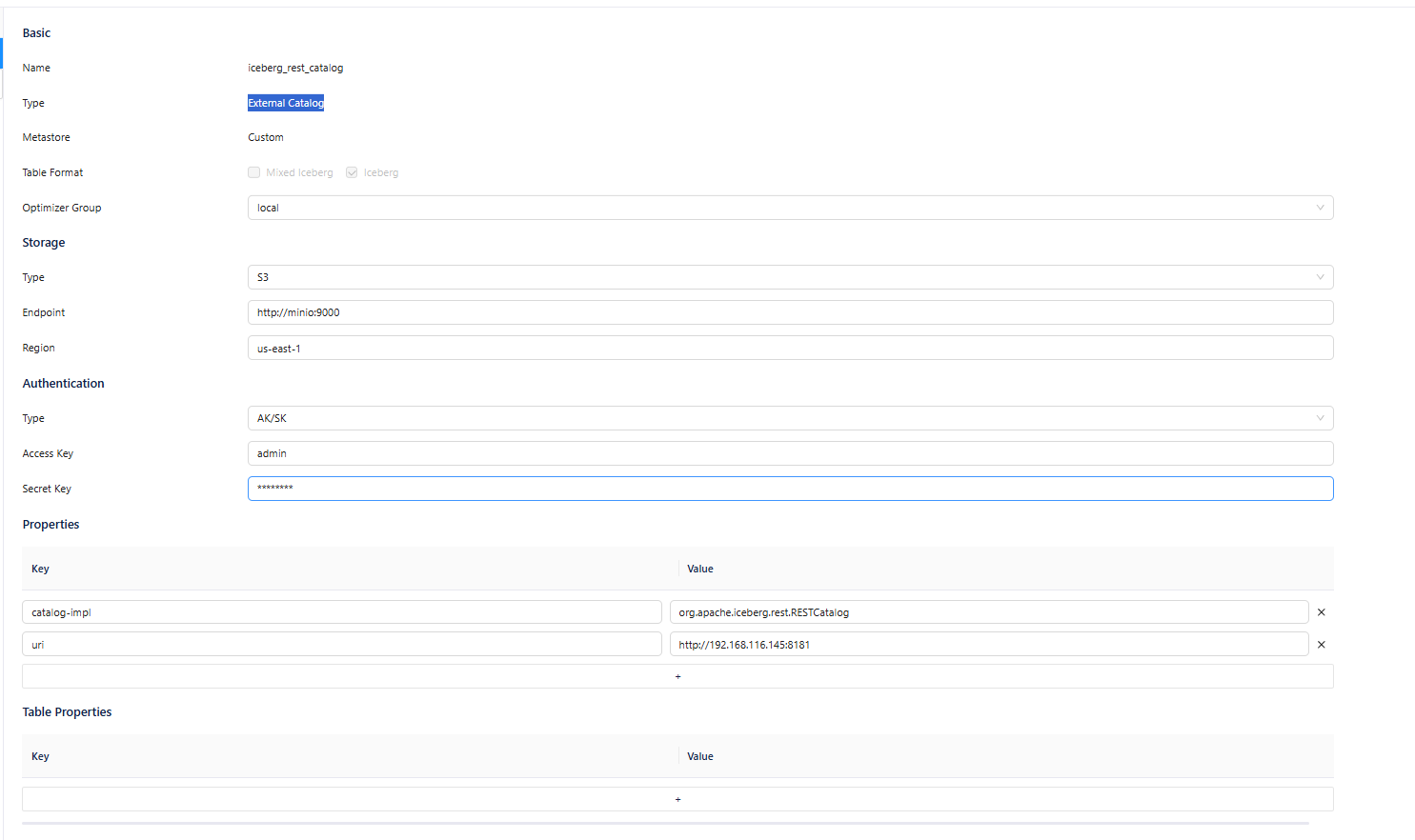
Click on Catalogs in the sidebar, click on the + button under Catalog List to create a test catalog, and name it to demo_catalog:
o use the Iceberg Format, select Type as External Catalog, and choose Metastore as Custom, and choose Iceberg as Table Format.
key catalog-impl in to org.apache.iceberg.rest.RESTCatalog
add key as uri in in to http://<rest ip address>:8181
这一步非常重要,请查看下面的图片填写。
按照上面配置的,修改example.properties文件。然后执行以下命令:
docker-compose up trino
Demo steps
Initialize tables
Click on amoro system Terminal in the sidebar, you can create the test tables here using SQL. Terminal supports executing Spark SQL statements for now.
CREATE DATABASE IF NOT EXISTS db;
CREATE TABLE IF NOT EXISTS db.tb_users (
id INT,
name string,
ts TIMESTAMP
)
PARTITIONED BY (days(ts));
INSERT OVERWRITE db.tb_users VALUES
(1, "eric", timestamp("2022-07-01 12:32:00")),
(2, "frank", timestamp("2022-07-02 09:11:00")),
(3, "lee", timestamp("2022-07-02 10:11:00"));
SELECT * FROM db.tb_users;
Click on the RUN button uppon the SQL editor, and wait for the SQL query to finish executing. You can then see the query results under the SQL editor.
Initialize tables
start up the docker containers with this command:
docker exec -it tirno trino
trino> show catalogs;
Catalog
---------
example
jmx
memory
system
tpcds
tpch
(6 rows)
trino> show schemas in example;
Schema
--------------------
db
information_schema
(2 rows)
trino> show tables in example.db;
Table
-------
tb_users
(1 row)
trino> select * from example.db.tb_users;
id | name | ts
----+-------+--------------------------------
1 | eric | 2022-07-01 12:32:00.000000 UTC
2 | frank | 2022-07-02 09:11:00.000000 UTC
3 | lee | 2022-07-02 10:11:00.000000 UTC
(3 rows)
到此为止,我们的架构就搭建完成。
关键注意事项
- 生产环境建议配置持久化卷和网络隔离
- 服务器要配置 limits.conf、 sysctl.conf。可参考https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002016077
使用minio + iceberg-rest + amoro+ + trino搭建iceberg数据湖架构的更多相关文章
- 知名大厂如何搭建大数据平台&架构
今天我们来看一下淘宝.美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图.通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小 ...
- 使用 Iceberg on Kubernetes 打造新一代云原生数据湖
背景 大数据发展至今,按照 Google 2003年发布的<The Google File System>第一篇论文算起,已走过17个年头.可惜的是 Google 当时并没有开源其技术,& ...
- 均有商业公司支持!2023再看数据湖 hudi iceberg delta2 社区发展现状!
开源数据湖三剑客 Apache hudi.Apache iceberg .Databricks delta 近年来大动作不断. 2021年8月,Apache Iceberg 的创始人 Ryan Blu ...
- 架构师入门:搭建基本的Eureka架构(从项目里抽取)
没有废话,直接上干货,理论部分大家可以看其它资料. 这里是部分关键代码,如果需要全部可运行的代码,请给本人留言. 在后继,还将给出搭建高可用Eureka架构的方式. 1 Eureka的框架图 在Eur ...
- 【从零开始搭建自己的.NET Core Api框架】(二)搭建项目的整体架构
系列目录 一. 创建项目并集成swagger 1.1 创建 1.2 完善 二. 搭建项目整体架构 三. 集成轻量级ORM框架——SqlSugar 3.1 搭建环境 3.2 实战篇:利用SqlSuga ...
- 如何搭建高可用redis架构?
如何搭建高可用redis架构? 温国兵 架构师小秘圈 昨天 作者:温国兵,曾任职于酷狗音乐,现为三七互娱 DBA.目前主要关注领域:数据库自动化运维.高可用架构设计.数据库安全.海量数据解决方案.以及 ...
- ClickHouse之集群搭建以及数据复制
前面的文章简单的介绍了ClickHouse,以及也进行了简单的性能测试.本次说说集群的搭建以及数据复制,如果复制数据需要zookeeper配合. 环境: 1. 3台机器,我这里是3台虚拟机.都安装了c ...
- ubuntu 下 mysql数据库的搭建 及 数据迁移
1.mysql的安装 我是使用apt-get直接安装的 :sudo apt-get install mysql-server sudo apt-get install mysql-client 2.配 ...
- .NET完全手动搭建三层B/S架构
简介:三层架构(3-tier application) 通常意义上的三层架构就是将整个业务应用划分为:表现层(WebUI).业务逻辑层(BusinessLogicLayer).数据访问层(DataAc ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
随机推荐
- Go语言实现1024终端游戏-不到400行代码
先放源码地址,喜欢看源码翻源码,喜欢看文章的继续继续看文章 https://github.com/taadis/go1024 - go1024 使用 go 语言实现的 1024 终端游戏,不到400行 ...
- C#多线程编程(二)线程池与TPL
一.直接使用线程的问题 每次都要创建Thread对象,并向操作系统申请创建一个线程,这是需要耗费CPU时间和内存资源的. 无法直接获取线程函数返回值 无法直接捕捉线程函数内发生的异常 使用线程池可以解 ...
- Golang高性能引擎:ZKmall开源商城支撑百万级日活交易流畅运行
在电商业务高并发.低延迟的严苛场景下,技术栈的选择直接决定系统上限.ZKmall开源商城基于Golang技术生态,以协程级并发.毫秒级响应为核心优势,为百万级日活电商平台提供高性能解决方案.本文从架构 ...
- 详细介绍MessageQueueSelector
一.MessageQueueSelector 详解 MessageQueueSelector 是 RocketMQ 提供的一个接口,用于自定义消息发送时的队列选择策略. 通过实现该接口, 开发者可以控 ...
- 一个清除数组的方法在 Kotlin、Java、C#和Nim上的性能测试
起因 我的一个项目使用 Kotlin 编写,他是一个多维数据库应用程序,所以会非常频繁的操作 int 数组,其中有段程序就需要进行 几亿次的数组清除动作,类似这样的代码: Arrays.fill(ta ...
- 牛逼,这款开源聊天应用竟能一键召唤多个AI助手,跨平台通话神器!
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 JiwuChat是一款基于Tauri2和Nuxt3构建的轻量化多平台即时通讯工具,仅约8MB ...
- Web前端入门第 47 问:CSS @media 媒体查询不要只会视口宽度适配
@media 媒体查询的出现解决了什么问题? 曾经,一个网页要兼容移动端和 PC 端,前端的代码复杂度嗖嗖嗖的飙升,需要使用多套代码对各种屏幕尺寸做适配. @media 的出现解决了 CSS 中无法适 ...
- 浅谈鸿蒙跨平台开发框架ArkUI-X
之前写过使用uniapp的跨平台开发鸿蒙项目,今天分享一下开发体验更友好的跨平台开发框架ArkUI-X. ArkUI-X看起来像是鸿蒙官方的框架,在DevEco中就可以安装和使用,而且会ArkUI就可 ...
- TVM VLOG打印
TVM 提供了详细日志记录功能,允许提交跟踪级别的调试消息,而不会影响生产中 TVM 的二进制大小或运行时.你可以在你的代码中使用 VLOG 如下: void Foo(const std::strin ...
- codeup之进制转换(大数的进制转换
题目描述 将一个长度最多为30位数字的十进制非负整数转换为二进制数输出. 输入 多组数据,每行为一个长度不超过30位的十进制非负整数. (注意是10进制数字的个数可能有30个,而非30bits的整数) ...