neo4j存储数据-图数据库
1. 简介
本文主要介绍neo4j是如何将图数据保存在磁盘上的,采用的是什么存储方式。分析这种存储方式对进行图查询/遍历的影响。
2. 图数据库简介
生产环境中使用的图数据库主要有2种,分别是带标签的属性图(Labeled Property Graph)和资源描述框架RDF(Resource Description Framework),前者是工业标准,后者是W3C标准。本文主要基于前者进行讨论。
属性图由点(node/vertex)、边(replationship/edge)和属性(property)三者组成。可以为点设置不同标签(label/tag),边也可以分为很多种类型(type/label)。点和边可以有多个属性,属性以kv的方式表示。目前大部分图数据库的边都是带方向的。属性图模型如下图所示: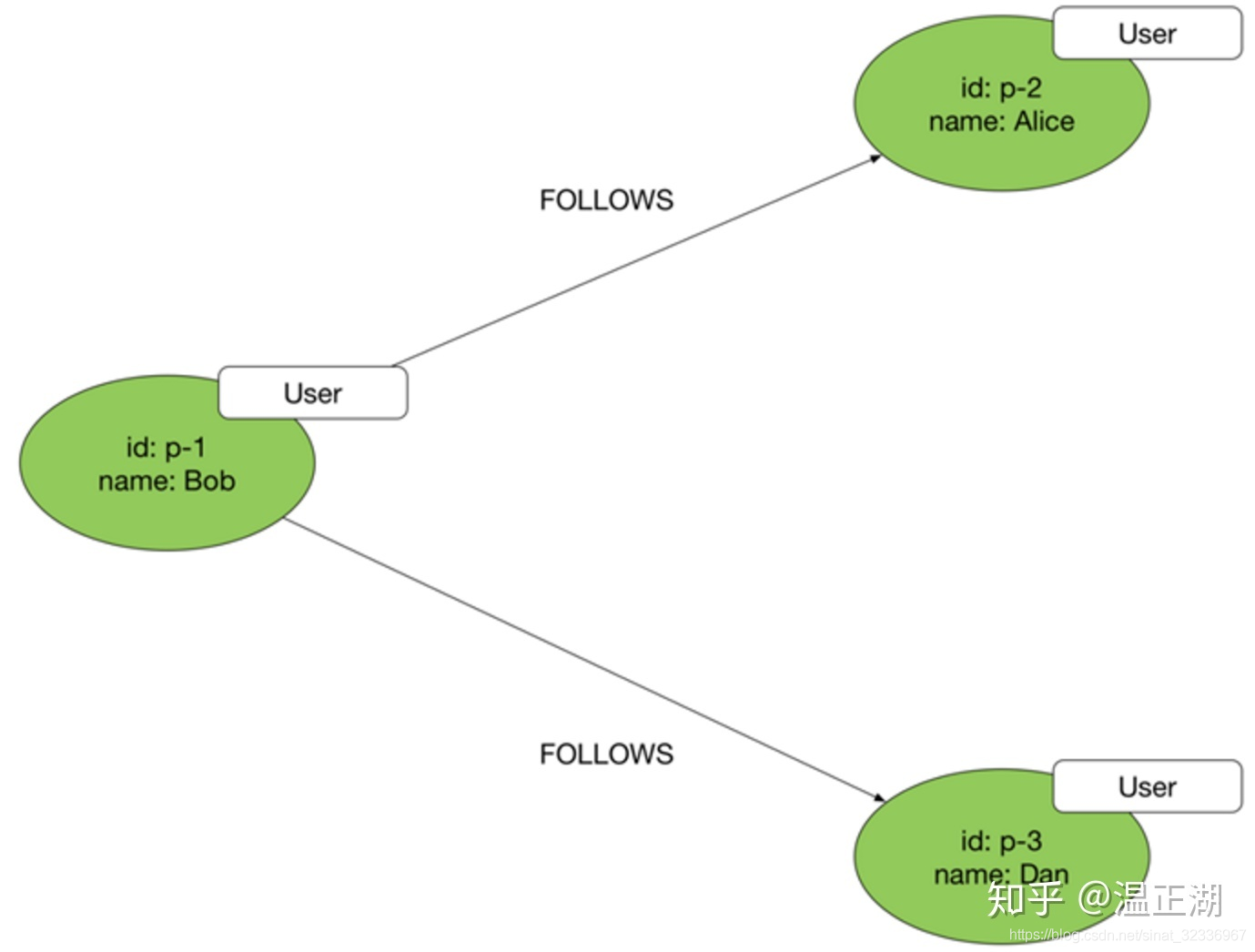
在上图中,绿色椭圆代表点,3个点的标签均为User;带箭头的直线表示有向边,箭头所指为边的终点,另一端为起点。边的类型为FOLLOWS。每个点都有2个属性,分别是id和name,类型均为String。
3. 图数据存储方式
将图数据存储存储到磁盘中的方法很多,常见的有按边切分和按点切分两种。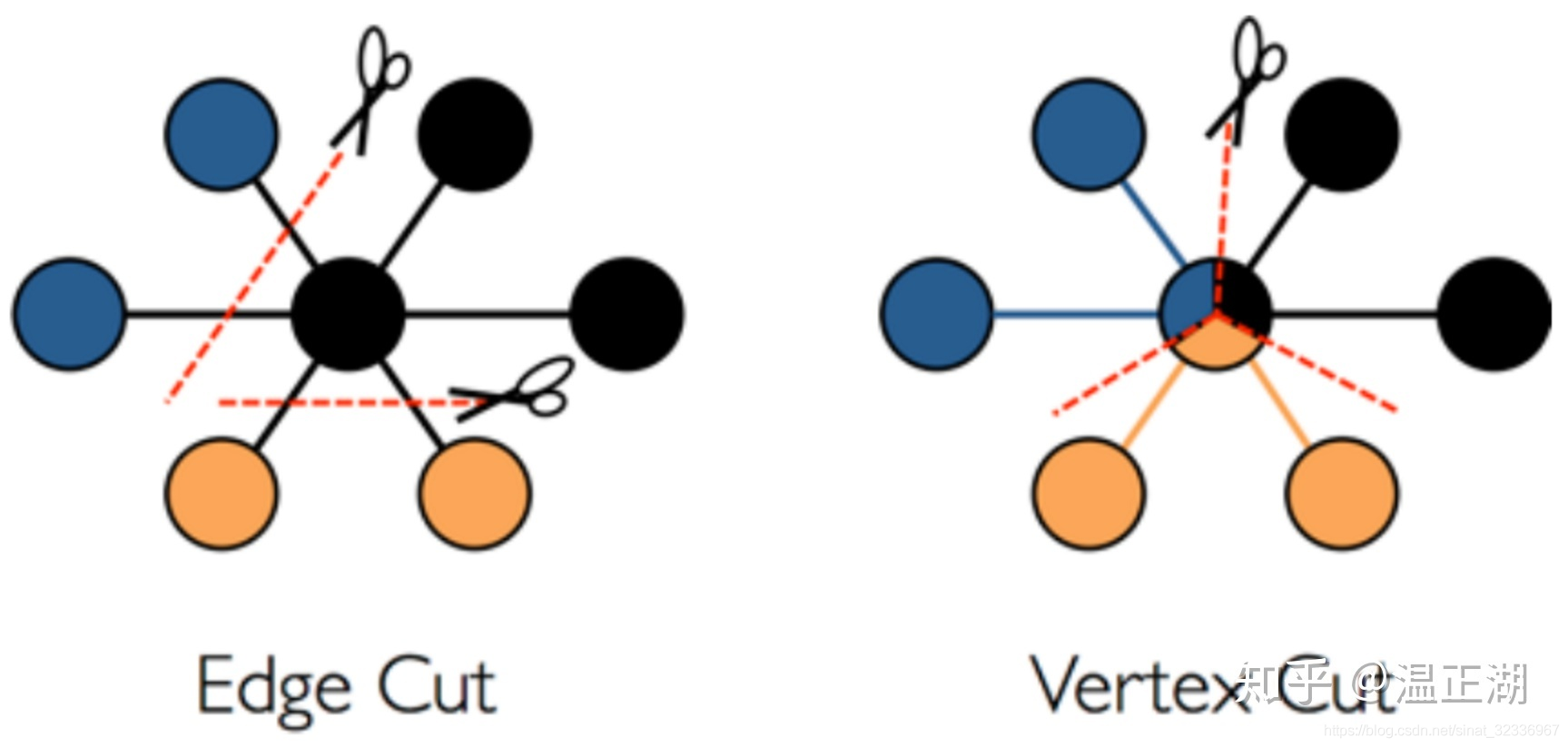
左图为按边切,顾名思义就是将边切成2段,分别跟起点和终点保存在一起,也就是说边的数据会保存2份。如下图中的JanusGraph数据为例。
将其按边切分,存入HBase中:
目前,大部分的在线图数据库(OLTP场景)均采用按边切的方式。除JanusGraph之外还包括Nebula Graph和HugeGraph等,只不过在具体的存储方案上有些差别。按点切分比较适用于离线图数据分析场景。
但本文聚焦的neo4j,却不是这么做的,他们称之为“原生图存储”(native graph storage)。下面就来重点分析下,所谓的原生图存储是怎么样的。首先贴一张neo4j数据目录下的文件列表: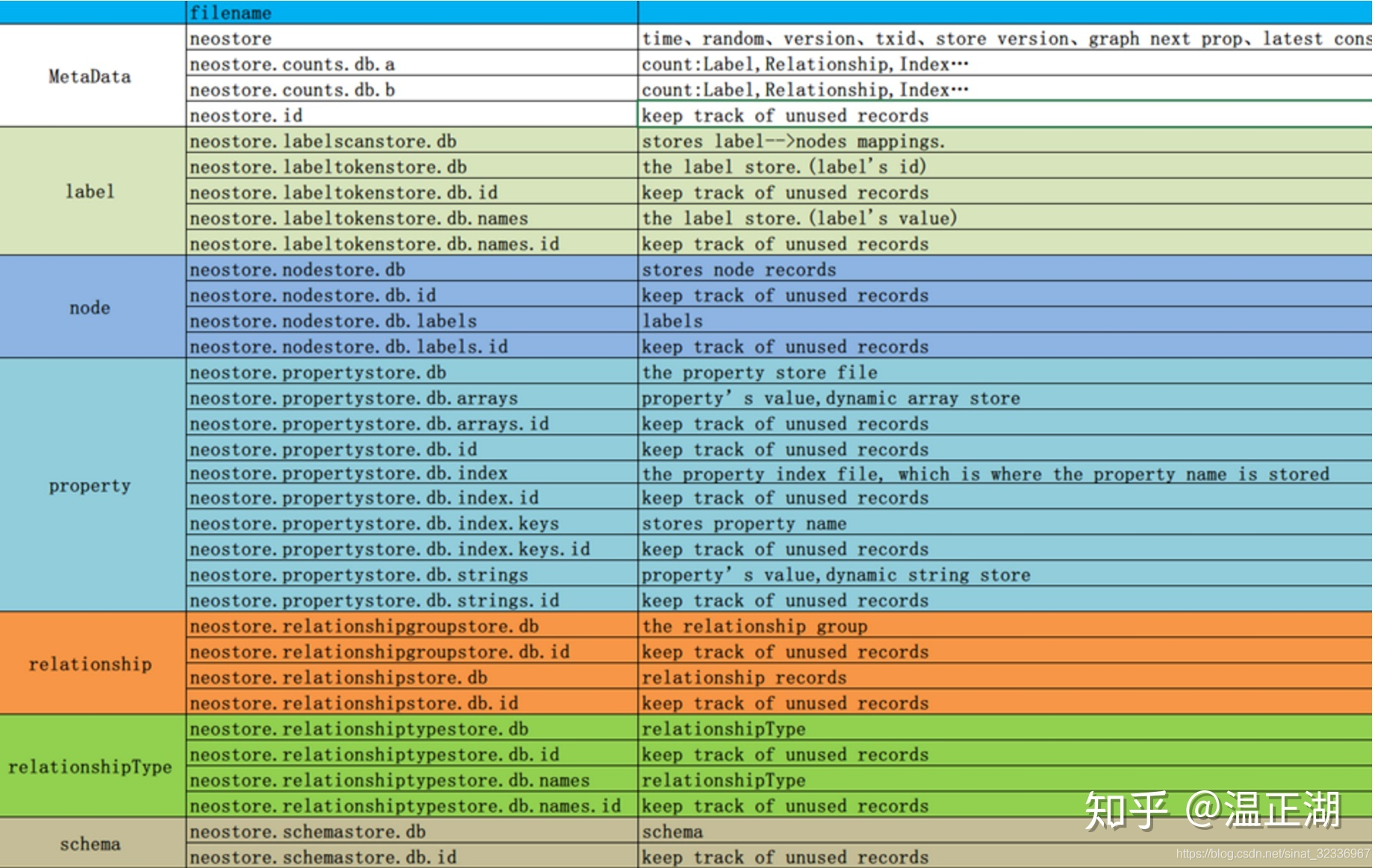
图中已经细分出了元数据、标签、点、属性、关系、关系类型和schema等不同类别的文件。文件众多,为了方便解释,我们仅分析点、关系和属性这三类。neo4j的点、关系和属性分别保存在neostore.nodestore.db、neostore.relationshipstore.db和neostore.propertystore.db文件中,看起来跟前述的按边切分,边跟点存储在一起的存储方式不同,而且属性也是单独的文件。 那么问题来了,将点、关系和属性全部打散分开存储,是基于什么考虑呢,这样性能好得了吗?这正是neo4j特殊之处。
4.neo4j存储的数据结构
在neo4j中,点、关系和属性等图的组成元素都是基于neo4j内部维护的ID进行访问的。而且可以认为这些元素的定长存储的。这样做的好处在于,知道了某点/关系/属性的ID,就能直接算出该ID在对应文件中的偏移位置,直接进行访问。也就是说在图的遍历过程中不需要基于索引扫描,直奔目的地即可。那么具体是怎么做到的呢?我们拿图最重要的骨架点和边来说明。在
neo4j-3.4.xx\community\kernel\src\main\java\org\neo4j\kernel\impl\store\format\standard
- 1
源码目录下我们能看到他们分别保存什么东西。
4.1 点
点结构为定长15B。
// in_use(byte)+next_rel_id(int)+next_prop_id(int)+labels(5)+extra(byte)
public static final int RECORD_SIZE = 15;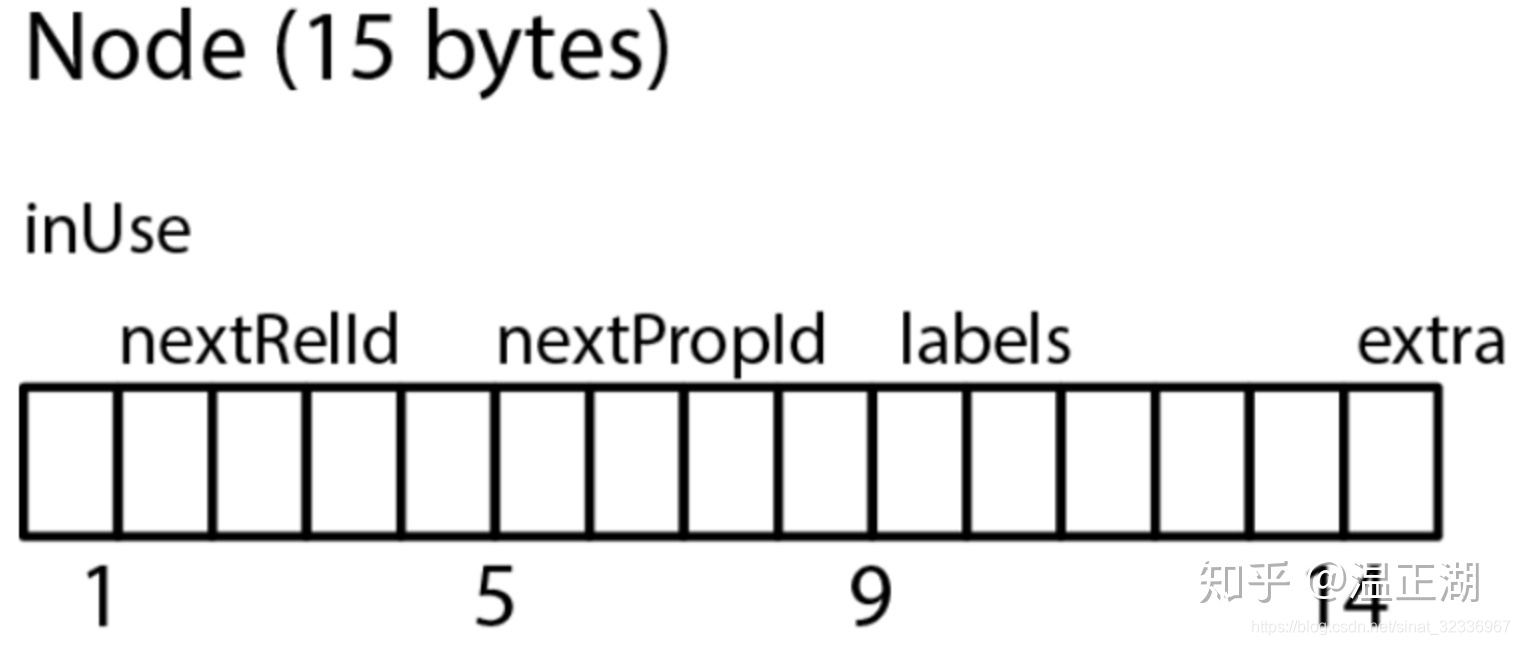
- 一个Byte存inUse+属性和关系id的高位信息
// [ , x] in use bit
// [ ,xxx ] higher bits for rel id
// [xxxx, ] higher bits for prop id
- 1
- 2
- 3
- 一个Int存nextRel
- 一个Int存nextProp
- 一个Int存lsbLabels
- 一个Byte存hsbLabels,跟4组成5个B的label
- 最后一个Byte保留字段extra,存记录是否为dense,dense的意思是是否为一个supernode
- 仅保存该点的第一个关系的ID,用第一个B的三个位表示关系ID的高位,额外用一个Int保存关系ID的低位。就是说neo4j中关系ID用35位表示;
- 仅保存该点的第一个属性的ID,用第一个B的四个位表示点最后4个位表示属性ID的高位,额外用一个Int保存属性的地位。就是说neo4j中属性ID用36位表示;
- 用最后一个B的一个位表示该点是否为超级点,即有很多边的节点;
4.2 关系/边
边结构为定长34B。相比点,边的结构复杂很多。
// directed|in_use(byte)+first_node(int)+second_node(int)+rel_type(int)+
// first_prev_rel_id(int)+first_next_rel_id+second_prev_rel_id(int)+
// second_next_rel_id(int)+next_prop_id(int)+first-in-chain-markers(1)
public static final int RECORD_SIZE = 34;
- 1
- 2
- 3
- 4

- 一个Byte,存该关系记录是否在使用中,以及关系的起点和下一个属性的高位信息,如下所示:
// [ , x] in use flag
// [ ,xxx ] first node high order bits
// [xxxx, ] next prop high order bits
- 1
- 2
- 3
- 一个Int存该关系的起点
- 一个Int存该关系的终点
- 一个Int存关系的类型,以及关系的终点、关系的起点的前一个和后一个关系、关系的终点的前一个和后一个关系的高位信息,如下所示:
// [ xxx, ][ , ][ , ][ , ] second node high order bits, 0x70000000
// [ ,xxx ][ , ][ , ][ , ] first prev rel high order bits, 0xE000000
// [ , x][xx , ][ , ][ , ] first next rel high order bits, 0x1C00000
// [ , ][ xx,x ][ , ][ , ] second prev rel high order bits, 0x380000
// [ , ][ , xxx][ , ][ , ] second next rel high order bits, 0x70000
// [ , ][ , ][xxxx,xxxx][xxxx,xxxx] type
- 1
- 2
- 3
- 4
- 5
- 6
- 一个Int存该关系的起点的前一个关系
- 一个Int存该关系的起点的下一个关系
- 一个Int存该关系的终点的前一个关系
- 一个Int存该关系的终点的下一个关系
- 一个Int存该关系的第一个属性
- 一个Byte存该关系是不是起点和终点的第一个关系,如下所示:
// [ , x] 1:st in start node chain, 0x1
// [ , x ] 1:st in end node chain, 0x2
- 1
- 2
- 边保存了其对应的起点和终点的ID,可以看到点的ID跟边一样,也是35位;这算是最基本的字段;
- 除此之外,还保持了起点对应的前一个和后一个关系,终点对应的前一个和后一个关系。这看起来就有点特别了,也就是说,对一个点的所有边的遍历,不是由点而是由其边掌控的;
- 由于起点和终点的关系都保存了,所以无论从起点开始遍历还是从终点开始都能够顺利完成遍历操作;
- 与点一样,边也仅保存自身的第一个属性;
- 最后,分别有个标识位来说明该边是否为起点和终点的第一条边。
4.3 属性
属性结构为定长41B。但与点和边不同的是,属性的长度本身是不固定的,一个属性结构不一定能够保存得下,因此还有可能外链到动态存储块上(DynamicRecord),动态存储块又可分为动态数组或动态字符串,动态存储块在此不做详细介绍。
public static final int RECORD_SIZE = 1 /*next and prev high bits*/
+ 4/*next*/
+ 4/*prev*/
+ DEFAULT_PAYLOAD_SIZE /*property blocks*/;
// = 41
- 1
- 2
- 3
- 4
- 5

- 一个Byte存辅助信息,即前后属性结构ID的高位信息
- 一个Int存前一个属性
- 一个Int存下一个属性
- 默认存4个属性块,每个块一个Long
这里进一步说下属性块的读取逻辑,首先会读取第一个属性块,判断是否被使用,若否,直接返回。若被使用,则获取本属性记录中用了多少个属性块(该信息存储在第一个属性块中)
PropertyType type = PropertyType.getPropertyTypeOrNull( block );//先判断块的类型
int numberOfBlocksUsed = type.calculateNumberOfBlocksUsed( block );
//然后调用该类型的重载函数获取占据多少个属性块
int additionalBlocks = numberOfBlocksUsed - 1;
while ( additionalBlocks-- > 0 )
{
record.addLoadedBlock( cursor.getLong() )
}
//最后,读取剩余被使用的属性块
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
不同于neo4j相关书籍(O`Reilly的图数据库、Neo4J权威指南等)中说的属性对象使用单链表连接,目前属性对象也是采用双链表;
属性结构是否在使用中不是像点和边一样位于第一个位,而是在其中的属性块中。
5. 图规模
从上一节我们知道,neo4j使用35位保存点和边的ID,用36位保存属性ID。
2^35 = 34,359,738,368
2^36 = 68,719,476,7362
- 1
- 2
也就是说neo4j最大能够保存34B的点和边,68B个属性。更直观说就是340亿的点和边,680亿个属性。所以,从规模上,neo4j图数据库能够容纳足够大的图。
6. 图的构建
下面先通过一个简单的例子来展示neo4j中的图:
图中包括2个标签为Person的点:Node 1和Node 2,Node 1有2个属性,分别为name:bob,age:25;Node 2有1个属性name:Alice。bob喜欢Alice,通过LIKES这条边来表示。由于2个点仅存一条边,所以LIKES边的起点和终点的下一条边指针为空。
如果上图看得懂,那么下面再用一个复杂的例子一步步说明如何将一个属性图在neo4j中解构存储起来。属性图如下: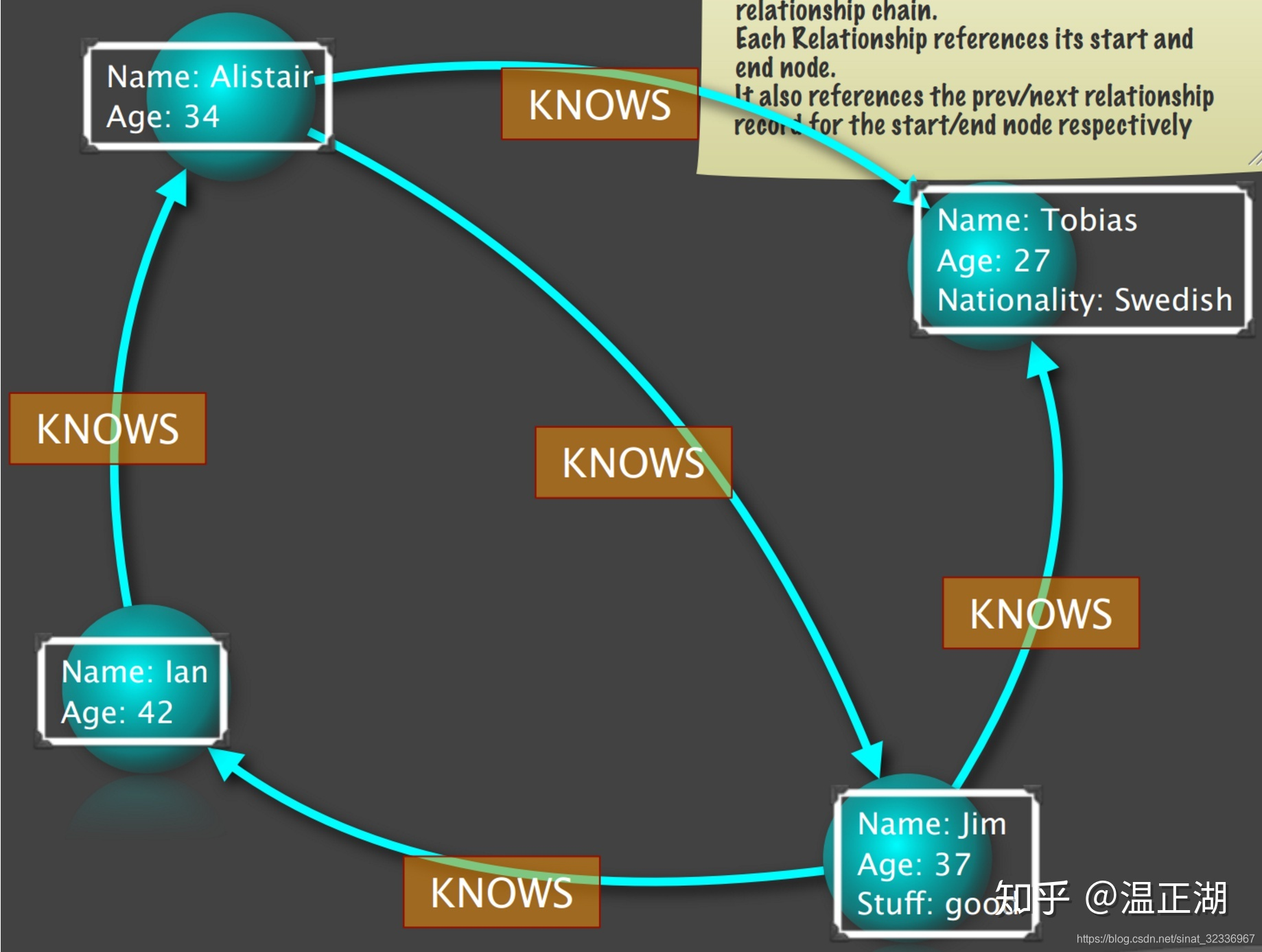
- 第一步,先把属性解构出来。图中的属性还是采用单链表,请忽略。
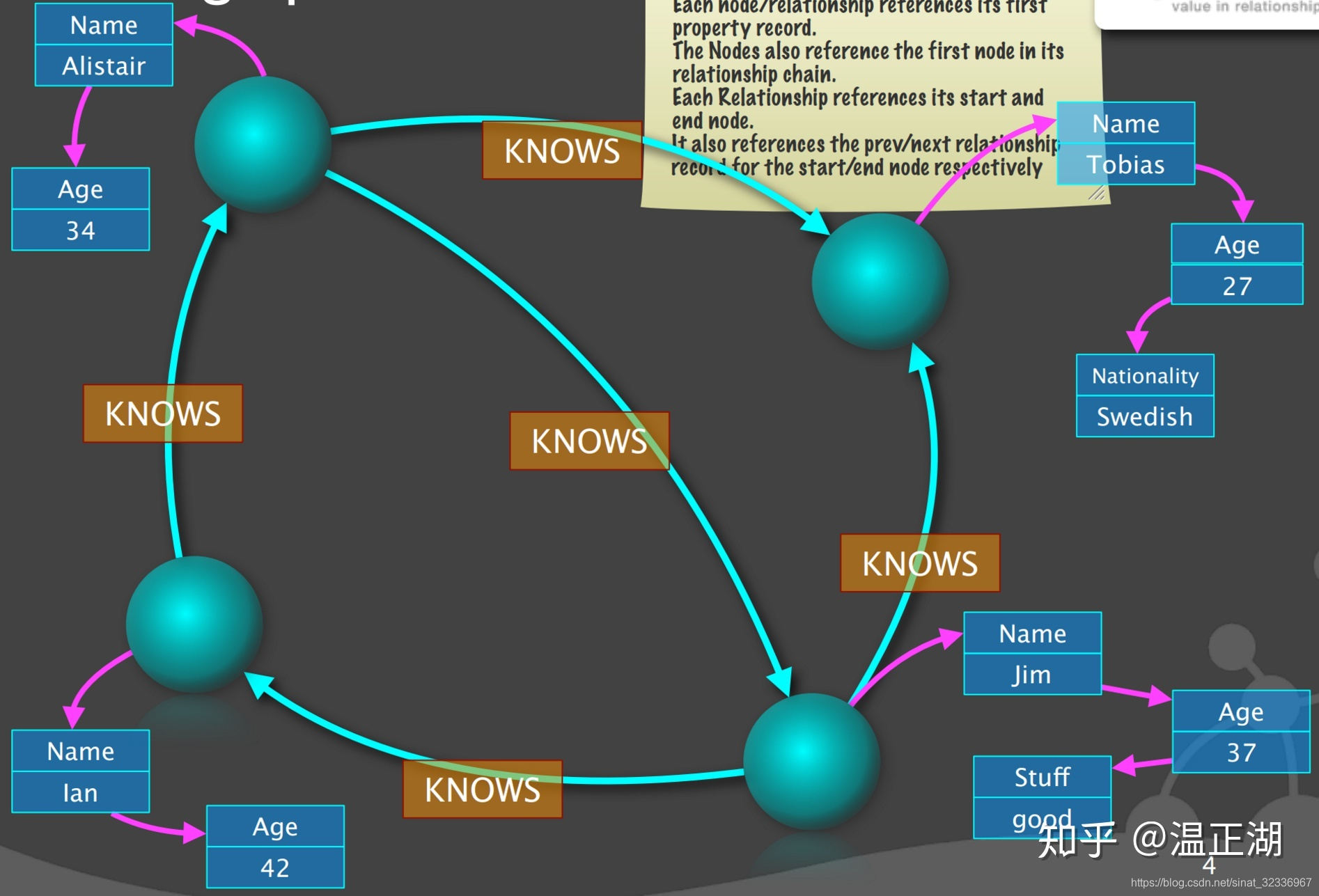
- 第二步,将点解构出来,建立点对象结构。每个点有个粉色箭头指向第一个属性,红色箭头指向第一条边;
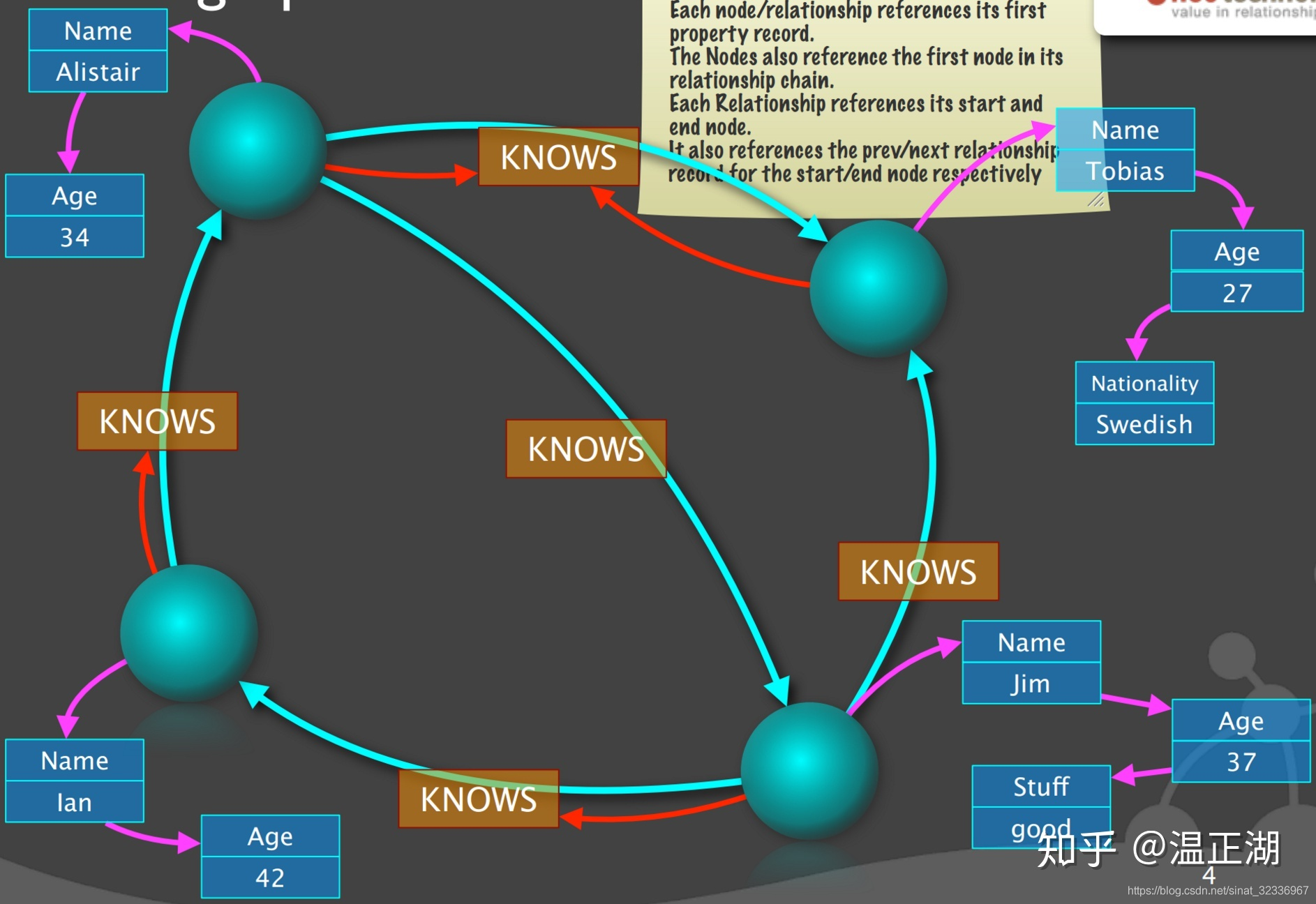
- 边最为复杂,分为多步进行构建;首先是边对象结构建立起来;一共有上下左右中五条边。SP和SN表示起点的前一条和下一条边,EP和EN表示终点的前一条和下一条边。
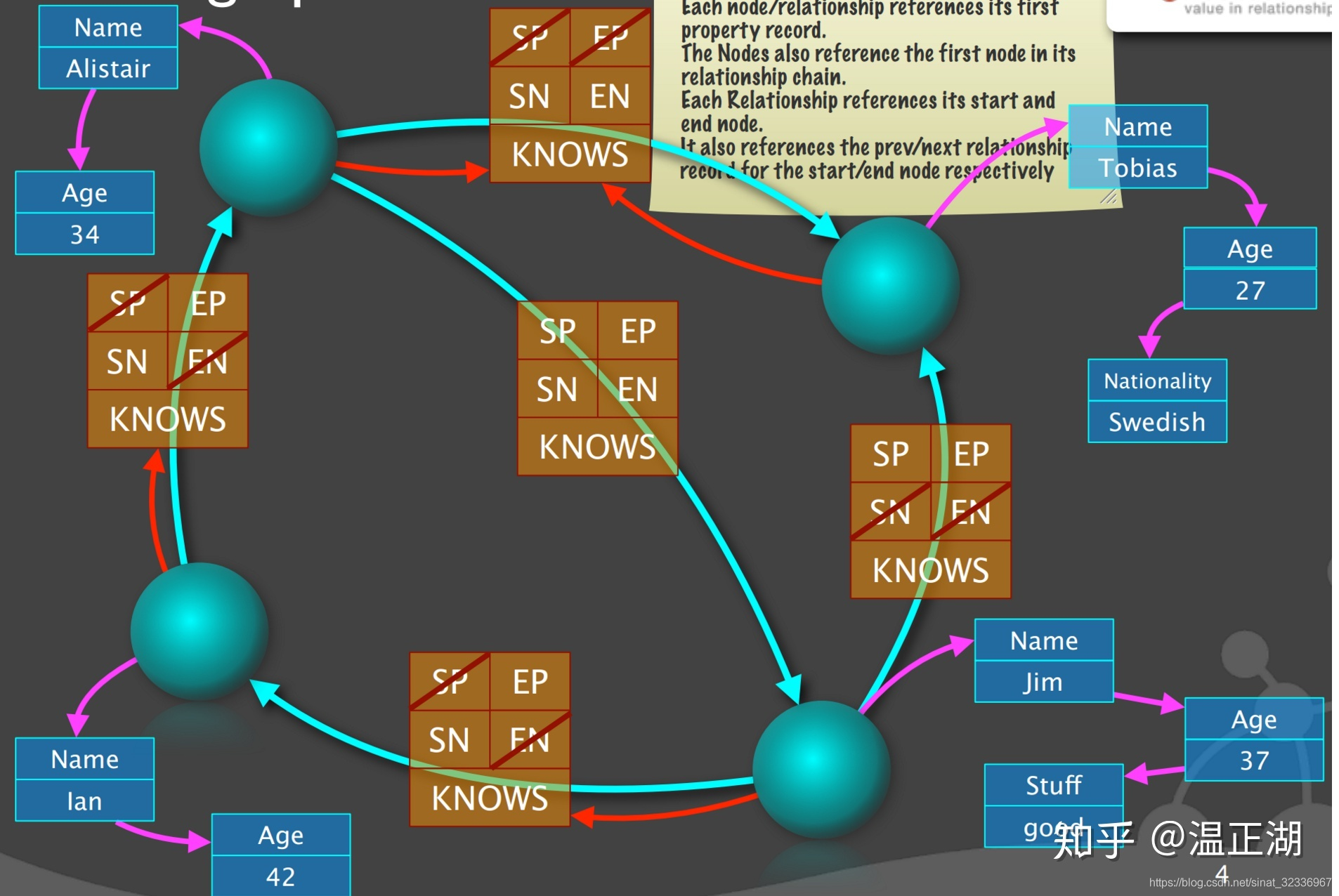
- 先看左边。它的起点为左下点,是第一条边,所以SP为空。其终点左上点有3条边,按照顺时针排序,该边是左上边的最后一条边,所以EN为空;
- 再看上边。它是起点为左上点,是第一条边,也是终点-右上点的第一条边,所以SP和EP均为空;
- 接着看右边。它是起点-右下点的最后一条边,也是重点-右上点的最后一条边,所以SN和EN均为空;
- 继续看下边。它是起点-右下点的第一条边,所以SP为空。也是终点-左下点的最后一条边,所以EN为空;
- 最后看中边。它是最普通的边,既不是起点-左上点,也不是终点-右下点的第一条边或最后一条边,所以SP、EP、SN和EN均不为空。
- 接下来继续完善边对象结构的起点和终点指向。绿色的线是边指向点的,实心圆表示起点,箭头表示终点,很好理解。

- 最后完成补全剩余的非空SP、EP、SN和EN。看起来很乱,但我们可以理出来。
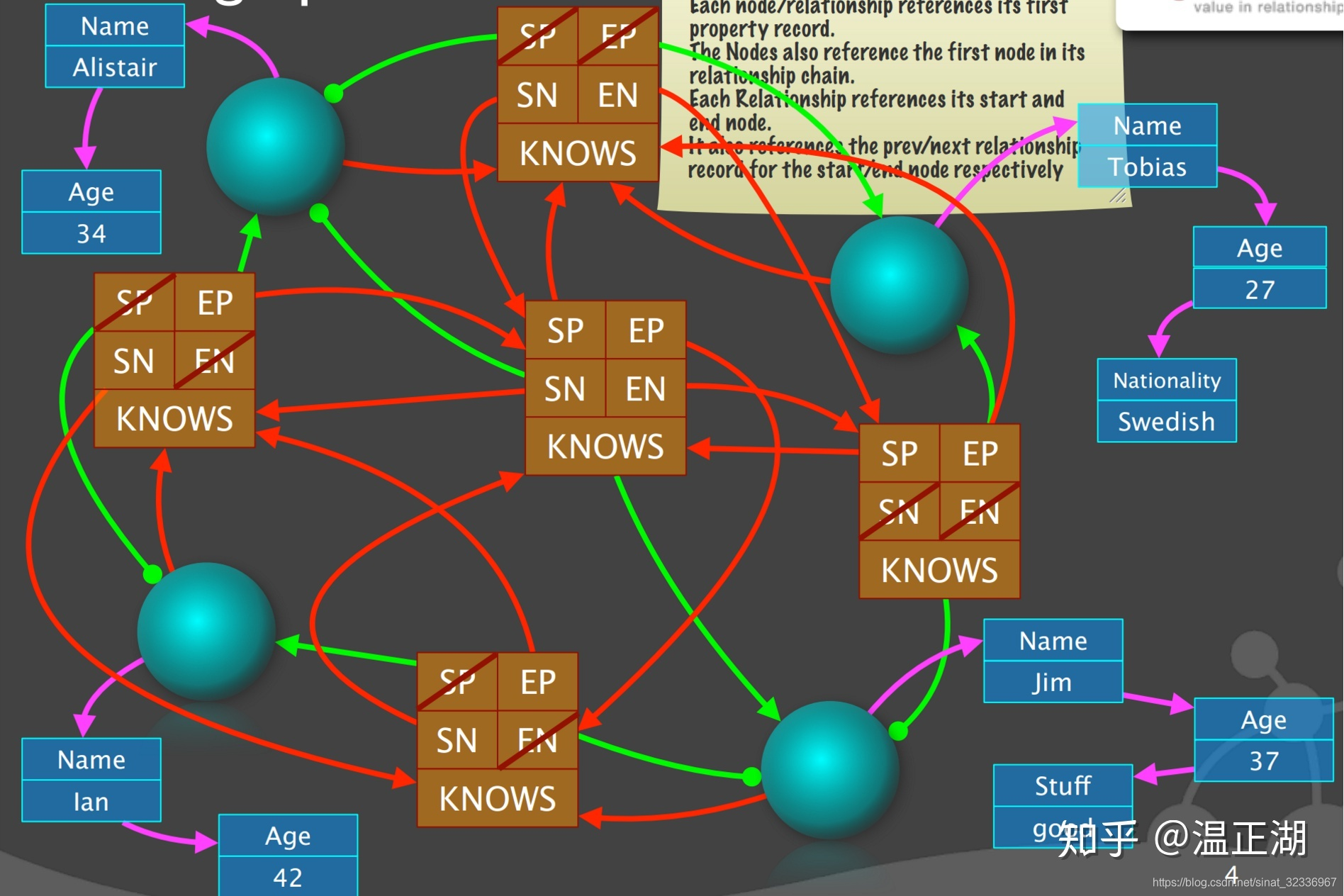
- 还是先看左边。它是起点-左下点的第一条边,左下点的第二条边为下边,即SN指向下边。它是终点-左上点的最后一条边(第三边),左上点的第二条边,也就是EP为中边;
- 再看上边。它是起点-左上点的第一条边,左上点的第二条边,也就是SN为中边。它的终点-右上点的第一条边,右上点的第二条边,也就是EN为右边;
- 接着看右边。它是右上和右下点的最后一条边。起点-右下点的前一条边,也就是SP为中边。终点-右上点的前一条边,也就是EP为上边;
- 继续看下边。它是起点-右下点的第一条边,起点的下一条边,也就是SN为中边。它是终点-左下点的最后一条边,终点的前一条边,也就是EP为左边;
- 最后,看看中边。4个ID均非空。它是起点-左上点的第二条边,起点第一条边,即SP为上边,起点第三条边,即SN为左边;它也是终点-右下点的第二条边,终点第一条边,即EP为下边,终点第三条边,即EN为右边。
至此,示例的属性图就在neo4j中构建完毕。
7. neo4j中图遍历
一个典型的图遍历操作,比如找一个人的3阶以内好友:需要从某个点出发,通过朋友关系来进行深度+广度查找。返回所有的结果。这里涉及到2个步骤,首先得找到这个点,然后才能进行图遍历。 遍历开始时的找点和找边操作,需要通过索引来加速查找。关系型数据库是这样,图数据库也是这样。neo4j支持多种索引类型,包括基于lucene和基于btree的。索引文件在neo4j数据目录的index子目录中。上文的文件列表未表示。
我们以上面的例子来简单描述如何进行图遍历。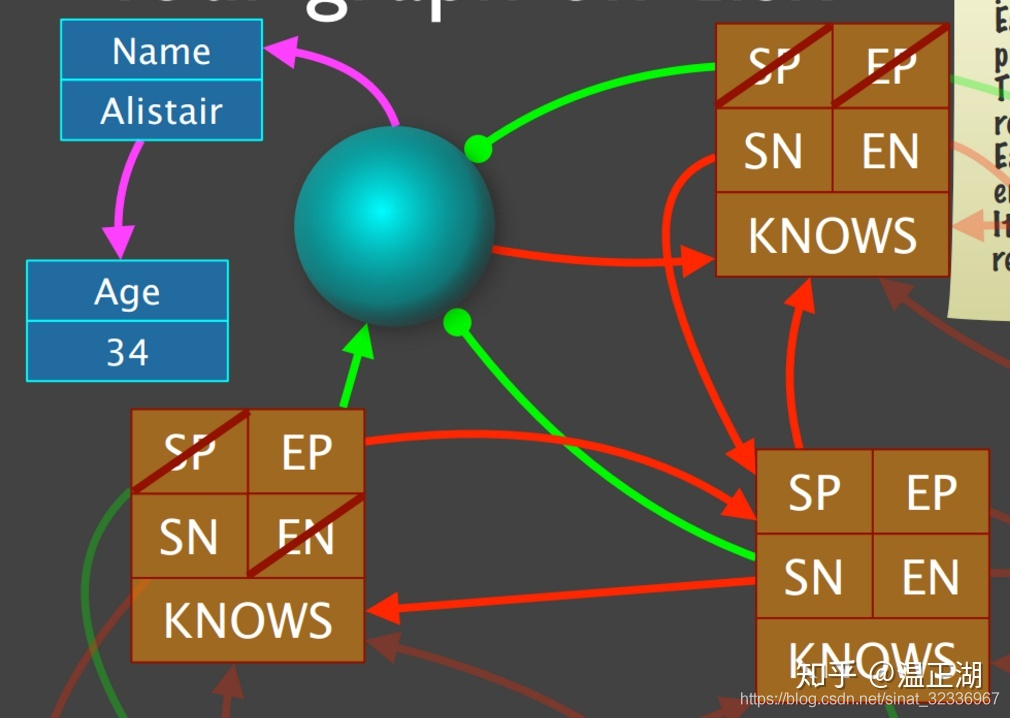
假设从Name为Alistair的节点出发,找出其所有认识的人(KNOWS):
match (n:Person{name:'Alistair'})-[r:KNOWS]->(m:Person) return n.name;
- 1
- 首先基于索引找到该点ID。然后通过该ID计算点的存储偏移位置ID*15。从neostore.nodestore.db文件中读取NodeRecord对象;
- 从节点对象的nextRelId获取第一条边,即上边的ID,计算其存储偏移位置nextRelId*34,到neostore.relationshipstore.db文件读取RelationshipRecord对象;
- 从边的对象中获取relationshipType,判断是否为KNOWS类型;若是,进一步判断secondNode是否为其他节点,若是则保存该节点ID;
- 继续通过上边的SN字段获取下一条边,即中边的ID,重复2和3;
- 对于左上点来说,上边和中边是出边,左边是入边,所以,上边和中边指向的是认识的人。
- 获取两条边终点ID对应的节点的Name,返回客户端;
8. 免索引邻接
向上面这种,直接在点和边中保存相应点/边/属性的物理地址,直接进行寻址的遍历方法,免去了基于索引进行扫描查找的开销,实现从O(logn)到O(1)的性能提升。这种图处理方式就叫做免索引邻接。它不会随着图数据量的增加影响。仅跟遍历所涉及的数据集有关。
9. 总结
本文主要从neo4j的点、边和属性出发,介绍了各自在磁盘上的存储方式,并分析了如何将属性图构建成neo4j这种存储格式。最后通过案例说明什么是免索引邻接。由于篇幅有限,本文未就supernode、大字符串或数组类型的属性的优化和存储方式进行分析。感兴趣的同学可以私下交流。
neo4j存储数据-图数据库的更多相关文章
- neo4j(图数据库)是什么?
不多说,直接上干货! 作为一款强健的,可伸缩的高性能数据库,Neo4j最适合完整的企业部署或者用于一个轻量级项目中完整服务器的一个子集存在. 它包括如下几个显著特点: 完整的ACID支持 高可用性 轻 ...
- neo4j 图数据库安装及介绍
neo4j 图数据库安装及介绍 一.neo4j图数据库介绍 图数据库,顾名思义就是利用了"图的数据结构来作为数据存储逻辑体现的一种数据库",所以要想学好图数据库当然需要了解一些关于 ...
- 图数据库Neo4j
官网下载:https://neo4j.com/download/ 图数据库Neo4j入门:https://blog.csdn.net/gobitan/article/details/68929118 ...
- 高性能内存图数据库RedisGraph(一)
作为一种简单.通用的数据结构,图可以表示数据对象之间的复杂关系.生物信息学.计算机网络和社交媒体等领域中产生的大量数据,往往是相互连接.关系复杂且低结构化的,这类数据对传统数据库而言十分棘手,一个简单 ...
- 使用neo4j图数据库的import工具导入数据 -方法和注意事项
背景 最近我在尝试存储知识图谱的过程中,接触到了Neo4j图数据库,这里我摘取了一段Neo4j的简介: Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中.它是一个嵌 ...
- NEO4J 图数据库使用APOC数据导入
Neo4j 数据导入 一.安装与部署 直接在官网下载安装包安装,解压即可. 二.下载相应的jar包 apoc 包下载链接: https://github.com/neo4j-contrib/ne ...
- Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘.NoSQL数据库的兴起,很好地解决了海 ...
- Neo4j图数据库
01. 图数据库 图数据库是专门存储和检索大量信息网络的存储引擎.它可以有效地将数据存储为节点和关系,并允许高性能检索和查询这些结构.属性可以添加到节点和关系.节点可以用零个或多个标签标注,关系总是定 ...
- 开源软件:NoSql数据库 - 图数据库 Neo4j
转载自原文地址:http://www.cnblogs.com/loveis715/p/5277051.html 最近我在用图形数据库来完成对一个初创项目的支持.在使用过程中觉得这种图形数据库实际上挺有 ...
- Ubuntu16.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu LTS \n \l r ...
随机推荐
- Cursor使用
Cursor是一款AI 代码编辑器,官网地址为https://www.cursor.com/,直接在官网下载安装即可,基于VS Code二次开发而来,之所以没有采用插件方式,在官方网站上给出的答案是某 ...
- Java核心知识体系10-线程管理
Java系列 Java核心知识体系1:泛型机制详解 Java核心知识体系2:注解机制详解 Java核心知识体系3:异常机制详解 Java核心知识体系4:AOP原理和切面应用 Java核心知识体系5:反 ...
- 网站统计代码v1.0
var m = {}; var p ={}; var gifUrl = 'http://hm.iwgame.test/v.gif'; (function() { //参数组合类 m = { ck : ...
- nodejs版本管理工具之n
转载: https://juejin.cn/post/7065534944101007391 Node.js 对于现在的前端开发人员来说是不可或缺的需要掌握的技能,但我们在使用时避免不了会需要切换不同 ...
- 用OpenResty搭建高性能服务端
相关链接:https://github.com/openresty/lua-nginx-module OpenResty 简介 OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web ...
- Blazor 组件库 BootstrapBlazor 中AutoComplete组件介绍
AutoComplete组件介绍 AutoComplete组件和文本框基本上样子是一样的,只不过AutoComplete组件还带有一个下拉列表,可以从中选择对应的内容. 其同样继承自Bootstrap ...
- Node.js Express 框架(2)
1.读取文件并返回给客户端 res.sendFile(path):读取文件并返回给客户端,适合静态页面 app.get("/",function(req,res){ res.sen ...
- Conda + JuiceFS :增强 AI 开发环境共享能力
Conda 是当前 AI 应用开发领域中非常流行的环境和包管理系统,因其能够简单便捷地创建与系统资源相隔离的虚拟环境广受欢迎. Conda 支持在不同的操作系统上重建相同的工作环境,但在环境共享复用方 ...
- jsp移动端和pc端页面判断及切换
function goPAGE() { if ((navigator.userAgent.match(/(phone|pad|pod|iPhone|iPod|ios|iPad|Android|Mobi ...
- 推荐一款轻量级且强大的 Elasticsearch GUI : elasticvue
推荐一款轻量级且强大的 Elasticsearch GUI : elasticvue 很多同学都是用过 Elasticsearch 的 GUI 工具 Kibana ,但 Kibana 相对比较重,这篇 ...