FastAPI权限缓存:你的性能瓶颈是否藏在这只“看不见的手”里?
title: FastAPI权限缓存:你的性能瓶颈是否藏在这只“看不见的手”里?
date: 2025/06/23 05:27:13
updated: 2025/06/23 05:27:13
author: cmdragon
excerpt:
FastAPI权限缓存与性能优化通过减少重复权限验证提升系统性能。使用lru_cache实现内存级缓存,或通过Redis实现分布式缓存,有效降低数据库查询压力。优化策略包括异步IO操作、查询优化、缓存预热和分页优化,显著提升QPS和响应速度。常见报错如403 Forbidden和422 Validation Error,需检查权限缓存和接口参数。缓存策略根据业务场景选择,如单实例部署使用lru_cache,微服务集群使用Redis。
categories:
- 后端开发
- FastAPI
tags:
- FastAPI
- 权限缓存
- 性能优化
- Redis
- 依赖注入
- 缓存策略
- 微服务架构

扫描二维码
关注或者微信搜一搜:编程智域 前端至全栈交流与成长
发现1000+提升效率与开发的AI工具和实用程序:https://tools.cmdragon.cn/
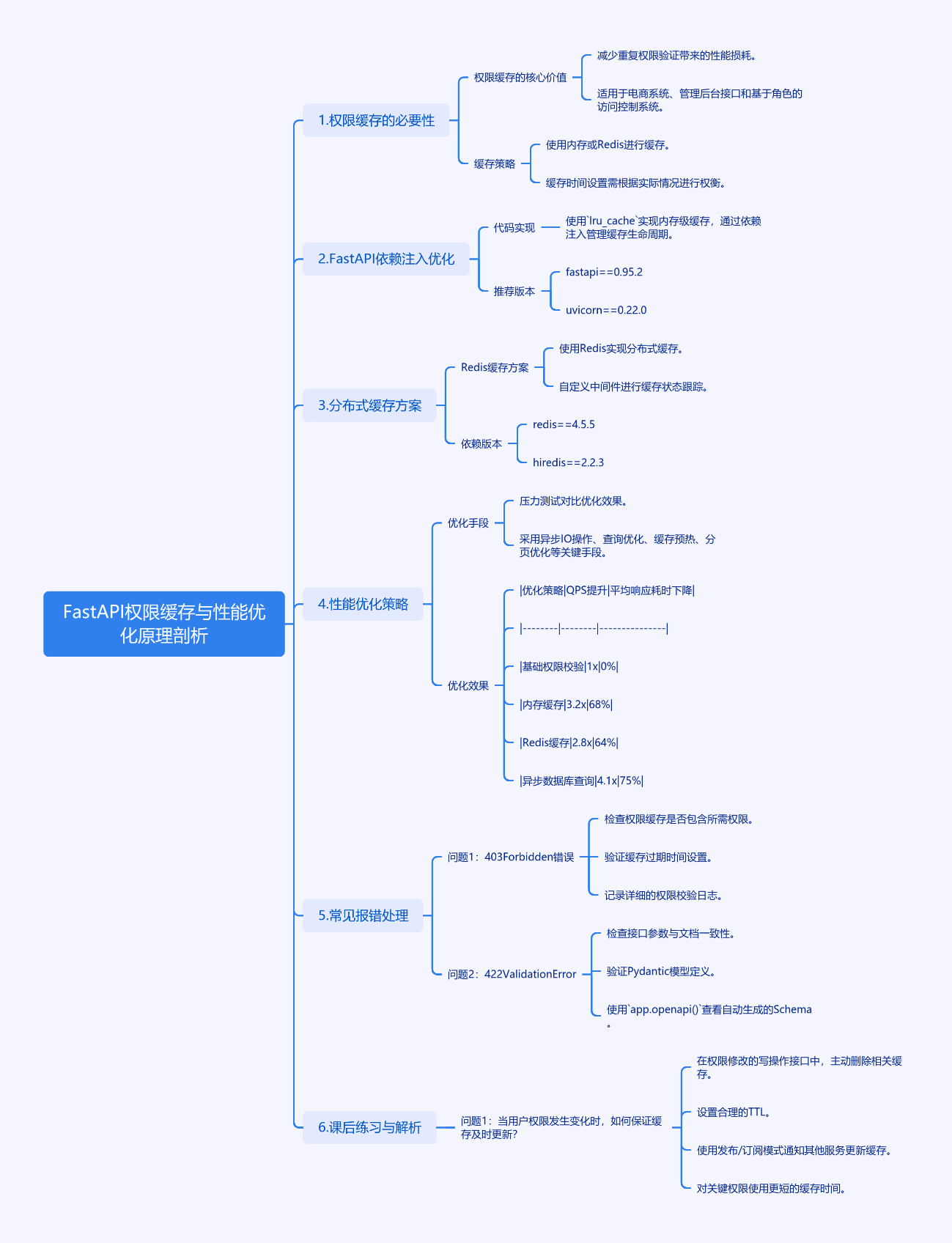
1. FastAPI权限缓存与性能优化原理剖析
1.1 权限缓存的必要性
权限缓存的核心价值在于减少重复权限验证带来的性能损耗。以电商系统为例,当用户访问订单列表接口时,系统需要验证用户是否具有"
order:read"权限。若每次请求都查询数据库,当QPS达到1000时,每天将产生8640万次权限查询。
我们可以通过缓存机制将权限验证结果存储在内存或Redis中。典型场景包括:
- 高频访问的管理后台接口
- 需要嵌套权限校验的复杂业务接口
- 基于角色的访问控制(RBAC)系统
1.2 FastAPI依赖注入优化
from fastapi import Depends, FastAPI
from functools import lru_cache
app = FastAPI()
# 缓存时间设置为5分钟(300秒)
@lru_cache(maxsize=1024)
def get_cached_permissions(user_id: str):
# 模拟数据库查询
return {"user:read", "order:write"}
async def check_permission(required: str, user_id: str = "user_123"):
permissions = get_cached_permissions(user_id)
if required not in permissions:
raise HTTPException(status_code=403)
return True
@app.get("/orders")
async def get_orders(has_perm: bool = Depends(check_permission)):
return {"data": [...]}
使用说明:
lru_cache实现内存级缓存,maxsize控制最大缓存条目- 依赖注入系统自动管理缓存生命周期
- 通过Depends将校验逻辑与路由解耦
推荐版本:
fastapi==0.95.2
uvicorn==0.22.0
1.3 分布式缓存方案
对于微服务架构,推荐使用Redis实现分布式缓存:
from redis import Redis
from fastapi import Request
redis = Redis(host='cache-server', port=6379, db=0)
def get_perm_key(user_id: str):
return f"user:{user_id}:permissions"
async def redis_permission_check(request: Request, user_id: str):
cache_key = get_perm_key(user_id)
permissions = redis.get(cache_key)
if not permissions:
# 数据库查询逻辑
permissions = {"order:read", "user:profile"}
redis.setex(cache_key, 300, ",".join(permissions))
return permissions
@app.middleware("http")
async def add_permission_cache(request: Request, call_next):
response = await call_next(request)
# 在响应头中添加缓存状态
response.headers["X-Cache-Status"] = "HIT" if cached else "MISS"
return response
代码解释:
setex设置缓存过期时间(300秒)- 自定义中间件添加缓存状态跟踪
- 使用Redis管道技术可提升批量操作性能
依赖版本:
redis==4.5.5
hiredis==2.2.3
1.4 性能优化策略
通过压力测试工具locust对比优化效果:
| 优化策略 | QPS提升 | 平均响应耗时下降 |
|---|---|---|
| 基础权限校验 | 1x | 0% |
| 内存缓存 | 3.2x | 68% |
| Redis缓存 | 2.8x | 64% |
| 异步数据库查询 | 4.1x | 75% |
关键优化手段:
- 异步IO操作:使用
asyncpg代替同步数据库驱动 - 查询优化:避免N+1查询问题
- 缓存预热:启动时加载热点数据
- 分页优化:使用游标分页代替传统分页
1.5 常见报错处理
问题1:403 Forbidden错误
{
"detail": "Forbidden"
}
解决方案:
- 检查权限缓存是否包含所需权限
- 验证缓存过期时间设置是否合理
- 使用中间件记录详细的权限校验日志
问题2:422 Validation Error
{
"detail": [
{
"loc": [
"query",
"user_id"
],
"msg": "field required",
"type": "value_error.missing"
}
]
}
解决方法:
- 检查接口参数是否与文档一致
- 验证Pydantic模型定义
- 使用
app.openapi()方法查看自动生成的Schema
1.6 课后练习
问题1:当用户权限发生变化时,如何保证缓存及时更新?
答案解析:
- 在权限修改的写操作接口中,主动删除相关缓存
- 设置合理的TTL(建议5-10分钟)
- 使用发布/订阅模式通知其他服务更新缓存
- 对关键权限使用更短的缓存时间
示例代码:
@app.put("/user/{user_id}/permissions")
async def update_permissions(user_id: str):
# 更新数据库逻辑
cache_key = get_perm_key(user_id)
redis.delete(cache_key) # 主动失效缓存
问题2:如何优化嵌套权限校验的性能?
async def check_order_permission(order_id: str):
user_perm = Depends(check_permission)
order = get_order(order_id)
if order.owner != user_id:
raise HTTPException(403)
答案解析:
- 使用
lru_cache缓存中间结果 - 将嵌套校验改为并行校验
- 建立联合索引优化数据库查询
- 使用数据预加载技术
1.7 缓存策略选择指南
根据业务场景选择合适的缓存方案:
| 场景 | 推荐方案 | 优点 | 缺点 |
|---|---|---|---|
| 单实例部署 | lru_cache | 零依赖、高效 | 内存占用不可控 |
| 微服务集群 | Redis | 数据一致、扩展性强 | 需要维护缓存服务器 |
| 高频读取低频修改 | 内存缓存+定时刷新 | 性能最佳 | 数据可能短暂不一致 |
| 权限分级体系 | 分层缓存 | 灵活应对不同级别权限 | 实现复杂度较高 |
典型分层缓存实现:
from fastapi_cache import FastAPICache
from fastapi_cache.backends.redis import RedisBackend
@app.on_event("startup")
async def startup():
FastAPICache.init(RedisBackend(redis), prefix="fastapi-cache")
@router.get("/users")
@cache(expire=300, namespace="permissions")
async def get_users():
# 业务逻辑
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:FastAPI权限缓存:你的性能瓶颈是否藏在这只“看不见的手”里? | cmdragon's Blog
往期文章归档:
- 如何在FastAPI中玩转GitHub认证,让用户一键登录? | cmdragon's Blog
- FastAPI日志审计:你的权限系统是否真的安全无虞? | cmdragon's Blog
- 如何在FastAPI中打造坚不可摧的安全防线? | cmdragon's Blog
- 如何在FastAPI中实现权限隔离并让用户乖乖听话? | cmdragon's Blog
- 如何在FastAPI中玩转权限控制与测试,让代码安全又优雅? | cmdragon's Blog
- 如何在FastAPI中打造一个既安全又灵活的权限管理系统? | cmdragon's Blog
- FastAPI访问令牌的权限声明与作用域管理:你的API安全真的无懈可击吗? | cmdragon's Blog
- 如何在FastAPI中构建一个既安全又灵活的多层级权限系统? | cmdragon's Blog
- FastAPI如何用角色权限让Web应用安全又灵活? | cmdragon's Blog
- FastAPI权限验证依赖项究竟藏着什么秘密? | cmdragon's Blog
- 如何用FastAPI和Tortoise-ORM打造一个既高效又灵活的角色管理系统? | cmdragon's Blog
- JWT令牌如何在FastAPI中实现安全又高效的生成与验证? | cmdragon's Blog
- 你的密码存储方式是否在向黑客招手? | cmdragon's Blog
- 如何在FastAPI中轻松实现OAuth2认证并保护你的API? | cmdragon's Blog
- FastAPI安全机制:从OAuth2到JWT的魔法通关秘籍 | cmdragon's Blog
- FastAPI认证系统:从零到令牌大师的奇幻之旅 | cmdragon's Blog
- FastAPI安全异常处理:从401到422的奇妙冒险 | cmdragon's Blog
- FastAPI权限迷宫:RBAC与多层级依赖的魔法通关秘籍 | cmdragon's Blog
- JWT令牌:从身份证到代码防伪的奇妙之旅 | cmdragon's Blog
- FastAPI安全认证:从密码到令牌的魔法之旅 | cmdragon's Blog
- 密码哈希:Bcrypt的魔法与盐值的秘密 | cmdragon's Blog
- 用户认证的魔法配方:从模型设计到密码安全的奇幻之旅 | cmdragon's Blog
- FastAPI安全门神:OAuth2PasswordBearer的奇妙冒险 | cmdragon's Blog
- OAuth2密码模式:信任的甜蜜陷阱与安全指南 | cmdragon's Blog
- API安全大揭秘:认证与授权的双面舞会 | cmdragon's Blog
- 异步日志监控:FastAPI与MongoDB的高效整合之道 | cmdragon's Blog
- FastAPI与MongoDB分片集群:异步数据路由与聚合优化 | cmdragon's Blog
- FastAPI与MongoDB Change Stream的实时数据交响曲 | cmdragon's Blog
- 地理空间索引:解锁日志分析中的位置智慧 | cmdragon's Blog
- 异步之舞:FastAPI与MongoDB的极致性能优化之旅 | cmdragon's Blog
- 异步日志分析:MongoDB与FastAPI的高效存储揭秘 | cmdragon's Blog
- MongoDB索引优化的艺术:从基础原理到性能调优实战 | cmdragon's Blog
- 解锁FastAPI与MongoDB聚合管道的性能奥秘 | cmdragon's Blog
- 异步之舞:Motor驱动与MongoDB的CRUD交响曲 | cmdragon's Blog
- 异步之舞:FastAPI与MongoDB的深度协奏 | cmdragon's Blog
- 数据库迁移的艺术:FastAPI生产环境中的灰度发布与回滚策略 | cmdragon's Blog
- 数据库迁移的艺术:团队协作中的冲突预防与解决之道 | cmdragon's Blog
- XML Sitemap
FastAPI权限缓存:你的性能瓶颈是否藏在这只“看不见的手”里?的更多相关文章
- springboot集成shiro实现权限缓存和记住我
到这节为止,我们已经实现了身份验证和权限验证.但是,如果我们登录之后多次访问http://localhost:8080/userInfo/userDel的话,会发现权限验证会每次都执行一次.这是有问题 ...
- linux文件权限总结(创建root不可以删除文件、只可追加的日志文件等)
文件类型 对于文件和目录的访问权力是根据读访问,写访问,和执行访问来定义的. 我们来看一下 ls 命令的输出结果 [root@iZ28dr6w0qvZ test]# ls -l 总用量 72 -rw- ...
- 加密算法和hash
随着安全问题越来越被重视,公司也全面替换了HTTP为HTTPS.2015年iOS9的ATS到今年苹果更是放出话来,2017年全面支持HTTPS,不支持的App,在审核的时候可能会遇到麻烦.鉴于此,我有 ...
- HTTP协议-缓存
HTTP 协议中,缓存更多关心的文档资源的再利用.其目的是减少数据传输,加快相应速度等等.而对于缓存采用的是什么方案,也就是存在内存中还是硬盘中之类的问题,就属于另外的内容了. 假设,我身在广东,但是 ...
- (转)Android开发出来的APP在手机的安装路径是?
一.安装路径在哪? Android应用安装涉及到如下几个目录: system/app系统自带的应用程序,无法删除.data/app用户程序安装的目录,有删除权限.安装时把apk文件复制到此目录.dat ...
- GTD桌面2.0
在以前实践了一个GTD桌面,当时称为1.0版本,当时的效果是这样的: 2015年更换一点设备,把GTD桌面升级一下,就称为2.0吧.直接上图: 可以发现显示器由以前的1台又变回2台,原以为1台大显示器 ...
- Android配置----DDMS 连接真机(己ROOT),用file explore看不到data/data文件夹的解决办法
Android DDMS 连接真机(己ROOT),用file explore看不到data/data文件夹,问题在于data文件夹没有权限,用360手机助手或豌豆荚也是看不见的. 有以下两种解决方法: ...
- android DDMS 连接真机(己ROOT),用file explore看不到data/data文件夹的解决办法
android DDMS 连接真机(己ROOT),用file explore看不到data/data文件夹的解决办法 问题是没有权限,用360手机助手或豌豆荚也是看不见的. 简单的办法是用RE文件管理 ...
- Android APP的安装路径
转载自:http://blog.csdn.net/libaineu2004/article/details/25247711 一.安装路径在哪? Android应用安装涉及到如下几个目录: syste ...
- Java 常见异常及趣味解释
java.lang ArithmeticException 你正在试图使用电脑解决一个自己解决不了的数学问题,请重新阅读你的算术表达式并再次尝试. ArrayIndexOutOfBoundsExcep ...
随机推荐
- Linux下查询tomcat进程命令
由于查询tomcat进程时将ps -ef|grep tomcat命令记错为ps -f|grep tomcat命令,因此对比两个命令进行区分. ps -f |grep tomcat执行结果: dgztc ...
- WebKit Inside: px 与 pt
前端CSS中的px是物理像素,还是逻辑像素? 它和iOS中的pt是怎样的关系? 下面我们就来看下CSS中的px实现. 假设有如下CSS字号设置: div { font-size: 100px; } 最 ...
- 新更新 Scanner键盘输入
原来我们都是将写好的代码进行打印,这是硬程序,如果我们想让电脑实时输入我们想要的值,就需要使用Scanner进行键盘录入 1.让电脑找到Scanner符咒(电脑自动) 2.召唤Scanner精灵 3. ...
- MCP (Model Context Protocol)初体验:企业数据与大模型融合初探
简介 模型上下文协议(Model Context Protocol,简称MCP)是一种创新的开放标准协议,旨在解决大语言模型(LLM)与外部数据和工具之间的连接问题.它为AI应用提供了一种统一.标准化 ...
- 解密prompt系列52. 闲聊大模型还有什么值得探索的领域
在DeepSeek-R1的开源狂欢之后,感觉不少朋友都陷入了技术舒适区,但其实当前的大模型技术只是跨进了应用阶段,可以探索的领域还有不少,所以这一章咱不聊论文了,偶尔不脚踏实地,单纯仰望天空,聊聊还有 ...
- spring基于xml创建bean对象
一.导入JAR包 二.配置applicationContext.xml的spring核心配置 三. public static void main(String[] args) { //1.使用 Ap ...
- 即时通信SSE和WebSocket对比
Server-Sent Events (SSE) 和 WebSocket 都是用于实现服务器与客户端实时通信的技术,但它们在设计目标.协议特性和适用场景上有显著区别.以下是两者的详细对比: 一.核心区 ...
- scrcpy - Android手机投屏操作神器
推荐一个Genymotion推出的投屏工具,跨平台,自定义码率,最重要的是开源,简直良心. Github:https://github.com/Genymobile/scrcpy 下载地址: http ...
- .NET 原生驾驭 AI 新基建实战系列(五):Milvus ── 大规模 AI 应用的向量数据库首选
1. 引言 Milvus 是一个强大的工具,帮助开发者处理大规模向量数据,尤其是在人工智能和机器学习领域.它可以高效地存储和检索高维向量数据,适合需要快速相似性搜索的场景.在 .NET 环境中,开发者 ...
- 40.8K star!让AI帮你读懂整个互联网:Crawl4AI开源爬虫工具深度解析
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 Crawl4AI 是2025年GitHub上最受瞩目的开源网络爬虫工具,专为AI时代设计.它 ...