Antlr4 语法解析器(下)
Antlr4 的两种AST遍历方式:Visitor方式 和 Listener方式。
Antlr4规则文法:
- 注释:和Java的注释完全一致,也可参考C的注释,只是增加了JavaDoc类型的注释;
- 标志符:参考Java或者C的标志符命名规范,针对Lexer 部分的 Token 名的定义,采用全大写字母的形式,对于parser rule命名,推荐首字母小写的驼峰命名;
- 不区分字符和字符串,都是用单引号引起来的,同时,虽然Antlr g4支持 Unicode编码(即支持中文编码),但是建议大家尽量还有英文;
- Action,行为,主要有@header 和@members,用来定义一些需要生成到目标代码中的行为,例如,可以通过@header设置生成的代码的package信息,@members可以定义额外的一些变量到Antlr4语法文件中;
- Antlr4语法中,支持的关键字有:import, fragment, lexer, parser, grammar, returns, locals, throws, catch, finally, mode, options, tokens
基于IDEA调试Antlr4语法规则(文法可视化)
基于IDEA调试Antlr4语法一般步骤:
1) 创建一个调试工程,并创建一个g4文件
这里,我自己测试用Java开发,所以创建的是一个Maven工程,g4文件放在了src/main/resources 目录下,取名 Test.g4
2)写一个简单的语法结构
这里我们参考写一个加减乘除操作的表达式,然后在赋值操作对应的Rule上右键,可选择测试:
grammar Test;
@header {
package com.chaplinthink.antlr;
}
stmt : expr;
expr : expr NUL expr # Mul
| expr ADD expr # Add
| expr DIV expr # Div
| expr MIN expr # Min
| INT # Int
;
NUL : '*';
ADD : '+';
DIV : '/';
MIN : '-';
INT : Digit+;
Digit : [0-9];
WS : [ \t\u000C\r\n]+ -> skip;
SHEBANG : '#' '!' ~('\n'|'\r')* -> channel(HIDDEN);
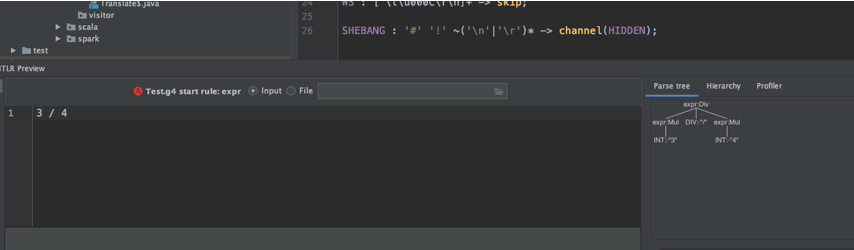
看我们 3/ 4 是可以识别出来的 语法中 channel(HIDDEN) (代表隐藏通道) 中的 Token,不会被语法解析阶段处理,但是可以通过Token遍历获取到。
Antlr4生成并遍历AST
1. 通过命令行如上篇文章
java -jar antlr-4.7.2--complete.jar -Dlanguage=Python3 -visitor Test.g4
这样就可以生成Python3 target的源码,如果不希望生成Listener,可以添加参数 -no-listener
2. Maven Antlr4插件自动生成(针对Java工程,也可以用于Gradle)
此处使用第一种方式
访问者模式遍历Antlr4语法树
java -jar /usr/local/lib/antlr-4.7.2-complete.jar -visitor -no-listener Test.g4
生成源码文件:

通过代码展示访问者模式在Antlr4中使用:
public class App {
public static void main(String[] args) {
CharStream input = CharStreams.fromString("12*2+12");
TestLexer lexer = new TestLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
TestParser parser = new TestParser(tokens);
TestParser.ExprContext tree = parser.expr();
TestVisitor tv = new TestVisitor();
tv.visit(tree);
}
static class TestVisitor extends TestBaseVisitor<Void> {
@Override
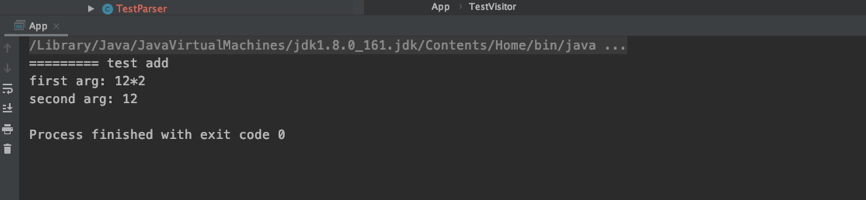
public Void visitAdd(TestParser.AddContext ctx) {
System.out.println("========= test add");
System.out.println("first arg: " + ctx.expr(0).getText());
System.out.println("second arg: " + ctx.expr(1).getText());
return super.visitAdd(ctx);
}
}
}
一般来说,面向程序静态分析时,都是使用访问者模式的,很少使用监听器模式(无法主动控制遍历AST的顺序,不方便在不同节点遍历之间传递数据)
Antlr4词法解析和语法解析
如前面的语法定义,分为Lexer和Parser,实际上表示了两个不同的阶段:
- 词法分析阶段:对应于Lexer定义的词法规则,解析结果为一个一个的Token;
- 解析阶段:根据词法,构造出来一棵解析树或者语法树。
如下图所示:

Spark & Antlr4
Spark SQL /DataFrame 执行过程是这样子的:
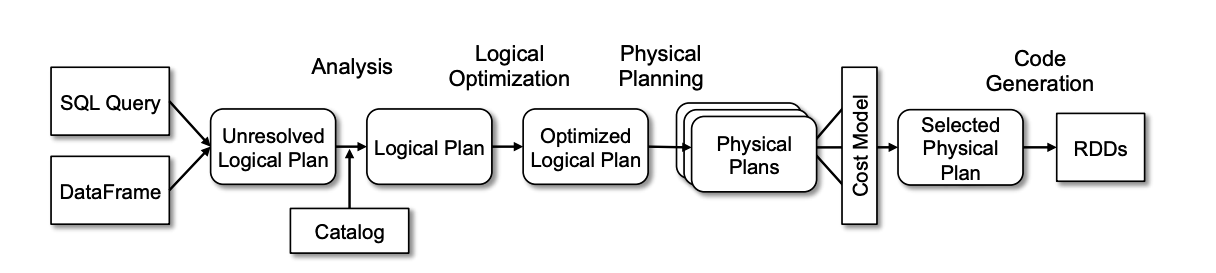
我们看下在 Spark SQL 中是如何使用Antlr4的.
当你调用spark.sql的时候, 会调用下面的方法:
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
parse sql阶段主要是parsePlan(sqlText)这一部分。而这里又会辗转去org.apache.spark.sql.catalyst.parser.AbstractSqlParser调用parse方法:
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
catch {
case e: ParseCancellationException =>
// if we fail, parse with LL mode
tokenStream.seek(0) // rewind input stream
parser.reset()
// Try Again.
parser.getInterpreter.setPredictionMode(PredictionMode.LL)
toResult(parser)
}
}
catch {
case e: ParseException if e.command.isDefined =>
throw e
case e: ParseException =>
throw e.withCommand(command)
case e: AnalysisException =>
val position = Origin(e.line, e.startPosition)
throw new ParseException(Option(command), e.message, position, position)
}
}
这里SqlBaseLexer 、SqlBaseParser都是Antlr4的东西,包括最后的toResult(parser)也是调用访问者模式的类去遍历语法树来生成Logical Plan
spark提供了一个.g4文件,编译的时候会使用Antlr根据这个.g4生成对应的词法分析类和语法分析类,同时还使用了访问者模式,用以构建Logical Plan(语法树)。
访问者模式简单说就是会去遍历生成的语法树(针对语法树中每个节点生成一个visit方法),以及返回相应的值。我们接下来看看一条简单的select语句生成的树是什么样子:
这个sqlBase.g4文件我们也可以直接复制出来,用antlr相关工具就可以生成一个生成一个解析SQL的图
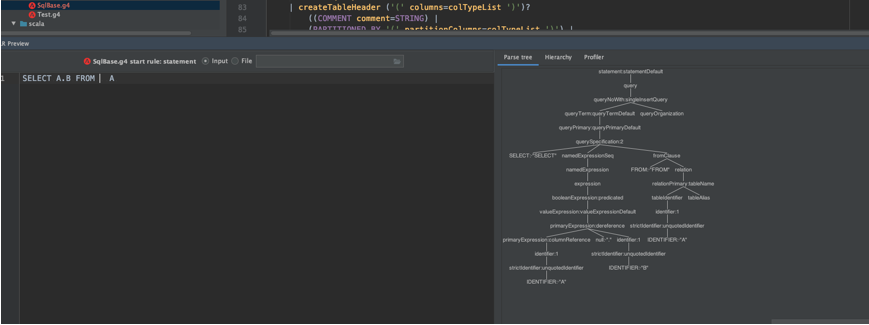
将SELECT A.B FROM A,转换成一棵语法树。我们可以看到这颗语法树非常复杂,这是因为SQL解析中,要适配这种SELECT语句之外,还有很多其他类型的语句,比如INSERT,ALERT等等。Spark SQL这个模块的最终目标,就是将这样的一棵语法树转换成一个可执行的Dataframe(RDD)
Spark使用Antlr4的访问者模式,生成Logical Plan. 我们继承SqlBaseBaseVisitor,里面提供了默认的访问各个节点的触发方法。我们可以通过继承这个类,重写对应节点的visit方法,实现自己的访问逻辑,Spark SQL中这个继承的类就是org.apache.spark.sql.catalyst.parser.AstBuilder
通过观察这棵树,我们可以发现针对我们的SELECT语句,比较重要的一个节点,是querySpecification节点,实际上,在AstBuilder类中,visitQuerySpecification也是比较重要的一个方法(访问对应节点时触发),正是在这个方法中生成主要的Logical Plan的。
以下是querySpecification在Spark SQL 中实现的 代码:
/**
* Create a logical plan using a query specification.
*/
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
先判断是否有FROM子语句,有的话会去生成对应的Logical Plan,再调用withQuerySpecification()方法,
withQuerySpecification是逻辑计划核心方法, 根据不同的子语句生成不同的Logical Plan.
参考:
[1] Spark SQL: Relational Data Processing in Spark: https://amplab.cs.berkeley.edu/wp-content/uploads/2015/03/SparkSQLSigmod2015.pdf
[2] Antlr4简明使用教程: https://bbs.huaweicloud.com/blogs/226877
Antlr4 语法解析器(下)的更多相关文章
- Anrlr4 生成C++版本的语法解析器
一. 写在前面 我最早是在2005年,首次在实际开发中实现语法解析器,当时调研了Yacc&Lex,觉得风格不是太好,关键当时yacc对多线程也支持的不太好,接着就又学习了Bison&F ...
- 在.NET Core中使用Irony实现自己的查询语言语法解析器
在之前<在ASP.NET Core中使用Apworks快速开发数据服务>一文的评论部分,.NET大神张善友为我提了个建议,可以使用Compile As a Service的Roslyn为语 ...
- 用java实现编译器-算术表达式及其语法解析器的实现
大家在参考本节时,请先阅读以下博文,进行预热: http://blog.csdn.net/tyler_download/article/details/50708807 本节代码下载地址: http: ...
- Boost学习之语法解析器--Spirit
Boost.Spirit能使我们轻松地编写出一个简单脚本的语法解析器,它巧妙利用了元编程并重载了大量的C++操作符使得我们能够在C++里直接使用类似EBNF的语法构造出一个完整的语法解析器(同时也把C ...
- 使用 java 实现一个简单的 markdown 语法解析器
1. 什么是 markdown Markdown 是一种轻量级的「标记语言」,它的优点很多,目前也被越来越多的写作爱好者,撰稿者广泛使用.看到这里请不要被「标记」.「语言」所迷惑,Markdown 的 ...
- 语法解析器续:case..when..语法解析计算
之前写过一篇博客,是关于如何解析类似sql之类的解析器实现参考:https://www.cnblogs.com/yougewe/p/13774289.html 之前的解析器,更多的是是做语言的翻译转换 ...
- 手写token解析器、语法解析器、LLVM IR生成器(GO语言)
最近开始尝试用go写点东西,正好在看LLVM的资料,就写了点相关的内容 - 前端解析器+中间代码生成(本地代码的汇编.执行则靠LLVM工具链完成) https://github.com/daibinh ...
- 【读书笔记】-【编程语言的实现模式】-【LL(1)递归下降的语法解析器】
形如:[a,b,c] [a,[b,cd],f] 为 嵌套列表 其ANTLR文法表示: list :'[' elements ']'; // 匹配方括号 elements : elements (',' ...
- 使用golang+antlr4构建一个自己的语言解析器(一)
Antlr4 简介 ANTLR(全名:ANother Tool for Language Recognition)是基于LL(*)算法实现的语法解析器生成器(parser generator),用Ja ...
- 自己动手实现一个简单的JSON解析器
1. 背景 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.相对于另一种数据交换格式 XML,JSON 有着诸多优点.比如易读性更好,占用空间更少等.在 ...
随机推荐
- Git删除当前分支下的所有历史版本与log
- 「TCP/UDP」一个端口号可以同时被两个进程绑定吗?
一.1个端口号可以同时被两个进程绑定吗? 根据端口号的绑定我们分以下几种情况来讨论: 2个进程分别建立TCP server,使用同一个端口号8888 2个进程分别建立UDP server,使用同一个端 ...
- JS脚本批量处理TS数据类型
在TS开发中,经常会遇到后台数据字段比较多的情况,这时候需要一个个复制字段然后给他手动配置数据类型来完成我们的TS类型定义,相当麻烦.有什么快速的方法呢,我就目前遇到的两种情况分别写了JS脚本来处理后 ...
- C# 导出Excel NPOI 修改指定单元格的样式 或者行样式
参考文章:原文链接:https://blog.csdn.net/chensirbbk/article/details/52189985 #region 2.NPOI读取Excel 验证Excel数据的 ...
- 【Mac + Python + Selenium】之获取验证码图片code并进行登录
自己新总结了一篇文章,对代码进行了优化,另外附加了静态图片提取文字方法,两篇文章可以结合着看:<[Python]Selenium自动化测试之动态识别验证码图片方法(附静态图片文字获取)> ...
- Docker网络中篇-docker网络的四种类型
通过上一篇学习,我们对docker网络有了初步的了解.本篇,咱们就来实战docker网络. docker网络实战 实战docker网络,我们将从以下几个案例来讲解 1:birdge是什么? 2:hos ...
- chrome 被hao123 劫持处理
打开chrome,就进入baidu.com/xxx,烦人,浏览器被劫持了XXXX 查注册表hao123,删除找到的 进入chrome设置,修改主页新标签页 装杀毒软件,查杀病毒 修改chrome名 等 ...
- 小tips:xml文件转为html表格展示示例
books.xml文件格式如下: <?xml version="1.0" encoding="UTF-8"?> <xbrl xmlns=&qu ...
- RxJS 系列 – 大杂烩
前言 RxJS 有太多方法了, 想看完整的可以去看 REFERENCE – API List, 这篇介绍一些非 operator 的常用方法. NEVER NEVER.subscribe({ comp ...
- BOM – Window.matchMedia
参考 Youtube – Detecting Screen Size and OS Dark Mode with matchMedia() - JavaScript Tutorial 介绍 CSS 有 ...